
生成式人工智能系统改变了人类与技术的互动方式,提供了突破性的自然语言处理和内容生成功能。然而,这些系统也存在重大风险,特别是在生成不安全或违反政策的内容时。应对这一挑战需要先进的审核工具,以确保输出内容安全并符合道德准则。此类工具必须有效且高效,尤其是在资源受限的硬件(如移动设备)上部署时。
部署安全调节模型的一个持续挑战是其大小和计算要求。大型语言模型 (LLM) 虽然功能强大且准确,但需要大量内存和处理能力,因此不适合硬件功能有限的设备。部署这些模型可能会导致运行时瓶颈或 DRAM 受限的移动设备出现故障,从而严重限制其可用性。为了解决这个问题,研究人员一直致力于在不牺牲性能的情况下压缩 LLM。
现有的模型压缩方法(包括剪枝和量化)在减小模型大小和提高效率方面发挥了重要作用。剪枝涉及选择性地删除不太重要的模型参数,而量化则将模型权重的精度降低为较低位格式。尽管取得了这些进步,但许多解决方案仍需要帮助来有效平衡大小、计算需求和安全性能,尤其是在部署在边缘设备上时。
Meta 的研究人员推出了Llama Guard 3-1B-INT4,这是一种旨在应对这些挑战的安全调节模型。该模型在 Meta Connect 2024 期间发布,只有 440MB,比其前身 Llama Guard 3-1B 小七倍。这是通过先进的压缩技术实现的,例如解码器块修剪、神经元级修剪和量化感知训练。研究人员还从更大的 Llama Guard 3-8B 模型中进行了提炼,以恢复压缩过程中丢失的质量。值得注意的是,该模型在标准 Android 移动 CPU 上实现了每秒至少 30 个令牌的吞吐量,第一个令牌的时间不到 2.5 秒。
几种关键方法论支撑了 Llama Guard 3-1B-INT4 的技术进步。修剪技术将模型的解码器块从 16 个减少到 12 个,将 MLP 隐藏维度从 8192 个减少到 6400 个,参数数量从 15 亿减少到 11 亿。量化通过将权重的精度降低到 INT4 并将激活降低到 INT8 来进一步压缩模型,与 16 位基线相比,其大小减少了四倍。此外,非嵌入层修剪通过仅关注 20 个必要的标记来减少输出层的大小,同时保持与现有接口的兼容性。这些优化确保了模型在移动设备上的可用性,而不会影响其安全标准。

Llama Guard 3-1B-INT4 的性能凸显了其有效性。它在英语内容的 F1 得分为 0.904,优于得分为 0.899 的大型同类模型 Llama Guard 3-1B。在多语言能力方面,该模型在八种测试的非英语语言中的五种语言(包括法语、西班牙语和德语)中的表现与大型模型相当或更好。与在零样本设置下测试的 GPT-4 相比,Llama Guard 3-1B-INT4 在七种语言中表现出卓越的安全审核分数。其减小的尺寸和优化的性能使其成为移动部署的实用解决方案,并且已在 Moto-Razor 手机上成功展示。
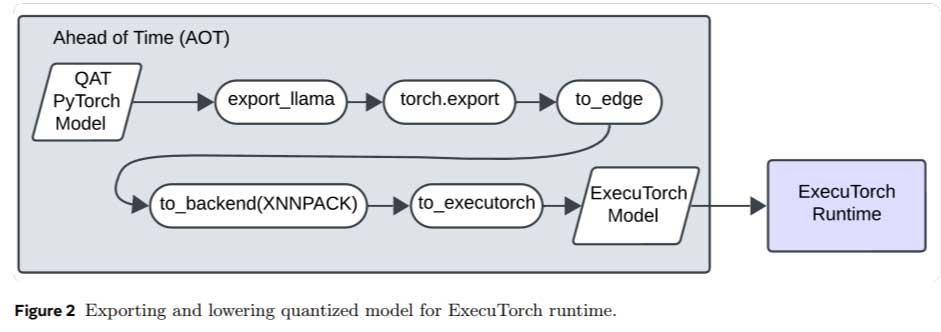
该研究强调了几个重要结论,总结如下:
- 压缩技术:先进的修剪和量化方法可以将 LLM 尺寸减少 7 倍以上,而不会显著降低准确性。
- 性能指标:Llama Guard 3-1B-INT4 在英语中获得了 0.904 的 F1 分数,在多种语言中也获得了相当的分数,在特定的安全审核任务中超越了 GPT-4。
- 部署可行性:该模型在商用 Android CPU 上每秒运行 30 个token,第一个token的时间少于 2.5 秒,展示了其在设备应用方面的潜力。
- 安全标准:该模型保持强大的安全调节能力,在多语言数据集中平衡效率和有效性。
- 可扩展性:该模型通过减少计算需求,实现了边缘设备上的可扩展部署,扩大了其适用性。

总之,Llama Guard 3-1B-INT4 代表了生成式 AI 安全审核方面的重大进步。它解决了尺寸、效率和性能方面的关键挑战,为移动部署提供了一个紧凑的模型,但又足够强大以确保高安全标准。通过创新的压缩技术和细致的微调,研究人员创建了一种可扩展且可靠的工具,为各种应用中更安全的 AI 系统铺平了道路。
论文地址:https://arxiv.org/abs/2411.17713
代码:https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai/llama_guard
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54294.html
