
摘要:有效的点云压缩的关键在于获得与复杂的三维数据结构一致的鲁棒上下文模型。近年来,大语言模型(LLMs)的发展突显了它们不仅在上下文学习和生成方面表现出强大的预测能力,同时也是有效的压缩工具。LLMs的这种双重属性使其特别适合满足数据压缩的需求。因此,本文探讨了使用 LLM 进行压缩任务的潜力,重点研究了无损点云几何压缩(PCGC)实验。然而,将 LLM 直接应用于 PCGC 任务面临一些显著挑战,即 LLM 对点云结构的理解不足,通过文本描述来弥合文本和点云之间的差距非常困难,特别是在大规模、复杂或小型无明显形状的点云中。为了解决这些问题,我们提出了一种新的架构,即基于大语言模型的点云几何压缩方法(LLM-PCGC),利用 LLM 在没有任何文本描述或对齐操作的情况下压缩点云几何信息。通过使用不同的适应技术进行跨模态表示对齐和语义一致性,包括聚类、K树、token映射不变性和 LoRA,所提出的方法能够将 LLM 转化为点云的压缩器。据作者所述,这是第一个采用 LLM 作为点云数据压缩器的结构。实验表明,与 MPEG 几何点云压缩(G-PCC)标准基线相比,LLM-PCGC 实现了40.213%比特率的降低,并比最先进的基于学习的压缩方法实现了2.267%比特率的降低。
题目: LLM-PCGC: Large Language Model-based Point Cloud Geometry Compression
作者: Yuqi Ye, Wei Gao
文章来源: https://arxiv.org/abs/2408.08682
内容整理: 张俸玺
引言
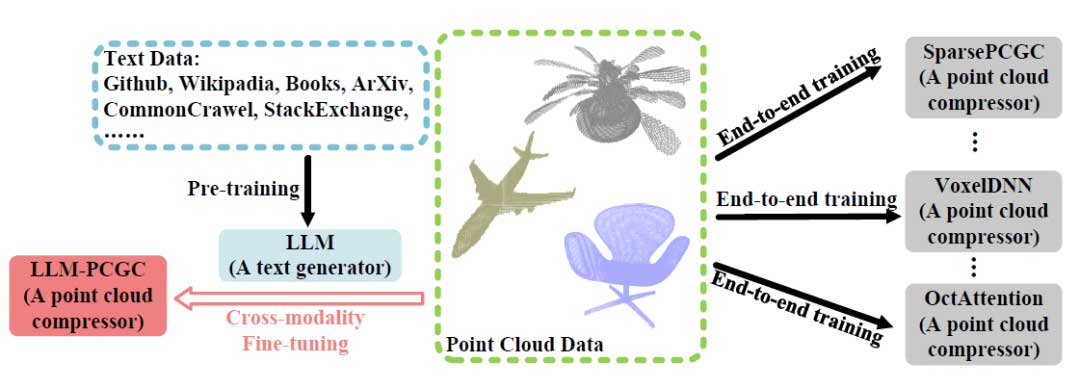
点云是一种对自动驾驶和虚拟现实至关重要且极具价值的数据结构。近年来,随着深度神经网络的发展,越来越多用于无损点云几何压缩(PCGC)任务的基于学习的架构被提出,并在无损 PCGC 任务中展示了显著的性能。这些方法可以分为两大类,即基于体素(voxel-based)的方法和基于树(tree-based)的方法。无论是基于体素的方法还是基于树的方法,压缩性能的关键在于建立一个强大且稳健的上下文模型。然而,由于数据量和模型规模的限制,之前方法的上下文能力仍然受到显著限制,这一点在大型语言模型(LLMs)的规模法则中已有讨论。这启发作者直接用具备大规模上下文和生成能力的 LLM 替换原始的上下文模型。
新兴观点表明,大型语言模型(LLMs)的本质在于其信息压缩能力。然而,以往的研究仅从压缩的角度讨论了 LLM 中紧凑的特征表示,忽视了 LLM 在数据压缩中的潜力。虽然在 Del’étang 等人(2024)的工作中,讨论了仅通过文本训练的 LLM 在 1D 和 2D 数据(包括文本、图像和语音)上实现无损压缩的能力,但从分析中得出了两点局限性:
- 1.该研究忽视了 3D 点云的压缩问题。与简单的 1D 和 2D 数据不同,3D 结构化数据需要更精细和强大的上下文模型。因此,作为一种更复杂的数据类型,点云具有独特的 3D 结构特性,这给压缩任务带来了新的挑战。
- 2.对 LLM 数据压缩能力的探索仅限于上下文学习,未进行任何附加参数训练。这表明 LLM 模型具备固有的数据压缩潜力,但在为压缩任务量身定制的训练后,其性能提升尚不明确。在本文中,作者提出了一种全新的架构,即基于大型语言模型的点云几何压缩方法(LLM-PCGC),该方法能够更好地适应无损点云几何压缩任务。
将基于文本的大型语言模型(LLM)转换为用于点云几何压缩的 LLM-PCGC 是一个跨模态问题。由于 LLM 是基于文本的模型,目前的多模态大型语言模型(MM-LLM)为了处理多模态数据,通常的做法是将其他模态的标记映射到文本空间,然后通过文本描述生成对应的模态数据(。一方面,对于编码任务,实际上并不需要文本数据,也不存在与多模态配对的文本数据。另一方面,使用 LLM 是因为其强大的生成能力和上下文理解能力,但对于编码任务而言,基于文本的特征是多余的。因此,作者希望去除文本特定的部分,同时保留其核心的生成和上下文功能。在本文中,作者首次通过令标记映射保持不变的方法,对预训练的 LLM 进行微调,以实现跨模态转换。
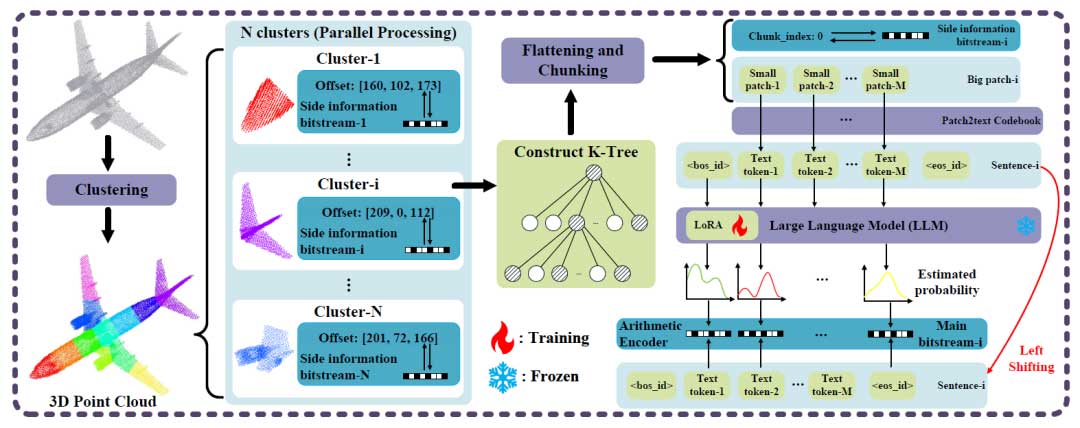
通过上述方法,作者提出了基于大型语言模型的点云几何压缩方法(LLM-PCGC)。如图 1 所示,本文的方法与现有的端到端深度学习训练方法进行了比较。作者提出的 LLM-PCGC 方法对一个预训练的文本生成 LLM 进行微调,使其适应点云数据,实现跨模态转换并用作点云压缩器。在编码阶段,首先对输入的 3D 点云进行聚类。接下来,每个聚类会通过一系列步骤并行处理。首先,通过减去偏移量对坐标进行归一化,并利用 K 树结构对点云数据进行系统化组织。然后,将层次树结构展开并划分为若干段。接着,使用一个码本将点云标记转换为文本标记,从而构建一个类似语言的句子。最后,使用一个冻结的 LLM 和经过训练的 LoRA 架构来预测下一个标记的概率分布,并与算术编码器结合,完成编码过程。解码阶段则按上述步骤的逆序操作,从编码数据中重建原始的点云几何信息。
本文的贡献总结:
- 本文提出了一种新颖的架构,即 LLM-PCGC,这是首个在“生成器即压缩器”框架内应用 LLM 进行点云压缩的架构。据作者所知,LLM-PCGC 也是首个无需文本信息辅助就能理解点云结构的大模型。
- 本文提出了不同的自适应技术以实现跨模态表示对齐和语义一致性,包括聚类、K 树、token 映射不变性和 LoRA。所提出的方法能够将 LLM 转化为点云的压缩器/生成器。token 映射不变性的方法可以迁移到其他模态,为 LLM 在多模态和跨模态应用中提供了一种新的范式。
- 实验表明,LLM-PCGC 显著优于现有方法,达到比 G-PCC -40.213% 的比特率减少率,较当前最先进的学习型方法实现 -2.267% 的比特率减少。作为首个基于 LLM 的点云压缩方法,所提出的 LLM-PCGC 方法取得了卓越的性能。
方法框架
编码工作流
编码阶段从输入 3D 点云的聚类开始,每个聚类块进行并行处理。该过程包含几个关键步骤,包括通过偏移量减法对坐标进行归一化;使用 K 树结构对数据进行组织;展平和分块层次化树结构,以及通过代码本将点云的 patch token 转换为文本 token。在此过程中,引入了特殊 token,例如 <bos id> 表示开始 token ID,<eos id> 表示结束 token ID,从而构造类似语言句子的结构。编码过程最终使用训练好的 LoRA 架构与冻结的大语言模型(LLM)结合,预测下一个 token 的概率分布,随后通过算术编码器进行编码。
解码工作流
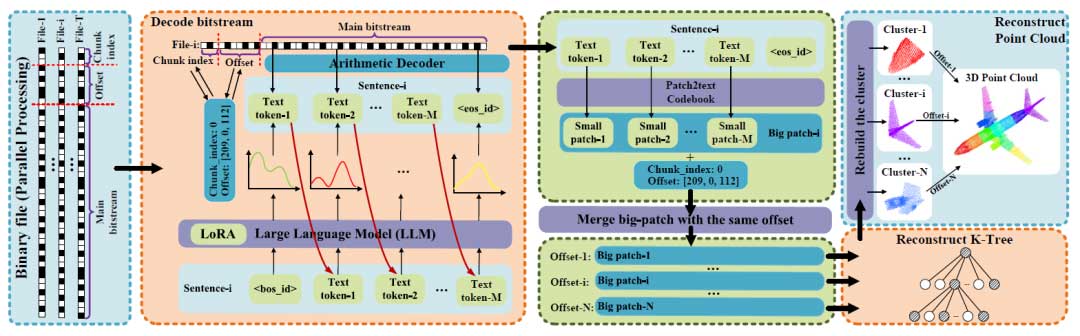
在解码阶段,对并行接收到的二进制文件进行分段,以识别每个比特流对应的偏移量、<chunk index> 和主比特流。这些标识符从二进制转换为十进制值,以便通过训练好的 LoRA 和冻结的大语言模型(LLM)处理主比特流,从而获得下一个 token 的概率分布,随后使用算术解码器进行解码。接下来,代码本将文本 token 转换回点云的 patch token,并根据它们的偏移量和 chunk 索引进行对齐和合并。一个算法被用来重建树结构和坐标。由于缺乏先前信息,该算法巧妙地通过统计 “1” 的数量来恢复坐标。最后,通过各自的偏移量调整聚类点云,重构出完整的点云,恢复到其原始形态。
实验
实验设置
数据处理:
鉴于目前的自回归方法、VoxelDNN、MSVoxelDNN 和 NNOC 在训练中使用 Microsoft Voxelized Upper Bodies (MVUB) 和 8i Voxelized Full Bodies (MPEG 8i) 数据集,以及其他方法(如 SparsePCGC)在 ShapeNet 数据集上进行训练,为了确保公平比较,作者在类似数据集上训练了两组 LLM-PCGC 参数。在与 SparsePCGC 的实验比较中,作者将 ModelNet40 点云数据分为 12 个聚类,然后将 3D 点云聚类按照 K=12 的 K 树结构进行组织进行训练。在测试中,作者遵循通用测试条件 (CTC),该条件建议使用两个公共数据集,即 MPEG 8i 和 Owlii 进行评估。
对于自回归方法(如 OctAttention、VoxelDNN、MSVoxelDNN 和 NNOC),作者采用了广泛使用的序列进行训练。具体而言,作者使用了 MVUB 数据集中的 Andrew10、David10 和 Sarah10 点云序列,以及 MPEG 8i 数据集中的 Longdress10 和 Soldier10 点云序列进行训练。对于选择的数据,作者进行了类似的聚类处理,聚类数为 240,K 树结构的 K 值为 12。在测试中,作者选择了 MPEG 8i 数据集中的 Thaidancer 和 Boxer 两个点云,这两个数据集的分辨率从 12 位降采样至 10 位。
模型微调:
基于 LLaMA-2-7B,这是一款开源的大型语言模型,其性能可以与 GPT-3相媲美,并且考虑到可用的硬件资源,作者选择了最小的模型 LLaMA2-7B 作为本实验的基础模型。如表 2 所示,表详细描述了 LLaMA2-7B 的 LoRA 和 Embedding 模块。可训练参数总量仅为原始 LLaMA2-7B 模型参数的 6.7%。作者提出的模型在 PyTorch 中开发,运行于配备 Intel Xeon Gold 6248R CPU 和仅 48GB 内存的 NVIDIA A40 GPU 的系统上。
实验结果
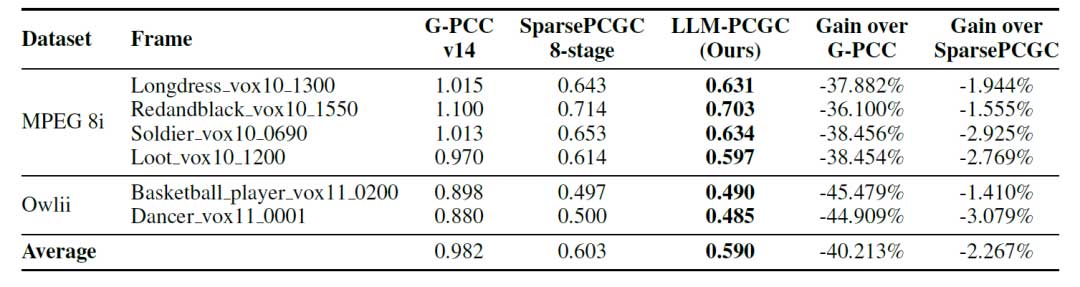
在与 SparsePCGC 的实验比较中,作者尝试使用相似的合成数据集 ModelNet40 复现 SparsePCGC,其每点比特数(bpp)性能结果列于表 1。对于 MPEG 8i 和 Owlii 数据集,作者提出的 LLM-PCGC 方法相比参考软件 G-PCC v14 平均实现了 40.213% 的比特率减少,Dancer vox11 0001 数据集的减少率达 44.909%,Basketball player vox11 0200 数据集达 45.479%。本文的方法还优于当前最先进的学习型方法 SparsePCGC,达到了 -2.267% 的比特率减少。

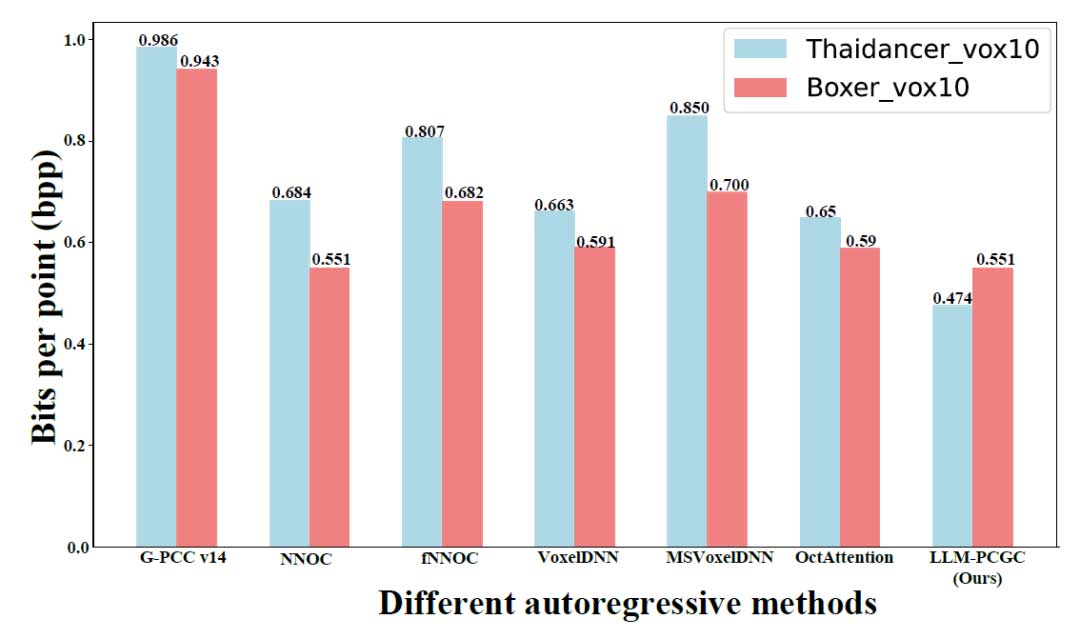
遗憾的是,由于缺少源代码和相关材料,作者无法复现其他自回归方法的结果。因此,本文在此直接引用了原始文献中报告的性能指标。需要注意的是,Thaidancer vox10 和 Boxer vox10 数据集作为其他自回归方法评估的共享测试集。因此,本文的实验也仅限于在这两个特定点云数据集上的压缩效果评估,结果如图 4 所示。在相同的 G-PCC 基准上,作者提出的 LLM-PCGC 实现了最低的 bpp 率。例如,对于 MPEG 8i 数据集,其记录的平均 bpp 为 0.52,比 MSVoxelDNN 和 fNNOC 的结果减少了 0.20 bpp。相比于 OctAttention 需要包含 1024 个邻近节点进行上下文建模,本文提出的 LLM-PCGC 利用了一种更稳健的上下文模型。显著的是,即使在缺少先前节点的情况下,它仍能比 OctAttention 减少 0.10 bpp。
结论
在本文中,作者提出了 LLM-PCGC,这是首个在“生成器即压缩器”框架下将 LLM 用作点云压缩任务压缩器的方法。作者采用了不同的适应技术,例如聚类、K树、token映射不变性和 LoRA,以实现高效的跨模态表示对齐和语义一致性。在无需任何文本数据的情况下,文本生成器可以转化为点云压缩器。实验结果表明,所提出的LLM-PCGC方法在压缩性能上优于 G-PCC 和当前最先进的基于深度学习的压缩方法,展示了 LLMs 在数据压缩中的潜力。尽管作为首次开发基于 LLM 的点云压缩方法的尝试,所提出的 LLM-PCGC 方法已经取得了优异的性能,但未来的研究可以在优化 LLMs 的过高内存消耗和推理时间过长问题上继续努力。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
