
人工智能模型规模的快速增长带来了巨大的计算和环境挑战。近年来,深度学习模型(尤其是语言模型)规模大幅扩张,需要更多的资源进行训练和部署。这种需求的增加不仅增加了基础设施成本,还导致碳足迹增加,使人工智能的可持续性降低。此外,小型企业和个人面临着越来越大的进入门槛,因为计算要求超出了他们的能力范围。这些挑战凸显了对更高效模型的需求,这些模型可以在不要求过高计算能力的情况下提供强大的性能。
为了应对这些挑战,Neural Magic 发布了 Sparse Llama 3.1 8B——一种经过 50% 修剪、2:4 GPU 兼容的稀疏模型,可提供高效的推理性能。Sparse Llama 以 SparseGPT、SquareHead Knowledge Distillation 和精选的预训练数据集为基础,旨在让 AI 更易于访问且更环保。通过仅需要 130 亿个额外令牌进行训练,Sparse Llama 显著减少了通常与训练大型模型相关的碳排放。这种方法符合行业的需求,即在提供可靠性能的同时平衡进步与可持续性。
技术细节
Sparse Llama 3.1 8B 利用稀疏技术,即在保留预测能力的同时减少模型参数。SparseGPT 与 SquareHead Knowledge Distillation 相结合,使 Neural Magic 能够实现 50% 修剪的模型,这意味着一半的参数已被智能消除。这种修剪可降低计算要求并提高效率。Sparse Llama 还利用先进的量化技术来确保模型能够在 GPU 上有效运行,同时保持准确性。主要优势包括仅通过稀疏性即可将延迟降低 1.8 倍,吞吐量提高 40%,与量化相结合时可将延迟降低 5 倍,这使得 Sparse Llama 适用于实时应用。
Sparse Llama 3.1 8B 的发布对 AI 社区来说是一项重要进展。该模型解决了效率和可持续性挑战,同时证明了无需为了计算经济而牺牲性能。Sparse Llama 在 Open LLM Leaderboard V1 上恢复了 98.4% 的少样本任务准确率,并展示了完全准确率恢复,在某些情况下,聊天、代码生成和数学任务的微调性能有所提高。这些结果表明,稀疏性和量化具有实际应用,使开发人员和研究人员能够用更少的资源实现更多目标。
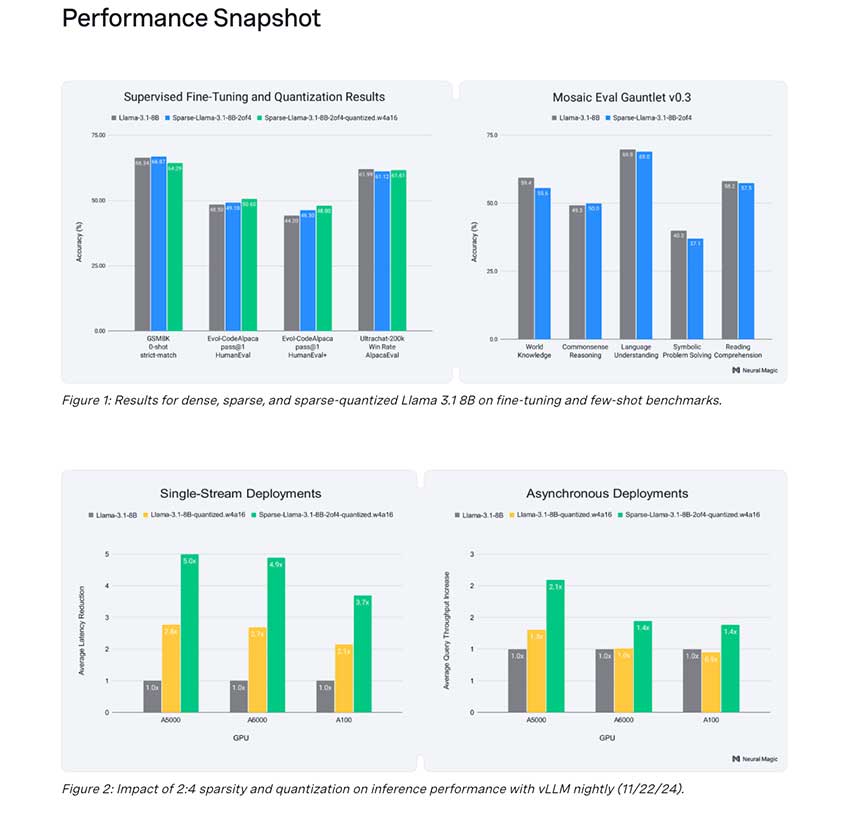
结论
Sparse Llama 3.1 8B 展示了模型压缩和量化方面的创新如何带来更高效、更易用、更环保的 AI 解决方案。通过减少与大型模型相关的计算负担,同时保持强大的性能,Neural Magic 为平衡效率和有效性树立了新标准。Sparse Llama 代表着 AI 在使人工智能更加公平和环保方面向前迈出了一步,让我们看到了未来的景象:无论计算资源如何,更广泛的受众都可以使用强大的模型。
更多详细信息:https://huggingface.co/neuralmagic/Sparse-Llama-3.1-8B-2of4
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54176.html
