
视频生成已迅速成为人工智能研究的焦点,尤其是在生成时间一致、高保真视频方面。该领域涉及创建保持帧间视觉连贯性并随时间保留细节的视频序列。机器学习模型,尤其是扩散变换器 (DiT),已成为这些任务的强大工具,在质量上超越了 GAN 和 VAE 等先前的方法。然而,随着这些模型变得复杂,生成高分辨率视频的计算成本和延迟已成为一项重大挑战。研究人员现在专注于提高这些模型的效率,以便在保持质量标准的同时实现更快的实时视频生成。
视频生成中一个紧迫的问题是当前高质量模型的资源密集型性质。生成复杂、视觉上吸引人的视频需要强大的处理能力,尤其是处理较长、高分辨率视频序列的大型模型。这些要求减慢了推理过程,使得实时生成具有挑战性。许多视频应用程序需要能够快速处理数据同时仍能跨帧提供高保真度的模型。一个关键问题是找到处理速度和输出质量之间的最佳平衡,因为更快的方法通常会损害细节。相比之下,高质量方法往往计算量大且速度慢。
随着时间的推移,人们引入了各种方法来优化视频生成模型,旨在简化计算过程并减少资源使用。分步精炼、潜在扩散和缓存等传统方法为实现这一目标做出了贡献。例如,分步精炼通过将复杂任务压缩为更简单的形式来减少实现质量所需的步骤数。同时,潜在扩散技术旨在提高整体质量与延迟比。缓存技术存储先前计算的步骤以避免冗余计算。然而,这些方法有局限性,例如需要更大的灵活性来适应每个视频序列的独特特征。这通常会导致效率低下,尤其是在处理复杂性、运动和纹理差异很大的视频时。
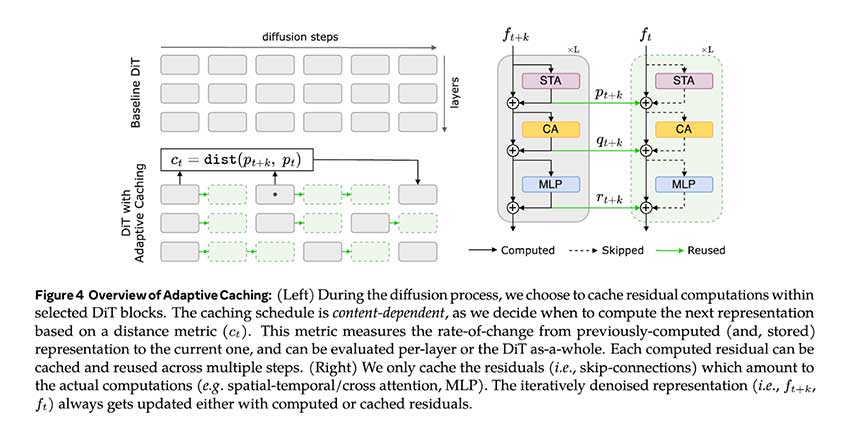
Meta AI 和纽约州立大学石溪分校的研究人员推出了一种名为自适应缓存(AdaCache)的创新解决方案,无需额外训练即可加速视频扩散变换器。AdaCache 是一种无需训练的技术,可集成到各种视频 DiT 模型中,通过动态缓存计算来简化处理时间。通过适应每个视频的独特需求,AdaCache 可以将计算资源分配到最有效的地方。AdaCache 可在保持视频质量的同时优化延迟,是一种灵活、即插即用的解决方案,可提高不同视频生成模型的性能。
AdaCache 通过在 Transformer 架构中缓存某些残差计算来运行,从而允许这些计算在多个步骤中重复使用。这种方法特别有效,因为它避免了冗余处理步骤,这是视频生成任务中常见的瓶颈。该模型使用针对每个视频量身定制的缓存计划来确定重新计算或重复使用残差数据的最佳点。该计划基于评估跨帧数据变化率的指标。
此外,研究人员在 AdaCache 中加入了运动正则化 (MoReg) 机制,该机制将更多的计算资源分配给需要更精细关注细节的高运动场景。通过使用轻量级距离度量和基于运动的正则化因子,AdaCache 平衡了速度和质量之间的权衡,根据视频的运动内容调整计算重点。
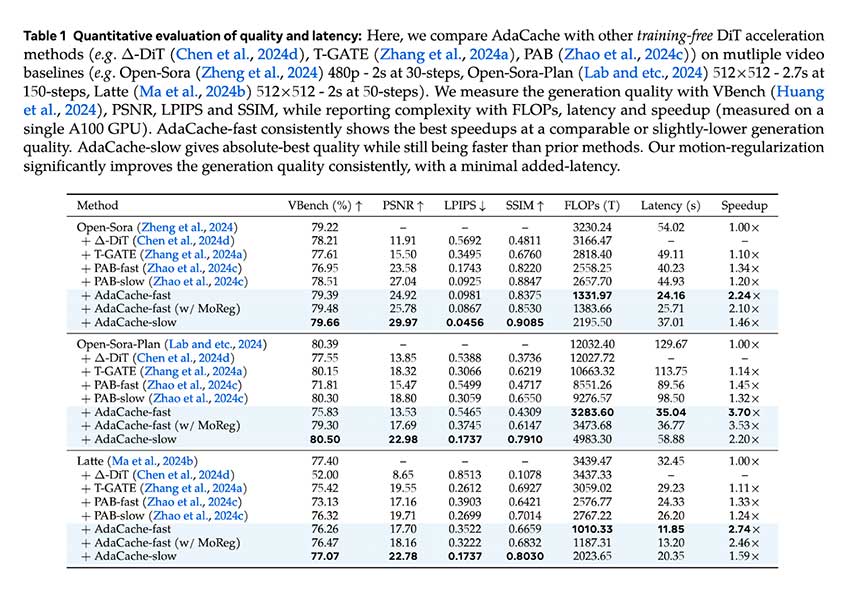
研究团队进行了一系列测试来评估 AdaCache 的性能。结果表明,AdaCache 显著提高了多种视频生成模型的处理速度和质量保持率。例如,在涉及 Open-Sora 的 720p 2 秒视频生成的测试中,AdaCache 的速度比以前的方法提高了 4.7 倍,同时保持了相当的视频质量。
此外,AdaCache 的变体,如“AdaCache-fast”和“AdaCache-slow”,提供了基于速度或质量需求的选项。借助 MoReg,AdaCache 展示了增强的质量,与人类在视觉评估中的偏好紧密结合,并且优于传统的缓存方法。不同 DiT 模型上的速度基准也证实了 AdaCache 的优势,根据配置和质量要求,加速比从 1.46 倍到 4.7 倍不等。
总之,AdaCache 标志着视频生成领域的重大进步,为平衡延迟和视频质量这一长期存在的问题提供了灵活的解决方案。通过采用自适应缓存和基于运动的正则化,研究人员提供了一种高效实用的方法,适用于实时高质量视频制作中的各种实际应用。AdaCache 的即插即用特性使其能够增强现有的视频生成系统,而无需进行大量的重新训练或定制,使其成为未来视频生成的有前途的工具。
论文地址:https://arxiv.org/abs/2411.02397
项目地址:https://github.com/AdaCache-DiT/AdaCache
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53677.html
