
主观语音质量评估 (SSQA) 的一个关键挑战是使模型能够在各种未见过的语音领域中推广。通用 SSQA 模型评估了许多模型在其训练领域之外表现不佳,主要是因为这种模型在跨领域表现不佳,然而,由于不同类型的 SSQA 任务(包括 TTS、VC 和语音增强)之间存在截然不同的数据特征和评分系统,这同样具有挑战性。SSQA 的有效推广对于确保这些领域中人类感知的一致性是必要的,然而,许多此类模型仍然局限于它们训练的数据,从而限制了它们在 TTS 和 VC 系统的自动语音评估等应用中的实际效用。
当前的 SSQA 方法包括基于参考的方法和基于模型的方法。基于参考的模型通过将语音样本与参考进行比较来评估质量。另一方面,基于模型的方法(尤其是 DNN)直接从人工注释的数据集中学习。基于模型的 SSQA 具有更精确地捕捉人类感知的强大潜力,但同时也显示出一些非常明显的局限性:
- 泛化约束:SSQA 模型在使用新的域外数据进行测试时经常会出现故障,导致性能不一致。
- 数据集偏差和语料库效应:模型可能会过于适应数据集的特点及其所有特性,例如评分偏差或数据类型,这可能会降低它们在不同数据集上的有效性。
- 计算复杂性:集成模型提高了 SSQA 的稳健性,但与此同时,与基线模型相比,计算成本也增加了,这降低了它在资源匮乏的环境中进行实时评估的可能性。上述限制共同阻碍了良好 SSQA 模型的开发,这些模型无法很好地适用于不同的数据集和应用环境。
为了解决这些限制,研究人员引入了 MOS-Bench,这是一个基准集合,其中包括七个训练数据集和十二个测试数据集,涵盖不同的语音类型、语言和采样频率。除了 MOS-Bench,SHEET 是一个建议使用的工具包,它为 SSQA 模型的训练、验证和测试提供了标准化的工作流程。MOS-Bench 与 SHEET 的这种结合允许系统地评估 SSQA 模型,而这些评估特别需要模型的泛化能力。MOS-Bench 采用了多数据集方法,结合了不同来源的数据,以扩大模型在不同条件下的暴露范围。除此之外,还引入了最佳得分差异/比率新性能指标,以对 SSQA 模型在这些数据集上的性能进行整体评估。这不仅提供了一个一致评估的框架,而且随着模型与现实世界的变化相一致,它的泛化能力也更好,这对 SSQA 来说是一个非常显著的贡献。
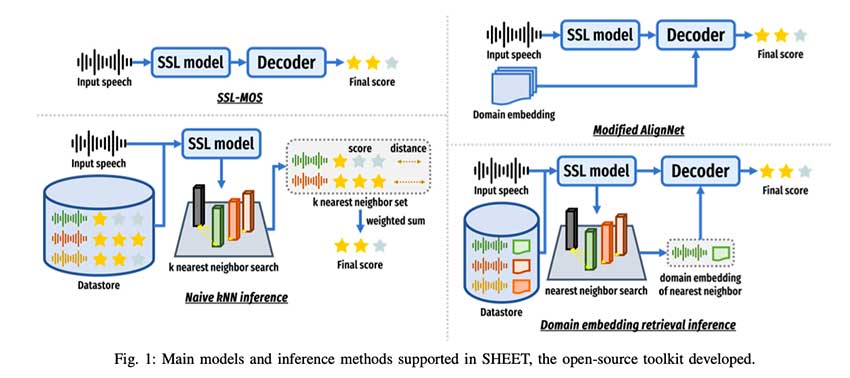
MOS-Bench 数据集集合包含各种数据集,这些数据集的采样频率和听众标签具有多样性,可捕捉 SSQA 中的跨域变化。主要数据集包括:
- BVCC——附带 TTS 和 VC 样本的英语数据集。
- SOMOS:在 LJSpeech 上训练的英语 TTS 模型的语音质量数据。
- SingMOS:中文和日语歌唱声音采样数据集。
- NISQA:经过网络通信的嘈杂语音样本。数据集是多语言、多领域和多种语音类型的,可用于广泛的训练范围。MOS-Bench 使用 SSL-MOS 模型和修改后的 AlignNet 作为主干,利用 SSL 来学习丰富的特征表示。SHEET 通过数据处理、训练和评估工作流程使 SSQA 流程更进一步。SHEET 还包括基于检索的评分非参数 kNN 推理,以提高模型的忠实度。此外,还包含了超参数调整,例如批量大小和优化策略,以进一步提高模型性能。
使用 MOS-Bench 和 SHEET,两者都极大地提高了 SSQA 在合成和非合成测试集上的泛化能力,以至于模型学会了即使对于域外数据也能获得高排名和高度准确的质量预测。在 MOS-Bench 数据集上训练的模型(如 PSTN 和 NISQA)在合成测试集上具有高度的鲁棒性,而之前泛化所需的合成数据的需求已经过时。此外,这种可视化的结合坚定地确立了在 MOS-Bench 上训练的模型可以捕获各种数据分布,并反映出更好的适应性和一致性。在这方面,MOS-Bench 引入这些结果进一步建立了可靠的基准,使 SSQA 模型能够在不同领域应用准确的性能,从而提高自动语音质量评估的有效性和适用性。
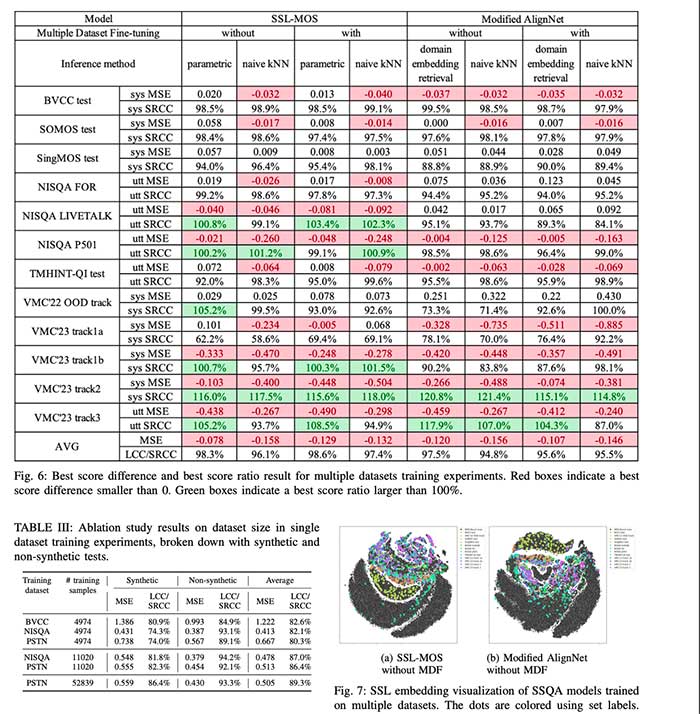
该方法通过 MOS-Bench 和 SHEET,通过多个数据集以及引入新的评估指标来挑战 SSQA 的泛化问题。通过减少特定于数据集的偏差和跨域适用性,该方法将推动 SSQA 研究的前沿,使模型能够有效地在各个应用程序之间进行泛化。一个重要的进步是 MOS-Bench 及其标准化工具包收集了跨域数据集。更令人兴奋的是,研究人员现在可以使用这些资源来开发在存在各种语音类型和真实世界应用程序的情况下都具有鲁棒性的 SSQA 模型。
论文地址:https://arxiv.org/abs/2411.03715
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53792.html
