
边缘人工智能长期以来一直面临着平衡效率和有效性的挑战。由于边缘设备规模大、计算需求高以及延迟问题,在边缘设备上部署视觉语言模型 (VLM) 非常困难。为云环境设计的模型通常会因边缘设备资源有限而苦恼,导致电池消耗过多、响应时间变慢以及连接不一致。增强现实、智能家居助手和工业物联网等应用需要快速处理视觉和文本输入,因此对轻量级但高效模型的需求不断增长。在视觉问答或图像字幕等任务中,幻觉率的增加和结果不可靠使这些挑战变得更加复杂,因为质量和准确性至关重要。
Nexa AI 发布 OmniVision-968M:全球最小的视觉语言模型,为边缘设备减少了 9 倍的Token。OmniVision-968M 的架构比 LLaVA(大型语言和视觉助手)有所改进,实现了全新的紧凑性和效率水平,非常适合在边缘运行。该设计专注于将图像Tokens减少 9 倍(从 729 个减少到 81 个),大大降低了此类模型通常伴随的延迟和计算负担。
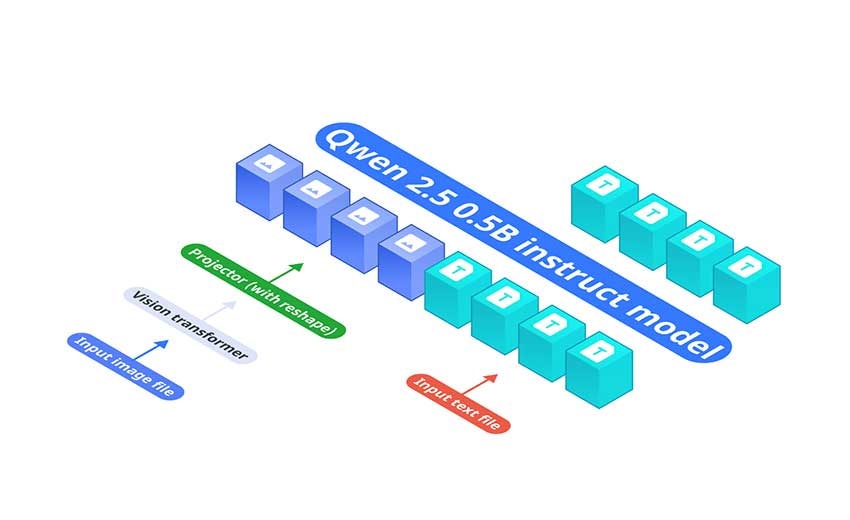
OmniVision 的架构由三个主要组件构成:
- 基础语言模型:Qwen2.5-0.5B-Instruct 作为处理文本输入的核心模型。
- 视觉编码器:SigLIP-400M,具有 384 分辨率和 14×14 块大小,可生成图像嵌入。
- 投影层:多层感知器 (MLP) 将视觉编码器的嵌入与语言模型的标记空间对齐。与标准 Llava 架构不同,其投影层将图像Tokens的数量减少了 9 倍。
OmniVision-968M 集成了多项关键技术进步,非常适合边缘部署。该模型的架构基于 LLaVA 进行了增强,使其能够高效处理视觉和文本输入。图像Tokens从 729 个减少到 81 个代表了优化方面的重大飞跃,与现有模型相比,其标记处理效率提高了近 9 倍。这对减少延迟和计算成本有着深远的影响,而延迟和计算成本是边缘设备的关键因素。此外,OmniVision-968M 利用可靠的数据源进行直接偏好优化 (DPO) 训练,这有助于缓解幻觉问题——这是多模态 AI 系统中常见的挑战。通过专注于视觉问答和图像字幕,该模型旨在提供无缝、准确的用户体验,确保边缘应用中的可靠性和稳健性,其中实时响应和功率效率至关重要。
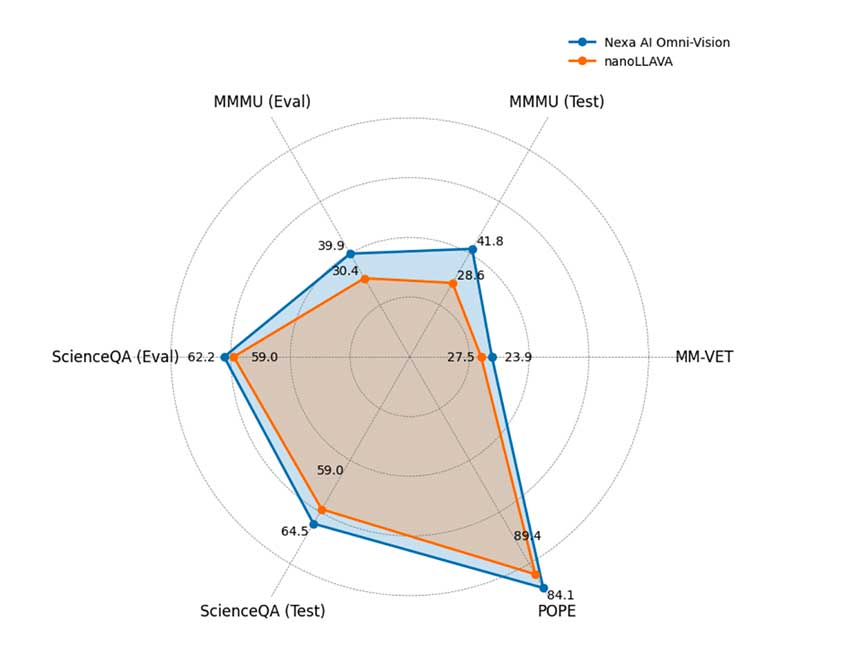
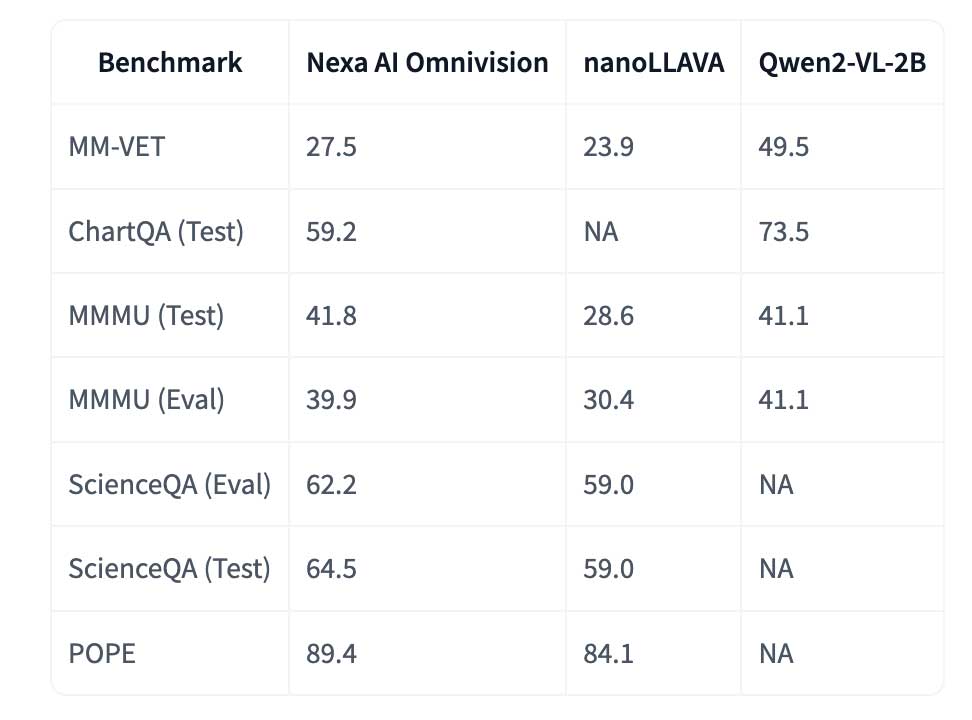
OmniVision-968M 的发布代表了显著的进步,原因有几个。首先,token 数量的减少显著减少了推理所需的计算资源。对于希望在受限环境(如可穿戴设备、移动设备和物联网硬件)中实施 VLM 的开发人员和企业来说,OmniVision-968M 的紧凑尺寸和效率使其成为理想的解决方案。
此外,DPO 训练策略有助于最大限度地减少幻觉,幻觉是模型生成不正确或误导性信息的常见问题,从而确保 OmniVision-968M 既高效又可靠。初步基准测试表明,与之前的模型相比,OmniVision-968M 的推理时间减少了 35%,同时保持甚至提高了视觉问答和图像字幕等任务的准确性。这些进步有望鼓励医疗保健、智慧城市和汽车等需要高速、低功耗 AI 交互的行业采用。
总之,Nexa AI 的 OmniVision-968M 解决了 AI 行业长期存在的一个空白:需要能够在边缘设备上无缝运行的高效视觉语言模型。通过减少图像token 、优化 LLaVA 的架构并结合 DPO 训练以确保可靠的输出,OmniVision-968M 代表了边缘 AI 的新前沿。这种模型使我们更接近无处不在的 AI 的愿景——智能互联设备可以在本地执行复杂的多模式任务,而无需持续的云支持。
详细信息请查看:https://huggingface.co/NexaAIDev/omnivision-968M
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53968.html
