
视频生成模型的最新进展使得人们能够制作出高质量、逼真的视频片段。然而,由于训练和推理所需的计算量,这些模型在大规模实际应用中面临挑战。目前的商用模型如 Sora、Runway Gen-3 和 Movie Gen 需要大量资源,包括数千个 GPU 和数百万个 GPU 小时的训练时间,而每秒的视频推理需要几分钟。这些高要求使得这些解决方案对于许多潜在应用来说成本高昂且不切实际,从而将高保真视频生成的使用限制在那些拥有大量计算资源的应用中。
Reducio-DiT:一种新的解决方案
微软研究人员推出了一种旨在解决这一问题的新方法 Reducio-DiT。该解决方案以图像条件变分自动编码器 (VAE) 为中心,可显著压缩视频表示的潜在空间。Reducio-DiT 背后的核心思想是,与静态图像相比,视频包含更多冗余信息,可以利用这种冗余在不影响视频质量的情况下将潜在表示大小减少 64 倍。研究团队将这种 VAE 与扩散模型相结合,提高了生成 1024×1024 视频片段的效率,将单个 A100 GPU 上的推理时间缩短至 15.5 秒。
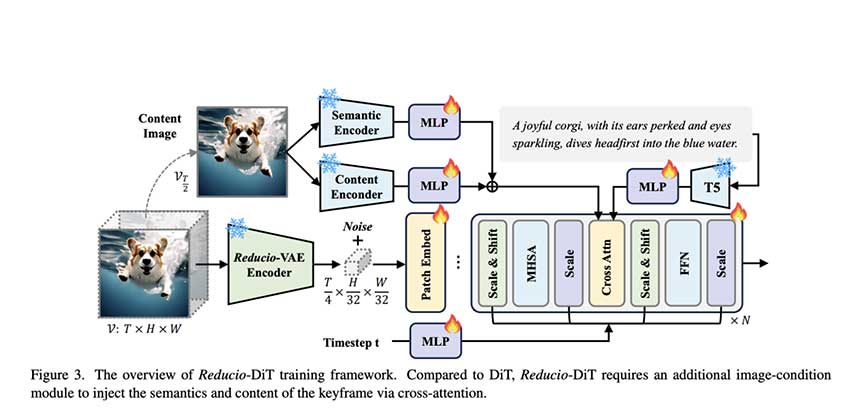
技术方法
从技术角度来看,Reducio-DiT 因其两阶段生成方法而脱颖而出。首先,它使用文本到图像技术生成内容图像,然后使用该图像作为先验通过扩散过程创建视频帧。构成视频内容很大一部分的运动信息与静态背景分离,并在潜在空间中得到有效压缩,从而大大减少了计算占用空间。具体来说,Reducio-VAE(Reducio-DiT 的自动编码器组件)利用 3D 卷积实现显着的压缩因子,从而实现输入视频的 4096 倍下采样表示。扩散组件 Reducio-DiT 将这种高度压缩的潜在表示与从内容图像和相应文本提示中提取的特征相结合,从而以最小的开销生成流畅的高质量视频序列。
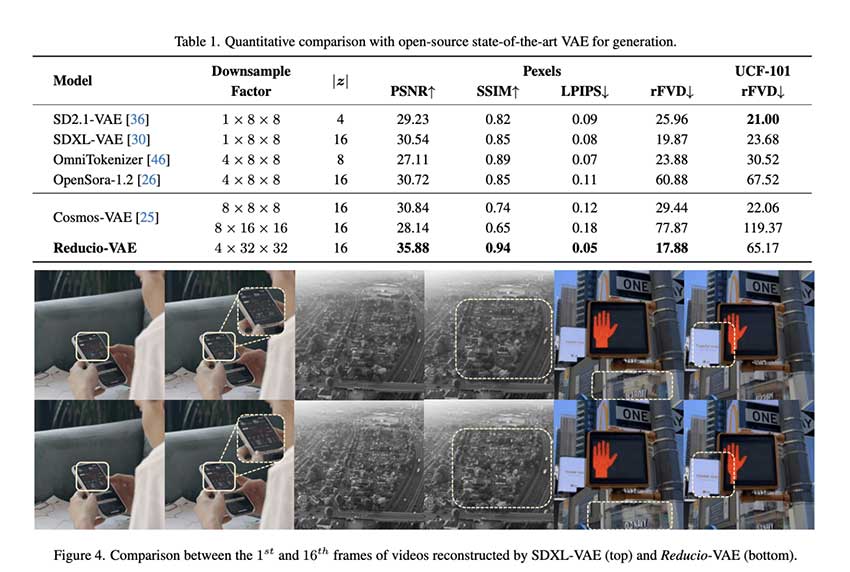
这种方法之所以重要有几个原因。Reducio-DiT 为饱受计算挑战困扰的行业提供了一种经济高效的解决方案,使高分辨率视频生成更容易实现。与 Lavie 等现有方法相比,该模型的速度提高了 16.6 倍,同时在 UCF-101 上实现了 318.5 的 Fréchet 视频距离 (FVD) 得分,优于该类别中的其他模型。通过利用从低分辨率到高分辨率视频生成的多阶段训练策略,Reducio-DiT 可以在生成的帧之间保持视觉完整性和时间一致性——这是许多以前的视频生成方法难以实现的挑战。此外,紧凑的潜在空间不仅加速了视频生成过程,还降低了硬件要求,使其可以在没有大量 GPU 资源的环境中使用。
结论
微软的 Reducio-DiT 代表了视频生成效率的进步,在高质量和降低计算成本之间取得了平衡。能够在 15.5 秒内生成 1024×1024 视频片段,同时显著降低训练和推理成本,标志着视频生成 AI 领域的显著发展。如需进一步的技术探索和源代码访问,请访问微软的 Reducio-VAE GitHub 存储库。这一发展为视频生成技术在内容创作、广告和互动娱乐等应用中的更广泛应用铺平了道路,在这些应用中,快速且经济高效地生成引人入胜的视觉媒体至关重要。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/54120.html
