
作者:Ryuk
来源:语音算法组
链接:https://mp.weixin.qq.com/s/PMKFQvPNLJH7qXqp8fWjkA
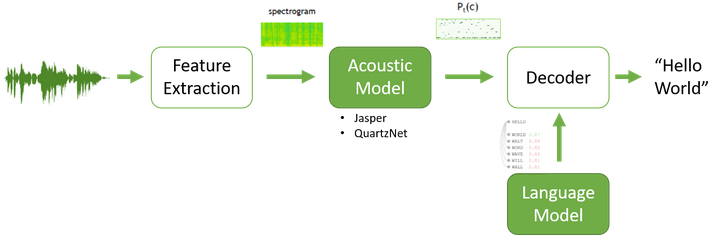
语音识别算法目的是从声学特征x中找到最有可能生成的词序列y,即
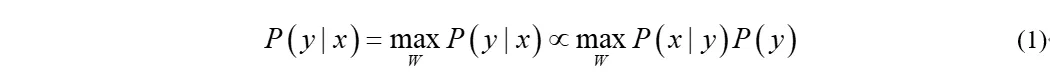
完整的语音识别算法包括特征提取、声学模型、语言模型和解码,其中语言模型(Langulage Model, LM)负责计算词序列W={w1,…,wn} 的概率估计P(W)。并且语言模型在识别过程中可以帮助引导和限制备选词假设之间的搜索结果。
语言模型是通过学习大量文本数据来预测或生成语言内容的模型。语言模型的核心目标是学习词语或字符序列的分布,以便在给定上下文的情况下,预测下一词(或字符)的可能性,或生成合理的句子和段落。根据现有的工作,语言模型大致可以分为两大类:
- 基于统计的语言模型,如ngram;
- 基于神经网络的语言模型,如rnnlm;
无论哪种形态的语言模型最终都是要和声学模型一起使用,但是可以选择在不同的位置加入语言模型以达到不同的效果,今天本文就介绍下声学模型和语言模型融合几种方式。
Shallow Fusion
首先很容易想到,声学模型有个得分,语言模型也有个得分,加权求和不就好了,这就是最传统的shallow fusion方法。声学模型和语言模型分开训练,然后在声学模型beam-search时做得分的加权,即
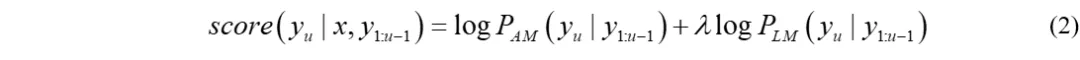
其中λ为语言模型的权重,在shallow fusion 中,声学模型和语言模型完全独立的,可以随意地更换语言模型,比如从ngram切换到Transformerlm,只需要重新调整语言模型权重λ即可。
LM Rescoring
由于shallow fusion是在token级别进行的融合,计算量随着句子的长度而增加,那么有没有开销比较小的方法呢?答案是肯定的,可以在整个句子解码后,对句子级别的n-best结果使用语言模型打分,然后与声学模型得分加权,即
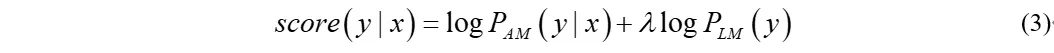
虽然相比shallow fusion逐token计算语言模型得分,rescoring方法减少了计算量,但是其搜索空间减少为句子级别的n-best,因此精度相对于shallow fusion有所下降。
Density Ratio
目前端到端的方案已经成为了语音识别的主流,研究者们普遍认为像RNNT之类的模型,在训练过程中模型也学到了一些语言的信息,称其为内部语言模型(Internal Language Model, ILM)。这个内部语言模型是基于声学模型训练集内容训练的,当遇到跨域问题时,内部语言模型和外部的语言模型存在冲突,对最终的识别结果有影响。一个可行的解决方案是在声学模型的源域再训练一个语言模型,然后在shallow fusion后减去这个语言模型。假设源域为ψ,目标域是τ,那么density ratio方法可以通过贝叶斯定理推导得到端到端模型的后验概率:
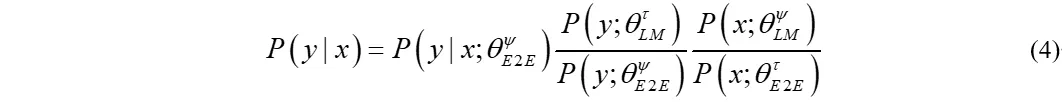
在推理过程中,内部语言模型的对数概率应该由端到端模型和外部语言模型分数的对数线性组合中减去,即:
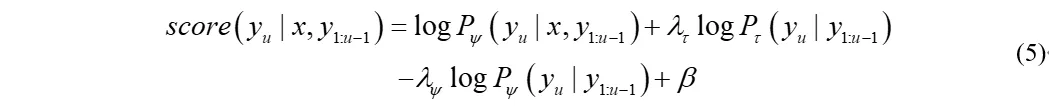
其中β是非blank的奖励。显然,这种方法在跨域的场景下比shallow fusion更好。此外,这种方法和shallow fusion一样,只在解码时需要介入,不影响声学模型的训练过程,最后只需要微调下不同语言模型的权重即可。
Internal Language Model Estimation
density ratio方法假设源域端到端模型的后验可以分解为具有独立参数的声学模型和语言模型,类似于混合系统。然而严格来说,根据贝叶斯定理,端到端模型的后验概率应该都条件分布于模型的参数:
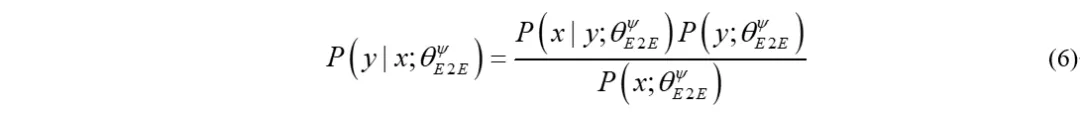
同样的,在推理过程中,内部语言模型的对数概率应该由端到端模型和外部语言模型分数的对数线性组合中减去,即
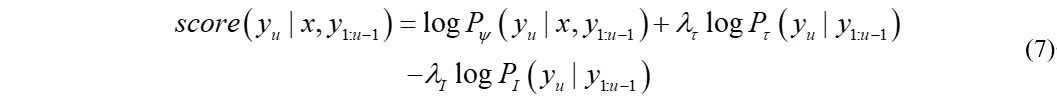
对比公式(4)和公式(6)可以发现与density ratio方法不同的是,这里的内部语言模型和声学模型基于同一组参数条件化,这种方法称为内部语言模型估计(Internal Language Model Estimation, ILME)。那么剩下的问题就是如何估计这个内部语言模型了。
内部语言模型定义为端到端模型从音频-转录数据对中隐式学习到的令牌序列概率分布,然而直接整个声学空间中计算在实际中是不可行的。这里需要使用一种称作联合软最大近似(Joint Softmax Approximation,JSA)的方法,该方法用于通过消除编码器激活的影响来近似混合自回归传输器(hybrid autoregressive transducer, HAT)模型的内部语言模型。简单来说,在RNNT模型中,直接将encoder的输出置零,只让decoder的输出通过joint network,便可以得到ILM的分数;在AED模型中,屏蔽掉encoder的encoder的输出,解码器仅根据文本输入计算ILM的分数。
Weighted Finite-State Transducers
WFST(加权有限状态转换器)是一种扩展了有限状态机(Finite-State Machine, FSM)的模型,能够处理带权重的符号转换问题。简单来说,WFST是一种在两个符号集之间进行映射的工具,并为每个转换赋予一个权重或代价。它是一个有向图,图中的每条边表示符号的转换,同时伴随一个权重。在端到端语音识别中,T 是以建模单元来构图的,IH 为声学模型神经网络的建模单元英文音素。下图就是 ‘is’ 中 /i/ 的发音表示:
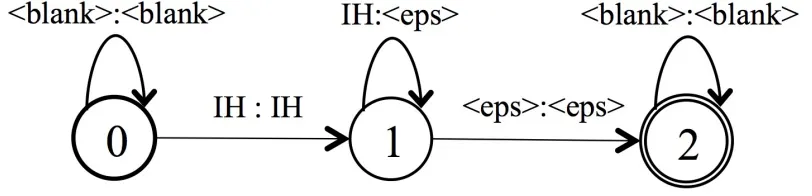
L 是发音词典,包含了字到词的映射,下图为’is’的发音/iz/的表示:

G是语言模型,用于识别how are you,how is it的语言模型构图如下:
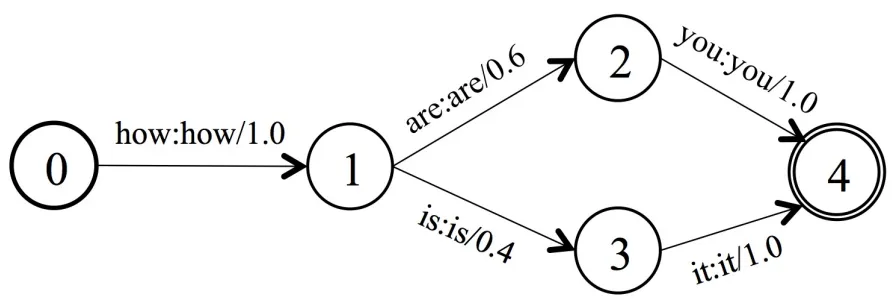
通过TLG的Compose,把声学建模单元,词典,语言模型糅合在一起,产生一个静态的解码网络。在解码过程中采用搜索策略,得到输入语音的最优解码结果。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
