
AI 继续快速发展,但这种发展带来了一系列技术挑战,需要克服这些挑战才能真正蓬勃发展。当今最紧迫的挑战之一是推理性能。大型语言模型 (LLM)(例如基于 GPT 的应用程序中使用的模型)需要大量计算资源。
瓶颈发生在推理阶段,即经过训练的模型生成响应或预测的阶段。由于当前硬件解决方案的限制,此阶段通常面临约束,导致该过程缓慢、耗能且成本高昂。随着模型变得越来越大,传统的基于 GPU 的解决方案在速度和效率方面越来越不足,限制了 AI 在实时应用中的变革潜力。这种情况需要更快、更高效的解决方案来跟上现代 AI 工作负载的需求。
Cerebras Systems 推理速度提升 3 倍!Llama 3.1-70B 每秒可处理 2,100 个Token
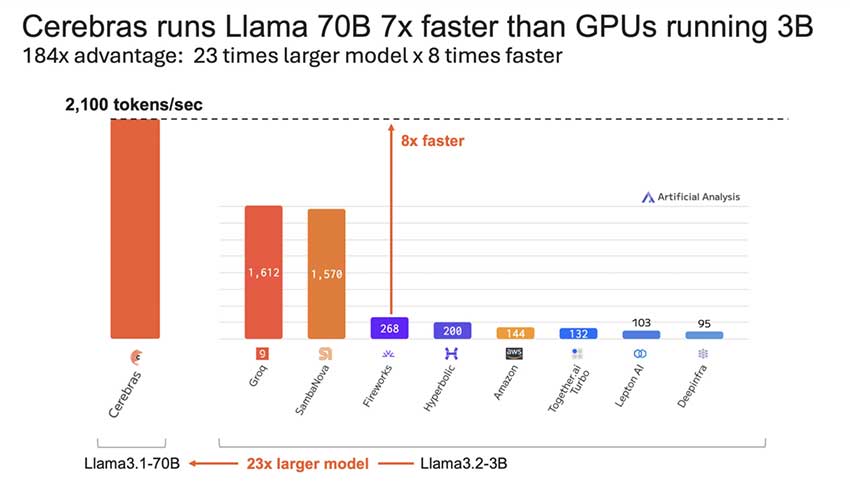
Cerebras Systems 取得了重大突破,声称其推理过程现在比以前快了三倍。具体来说,该公司使用 Llama 3.1-70B 模型实现了惊人的每秒 2,100 个 Token。这意味着 Cerebras Systems 现在比目前最快的 GPU 解决方案快 16 倍。这种性能飞跃类似于 GPU 技术的整整一代升级,例如从 NVIDIA A100 升级到 H100,但所有这些都是通过软件更新实现的。
此外,不仅仅是更大的模型受益于这种提升——Cerebras 的速度是运行小得多的 Llama 3.1-3B 的 GPU 的 8 倍,而 Llama 3.1-3B 的规模要小 23 倍。如此令人印象深刻的收益凸显了 Cerebras 为该领域带来的希望,即以前所未有的速度实现高速、高效的推理。
技术改进和优势
Cerebras 最新性能飞跃背后的技术创新包括多项底层优化,从根本上增强了推理过程。矩阵乘法 (MatMul)、reduce/broadcast 和元素级操作等关键内核已被完全重写并针对速度进行了优化。Cerebras 还实现了异步晶圆 I/O 计算,允许重叠数据通信和计算,确保最大程度地利用可用资源。
此外,还引入了高级推测解码,有效降低了延迟,同时又不牺牲生成的 token 的质量。此次改进的另一个关键方面是,Cerebras 保持了原始模型权重的 16 位精度,确保速度的提升不会损害模型的准确性。所有这些优化都经过了细致的人工分析验证,以确保它们不会降低输出质量,使 Cerebras 的系统不仅速度更快,而且值得企业级应用信赖。
变革潜力和实际应用
这种性能提升的影响是深远的,特别是考虑到 LLM 在医疗、娱乐和实时通信等领域的实际应用时。
制药巨头葛兰素史克强调,Cerebras 的推理速度提升如何从根本上改变他们的药物发现过程。葛兰素史克人工智能/机器学习高级副总裁 Kim Branson 表示,Cerebras 在人工智能方面的进步使智能研究代理能够更快、更有效地工作,在竞争激烈的医学研究领域提供了关键优势。
同样,支持 ChatGPT 语音模式的平台 LiveKit 的性能也得到了显著提升。LiveKit 首席执行官 Russ d’Sa 表示,他们人工智能流程中曾经最慢的步骤现在变成了最快的步骤。这种转变实现了实时语音和视频处理能力,为高级推理、实时智能应用打开了新的大门,并在不增加延迟的情况下实现了多达 10 倍的推理步骤。
数据显示,这些改进不仅仅是理论上的;他们正在积极重塑工作流程并减少跨行业的运营瓶颈。
结论
Cerebras Systems 再次证明了其致力于突破 AI 推理技术界限的决心。凭借 Llama 3.1-70B 模型,推理速度提高了三倍,每秒能够处理 2,100 个 token,Cerebras 为 AI 硬件的可能性设定了新的基准。通过专注于软件和硬件优化,Cerebras 正在帮助 AI 超越以前可实现的极限——不仅在速度方面,而且在效率和可扩展性方面。这一最新飞跃意味着更多实时、智能的应用程序、更强大的 AI 推理以及更流畅、更具互动性的用户体验。
更多详细信息请访问:https://cerebras.ai/blog/cerebras-inference-3x-faster
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53765.html
