
多年来,视觉模型得到了长足的发展,每一次创新都能解决以往方法的局限性。在计算机视觉领域,研究人员经常面临如何平衡复杂性、通用性和可扩展性的挑战。目前的许多模型都难以有效地处理各种视觉任务或高效地适应新的数据集。传统上,大规模预训练视觉编码器使用对比学习,尽管这种方法很成功,但在扩展性和参数效率方面存在挑战。因此,我们仍然需要一种既能处理多种模式(如图像和文本),又不牺牲性能或需要大量数据过滤的稳健、多用途模型。
AIMv2:一种新方法
Apple 已发布 AIMv2 来应对这一挑战,AIMv2 是一系列开放式视觉编码器,旨在改进现有模型在多模态理解和物体识别任务中的性能。受 CLIP 等模型的启发,AIMv2 添加了自回归解码器,使其能够生成图像块和文本标记。AIMv2 系列包括 19 个模型,参数大小各不相同——300M、600M、1.2B 和 2.7B——并支持 224、336 和 448 像素的分辨率。这种模型大小和分辨率范围使 AIMv2 适用于不同的用例,从小规模应用程序到需要较大模型的任务。
技术概述
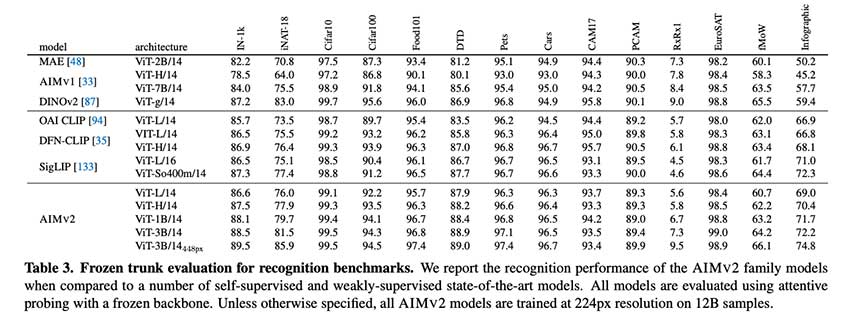
AIMv2 采用了多模态自回归预训练框架,该框架建立在类似模型中使用的传统对比学习方法之上。AIMv2 的主要特性是它将视觉变换器 (ViT) 编码器与因果多模态解码器相结合。在预训练期间,编码器处理图像块,随后将其与相应的文本嵌入配对。然后,因果解码器自回归生成图像块和文本标记,重建原始多模态输入。这种设置简化了训练并促进了模型扩展,而无需专门的批次间通信或极大的批次大小。此外,与其他方法相比,多模态目标使 AIMv2 能够实现更密集的监督,从而增强了其从图像和文本输入中学习的能力。
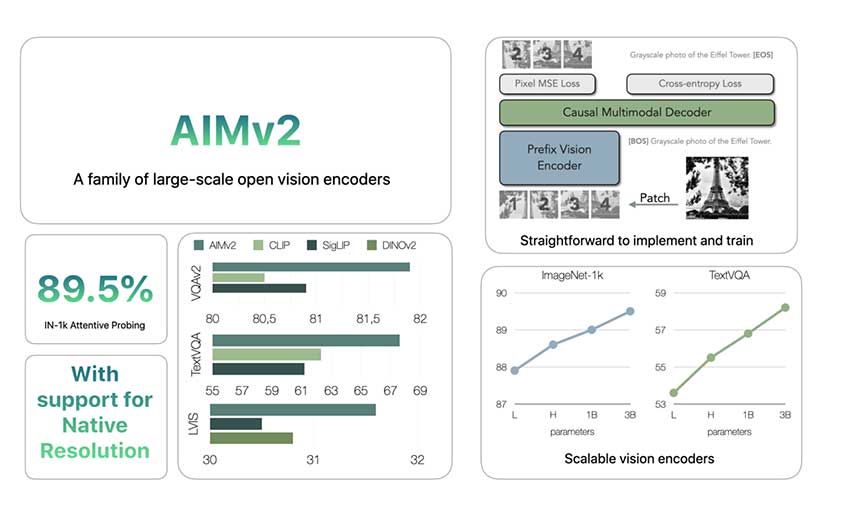
性能和可扩展性
在大多数多模态理解基准测试中,AIMv2 的表现优于 OAI CLIP 和 SigLIP 等现有主要模型。具体而言,AIMv2-3B 在冻结主干的 ImageNet 数据集上实现了 89.5% 的 top-1 准确率,证明了冻结编码器模型的显著稳健性。与 DINOv2 相比,AIMv2 在开放词汇对象检测和指称表达理解方面也表现良好。此外,AIMv2 的可扩展性显而易见,因为其性能随着数据和模型大小的增加而不断提高。该模型的灵活性以及与 Hugging Face Transformers 库等现代工具的集成使其在各种应用程序中实用且直接实施。
结论
AIMv2 代表了视觉编码器开发领域的重大进步,强调了训练的简单性、有效的扩展和多模态任务的多功能性。Apple 发布的 AIMv2 比以前的模型有所改进,在包括开放词汇识别和多模态任务在内的众多基准测试中表现出色。自回归技术的集成实现了密集监督,从而实现了强大而灵活的模型功能。AIMv2 在 Hugging Face 等平台上的可用性使开发人员和研究人员能够更轻松地尝试高级视觉模型。AIMv2 为开放集视觉编码器树立了新标准,能够解决现实世界中多模态理解日益复杂的问题。
论文地址:https://huggingface.co/collections/apple/aimv2-6720fe1558d94c7805f7688c
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54151.html
