
创作、编辑和转换音乐和声音既有技术挑战,也有创意挑战。当前的人工智能模型往往在多功能性方面存在问题,专攻狭隘的任务或缺乏有效概括的能力。这限制了人工智能辅助制作并阻碍了创造性的适应性。人工智能要想真正为音乐和音频制作做出贡献,它必须具有多功能性、创作性,并能响应创意提示,让艺术家能够创作出独特的声音。显然,我们需要一种通用模型,能够驾驭音频和文本交互的细微差别,进行创造性转换,并提供高质量的输出。
NVIDIA 推出了 Fugatto,这是一种具有 25 亿个参数的 AI 模型,用于生成和处理音乐、语音和声音。Fugatto 将文本提示与高级音频合成功能相结合,使声音输入具有高度灵活性,可用于进行创造性实验 – 例如将钢琴曲改为人声演唱或让小号发出意想不到的声音。
该模型支持文本和可选音频输入,使其能够以超越传统音频生成模型的方式创建和处理声音。这种多功能方法允许进行实时实验,使艺术家和开发人员能够生成新类型的声音或流畅地修改现有音频。NVIDIA 注重灵活性,使 Fugatto 能够在涉及复杂作曲转换的任务中表现出色,使其成为艺术家和音频制作人的宝贵工具。
技术细节
Fugatto 采用创新的数据生成方法,超越了传统的监督学习。其训练不仅涉及常规数据集,还涉及专门的数据集生成技术,以创建各种音频和转换任务。它使用大型语言模型 (LLM) 来增强指令生成,使其能够更好地理解和解释音频和文本提示之间的关系。这种数据集丰富策略使 Fugatto 能够从不同的环境中学习,为多任务学习奠定了坚实的基础。
一项关键创新是可组合音频表示转换 (ComposableART),这是一种推理时间技术,旨在将无分类器指导扩展到作曲指令。这使 Fugatto 能够顺利地组合、插入或否定不同的音频生成指令,为声音创作开辟了新的可能性。ComposableART 提供了对合成的高水平控制,使用户能够精确地浏览 Fugatto 的声音调色板,混合不同的声音并产生独特的声音现象。
Fugatto 的架构利用了经过特定修改(如自适应层归一化)增强的 Transformer 模型,这有助于在不同输入之间保持一致性,并且比现有模型更好地支持作曲指令。这意味着该模型能够执行歌唱合成、声音转换和效果处理等任务,使其适用于各种音频应用。
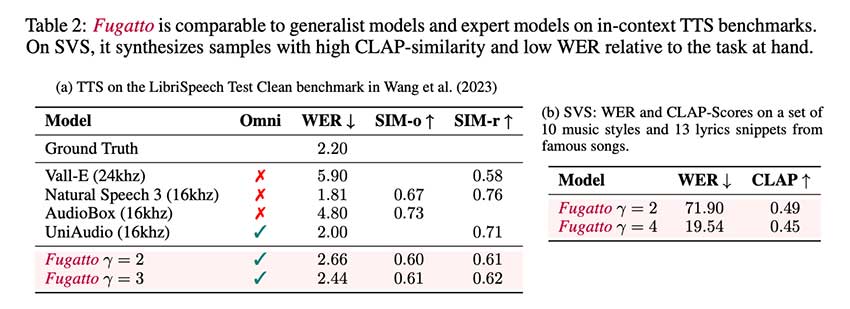
Fugatto 的多功能性在于它能够在创造力和技术的交汇处发挥作用。传统上,专业模型需要人工干预或狭义的任务,通常缺乏创造性实验所需的灵活性。然而,Fugatto 可以适应多种用途,这使其实用性在音频创作领域处于领先地位。Fugatto 的早期测试表明,它在常见基准上的表现与其他专业模型不相上下,但其真正的优势在于新兴能力。


结果令人鼓舞:与音频合成和转换的专用模型相比,Fugatto 的评估表明其性能具有竞争力或更优越。当负责合成新声音或遵循作曲指令时,Fugatto 的表现优于多项基准。例如,它展示了创造新声音的能力,例如合成具有不同寻常特征的萨克斯管或生成与背景音景流畅融合的语音 – 这些任务以前对其他模型来说都是具有挑战性的。
此外,Fugatto 能够生成新奇声音(超越典型训练数据的声音现象),为创意声音设计开辟了新的可能性。它使用 ComposableART 进行作曲合成,这意味着用户可以动态合并多个属性,使其成为寻求创意控制的音频制作人的宝贵工具。
结论
Fugatto 是音频生成 AI 领域的一项重大进步,它提供的功能挑战了传统限制并增强了创造性的声音处理。NVIDIA 将大型语言模型与声音和音乐的复杂性相结合,从而打造出一款功能强大且用途广泛的工具。Fugatto 能够管理细微的音频任务,从简单的声音生成到复杂的作曲修改,这为创意 AI 工具的未来做出了宝贵贡献。该模型不仅对艺术家具有重要意义,而且对游戏、娱乐和教育等行业也具有重要意义,在这些行业中,AI 工具越来越多地支持和激发人类的创造力。
更多信息请查看:https://blogs.nvidia.com/blog/fugatto-gen-ai-sound-model/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
