
大型语言模型 (LLM) 的最新进展已在从解决数学问题到回答医学问题的广泛应用中展现出强大的能力。然而,由于这些模型规模庞大,并且需要大量的计算资源来训练和部署它们,因此它们变得越来越不实用。像 OpenAI 或 Google 开发的 LLM 这样的模型通常包含数千亿个参数,需要大量数据集和高昂的训练成本。这反过来又导致了财务和环境负担,使许多研究人员和组织无法使用这些模型。规模的不断扩大也引发了人们对效率、延迟以及在计算资源可能有限的实际应用中有效部署这些模型的能力的担忧。
TensorOpera AI 发布 Fox-1:一系列小型语言模型 (SLM)
为了应对这些挑战,TensorOpera AI 发布了 Fox-1,这是一系列小型语言模型 (SLM),旨在提供类似 LLM 的功能,同时显著降低资源需求。Fox-1 包括两个主要变体:Fox-1-1.6B 和 Fox-1-1.6B-Instruct-v0.1,旨在提供强大的语言处理能力,同时保持高效率和可访问性。这些模型已在 3 万亿个网络抓取数据上进行了预训练,并使用 50 亿个标记进行了微调,以完成指令跟踪任务和多轮对话。通过在 Apache 2.0 许可下提供这些模型,TensorOpera AI 寻求促进对强大语言模型的开放访问,并使 AI 开发大众化。
技术细节
Fox-1 采用了多项技术创新,使其在其他 SLM 中脱颖而出。其中一个显著特点是其三阶段数据课程,确保训练从一般环境逐步过渡到高度专业化的环境。在预训练期间,数据被组织成三个不同的阶段,使用 2K-8K 序列长度,使 Fox-1 能够有效地学习文本中的短依赖关系和长依赖关系。该模型架构是仅解码器转换器的更深层变体,具有 32 层,与 Gemma-2B 和 StableLM-2-1.6B 等同类产品相比,深度明显增加。
除了更深层次的架构之外,Fox-1 还使用了分组查询注意 (GQA),这可以优化内存使用率并提高训练和推理速度。扩展的词汇量为 256,000 个标记,进一步增强了模型理解和生成文本的能力,同时降低了标记歧义。通过共享输入和输出嵌入,Fox-1 还减少了参数总数,从而产生了更紧凑、更高效的模型。这些创新共同使 Fox-1 能够在语言任务中实现最先进的性能,而无需通常与 LLM 相关的计算开销。
性能结果
Fox-1 的发布具有特别重要的意义,原因如下。首先,它解决了 AI 中可访问性的核心问题。通过提供高效且功能强大的模型,TensorOpera AI 正在向更广泛的受众提供高级自然语言理解和生成功能,包括可能无法访问大型 LLM 所需的计算基础设施的研究人员和开发人员。Fox-1 已与 StableLM-2-1.6B、Gemma-2B 和 Qwen1.5-1.8B 等领先的 SLM 进行了基准测试,并且在各种标准基准测试(例如 ARC Challenge、MMLU 和 GSM8k)中始终表现不相上下或更佳。
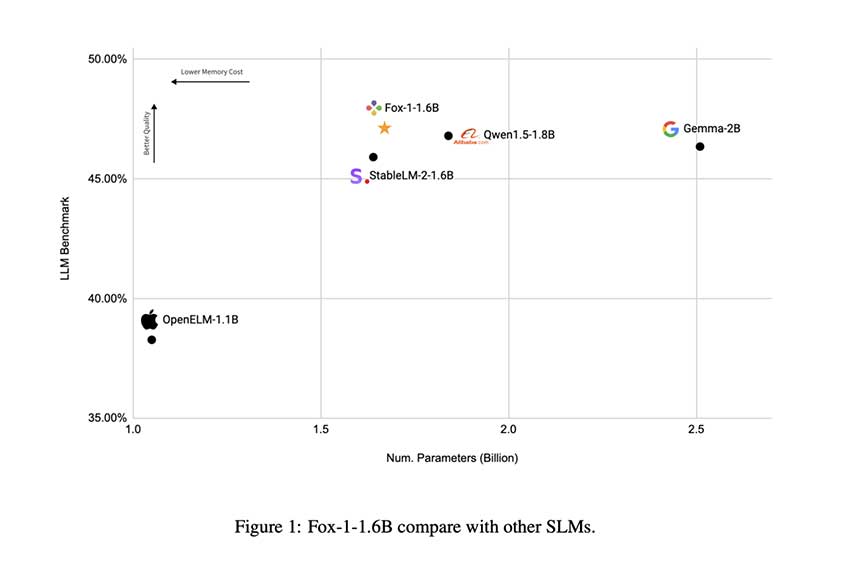
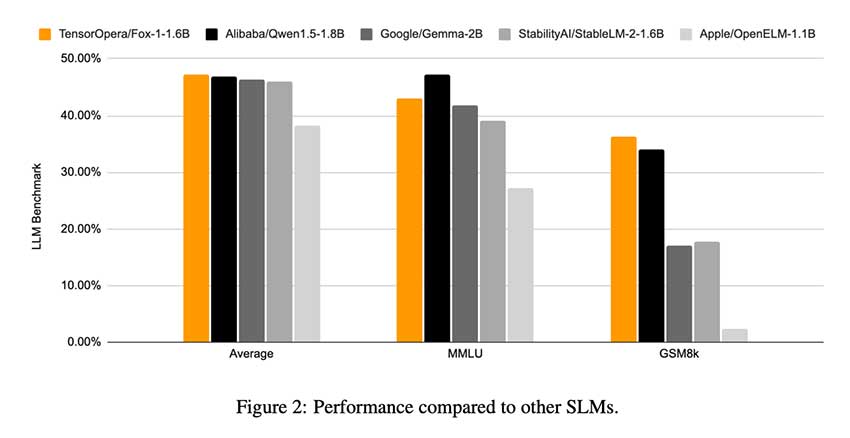
具体结果方面,Fox-1 在 GSM8k 基准测试中实现了 36.39% 的准确率,优于所有对比模型,包括大小为其两倍的 Gemma-2B。尽管规模较小,但它在 MMLU 基准测试中也表现出色。Fox-1 的推理效率是在 NVIDIA H100 GPU 上使用 vLLM 测量的,每秒可实现超过 200 个 token,与 Qwen1.5-1.8B 等较大模型的吞吐量相当,但占用的 GPU 内存更少。这种效率使 Fox-1 成为需要高性能但受硬件限制的应用程序的不二之选。
结论
TensorOpera AI 的 Fox-1 系列标志着小型但功能强大的语言模型的开发向前迈出了重要一步。通过结合高效的架构、先进的注意力机制和周到的训练策略,Fox-1 提供了可与大型模型相媲美的出色性能。随着开源版本的发布,Fox-1 有望成为研究人员、开发人员和组织的宝贵工具,帮助他们利用高级语言功能,而无需承担大型语言模型的高昂成本。Fox-1-1.6B 和 Fox-1-1.6B-Instruct-v0.1 模型表明,可以通过更高效、更简化的方法实现高质量的语言理解和生成。
论文地址:https://arxiv.org/abs/2411.05281
聊天模型:https://huggingface.co/tensoropera/Fox-1-1.6B-Instruct-v0.1
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53846.html
