
理解和分析长视频一直是人工智能领域的一大挑战,这主要是因为需要大量的数据和计算资源。由于上下文长度有限,传统的多模态大型语言模型 (MLLM) 难以处理大量视频内容。这一挑战对于长达一小时的视频尤其明显,这些视频需要数十万个标记来表示视觉信息——通常超过甚至先进硬件的内存容量。因此,这些模型难以提供一致且全面的视频理解,从而限制了它们在现实世界中的应用。
Meta AI 发布 LongVU
Meta AI 发布了 LongVU,这是一款 MLLM,旨在解决在常用上下文长度内理解长视频的挑战。LongVU 采用时空自适应压缩机制,可智能地减少视频标记的数量,同时保留必要的视觉细节。通过结合使用 DINOv2 功能和跨模态查询,LongVU 可有效减少视频数据中的空间和时间冗余,从而能够在不丢失关键信息的情况下处理长视频序列。
LongVU 使用由文本查询引导的选择性帧特征减少方法,并利用 DINOv2 的自监督特征来丢弃冗余帧。与传统的均匀采样技术相比,此方法具有显著优势,传统的均匀采样技术要么因丢弃关键帧而导致重要信息丢失,要么因保留过多标记而导致计算不可行。由此产生的 MLLM 具有轻量级设计,使其能够高效运行并在视频理解基准上取得最佳结果。
LongVU 的技术细节和优势
LongVU 的架构结合了 DINOv2 特征以进行帧提取、通过文本引导的跨模态查询选择性地减少帧特征以及基于时间依赖性的空间标记减少。首先,DINOv2 的特征相似性目标用于消除冗余帧,从而减少标记数量。然后,LongVU 应用跨模态查询来优先考虑与输入文本查询相关的帧。对于剩余的帧,空间池化机制进一步减少标记表示,同时保留最重要的视觉细节。
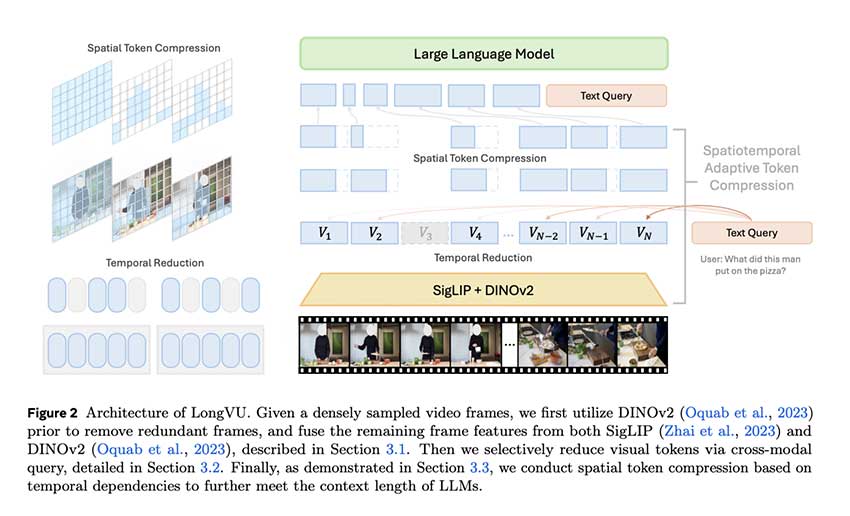
这种方法即使在处理长达一小时的视频时也能保持高性能。空间标记减少机制可确保在消除冗余数据的同时保留必要的空间信息。LongVU 处理每秒一帧 (1fps) 采样的视频输入,有效地将每帧的标记数量减少到平均两个,从而可以在 8k 上下文长度内容纳长达一小时的视频序列——这是 MLLM 的常见限制。该架构在标记减少与关键视觉内容的保留之间取得平衡,使其在长视频处理中非常高效。
LongVU 的重要性和性能
LongVU 克服了大多数 MLLM 面临的上下文长度有限的根本问题,代表了长视频理解领域的重大突破。通过时空压缩和有效的跨模态查询,LongVU 在关键视频理解基准上取得了令人瞩目的成绩。例如,在 VideoMME 基准上,LongVU 的整体准确率比强大的基线模型 LLaVA-OneVision 高出约 5%。即使使用 Llama3.2-3B 语言主干缩减为轻量级版本,LongVU 也表现出了显著的进步,在长视频任务中比之前最先进的模型提高了 3.4%。
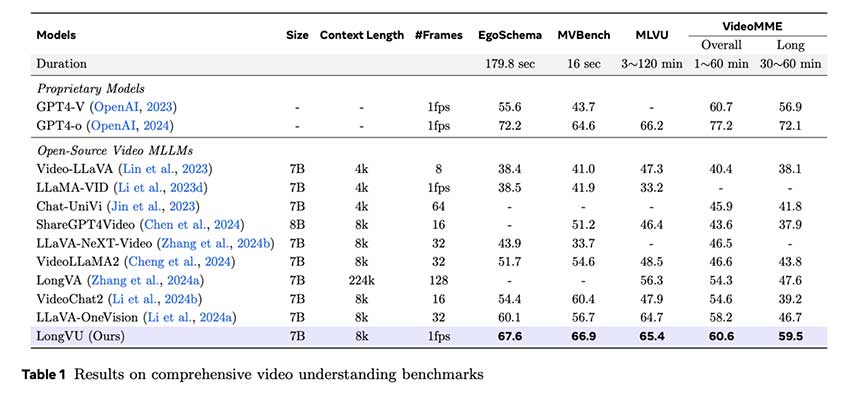
LongVU 的稳健性在其与 GPT-4V 等专有模型的竞争结果中得到了进一步的凸显。在 MVBench 评估集上,LongVU 不仅缩小了与 GPT-4V 的性能差距,而且在某些情况下甚至超过了它,证明了其在理解密集采样视频输入方面的有效性。这使得 LongVU 对于需要实时视频分析的应用(例如安全监控、体育分析和基于视频的教育工具)特别有价值。
结论
Meta AI 的 LongVU 是视频理解领域的一大进步,尤其是对于长篇内容。通过使用时空自适应压缩,LongVU 有效地解决了处理具有时间和空间冗余的视频的挑战,为长视频分析提供了有效的解决方案。其在基准测试中的卓越性能凸显了其相对于传统 MLLM 的优势,为更高级的应用铺平了道路。
LongVU 凭借其轻量级架构和高效压缩,将高级视频理解扩展到各种用例,包括移动和低资源环境。通过降低计算成本而不影响准确性,LongVU 为未来的 MLLM 树立了新标准。
论文地址:https://huggingface.co/Vision-CAIR/LongVU_Qwen2_7B
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53471.html
