
视觉语言模型 (VLM) 的开发在处理复杂的视觉问答任务方面面临挑战。尽管 OpenAI 的 GPT-o1 等大型语言模型在推理能力方面取得了长足进步,但 VLM 仍然难以进行系统性和结构化的推理。当前的模型通常缺乏组织信息和进行逻辑、顺序推理的能力,这限制了它们在需要深度认知处理的任务中的有效性,尤其是在处理图像与文本相结合等多模态输入时。传统的 VLM 往往会产生即时响应,而不是采用逐步推理的方法,从而导致错误和不一致。
关于 LLaVA-o1
北京大学、清华大学、彭程实验室、阿里巴巴达摩院和利哈伊大学的研究人员团队推出了 LLaVA-o1:一种能够进行系统推理的视觉语言模型,类似于 GPT-o1。LLaVA-o1 是一个拥有 110 亿个参数的模型,旨在进行自主、多阶段推理。它以 Llama-3.2-Vision-Instruct 模型为基础,引入了结构化的推理过程,以更有条理的方法解决了以前的 VLM 的局限性。LLaVA-o1 的关键创新是实现了四个不同的推理阶段:摘要、标题、推理和结论。
该模型使用名为 LLaVA-o1-100k 的数据集进行微调,该数据集来自视觉问答 (VQA) 源和 GPT-4o 生成的结构化推理注释。这使 LLaVA-o1 能够执行多阶段推理,将类似于 GPT-o1 的功能扩展到视觉语言任务中,而这些任务历来落后于基于文本的模型。
技术细节和优势
LLaVA-o1 采用了一种名为阶段级束搜索的新型推理时间缩放技术。与以前的方法(例如最佳 N 或句子级束搜索)不同,LLaVA-o1 会为其结构化推理过程的每个阶段生成多个响应,并在每一步中选择最佳候选,从而确保更高质量的结果。这种结构化方法在整个推理过程中保持逻辑连贯性,从而得出更准确的结论。
LLaVA-o1 基于 Llama-3.2-11B-Vision-Instruct 模型进行微调,与基础模型相比,其多模态推理基准测试提高了 8.9%,甚至超越了 Gemini-1.5-pro、GPT-4o-mini 和 Llama-3.2-90B-Vision-Instruct 等规模更大或闭源的竞争对手。它仅使用 100,000 个训练样本就实现了这一目标,这使得 LLaVA-o1 在性能和可扩展性方面都成为一种高效的解决方案。通过采用不同阶段的结构化思维,LLaVA-o1 系统地解决问题,最大限度地减少了其他 VLM 中常见的推理错误。
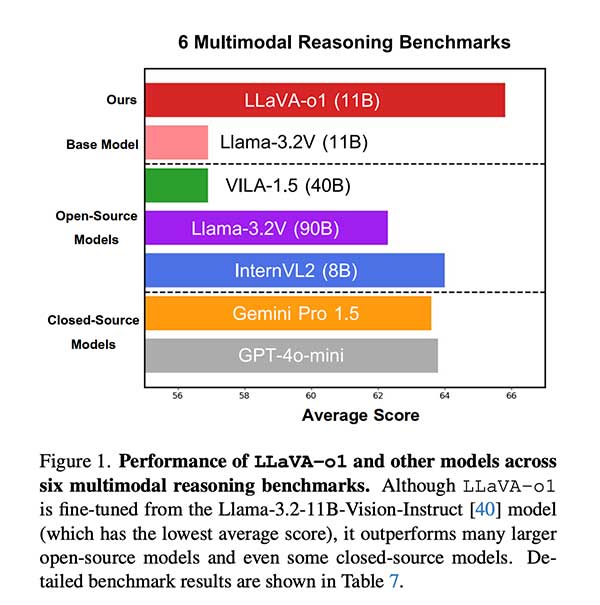
重要性和结果
LLaVA-o1 通过在视觉语言任务中实现系统推理,弥补了文本和视觉问答模型之间的巨大差距。实验结果表明,LLaVA-o1 在 MMStar、MMBench、MMVet、MathVista、AI2D 和 HallusionBench 等基准测试中提高了性能。它在多模态基准测试中始终比其基础模型高出 6.9% 以上,特别是在数学和科学视觉问题等推理密集型领域。
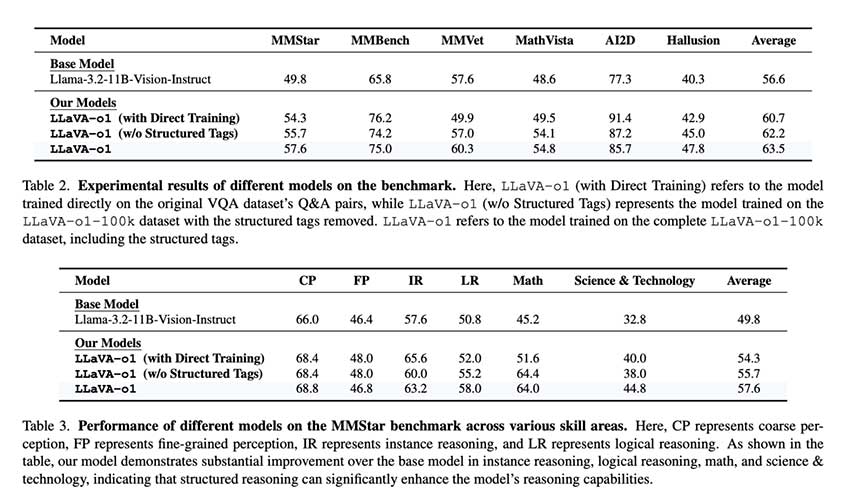
阶段级集束搜索通过为每个阶段生成和验证多个候选响应并选择最合适的响应来提高模型的可靠性。与效率低下的传统推理扩展方法相比,这使 LLaVA-o1 能够在复杂的视觉任务中表现出色。LLaVA-o1 表明,结构化响应对于实现高质量、一致的推理至关重要,为类似大小的模型树立了新标准。
结论
LLaVA-o1 是一种能够进行系统推理的视觉语言模型,类似于 GPT-o1。其四阶段推理结构与阶段级定向搜索相结合,为多模态 AI 树立了新的标杆。通过在相对较小但经过战略性构建的数据集上进行训练,LLaVA-o1 证明了高效且可扩展的多模态推理无需大型闭源模型所需的大量资源即可实现。LLaVA-o1 为未来在视觉语言模型中进行结构化推理的研究铺平了道路,有望在视觉和文本领域实现更先进的 AI 驱动认知处理能力。
论文地址:https://arxiv.org/abs/2411.10440
GitHub:https://github.com/PKU-YuanGroup/LLaVA-o1
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53994.html
