
视觉语言模型(VLM)因其整合视觉和文本数据的能力而在人工智能领域日益突出。这些模型在视频理解、人机交互和多媒体应用等领域发挥着至关重要的作用,提供了根据视频输入回答问题、生成字幕和增强决策的工具。随着从自主系统到娱乐和医疗应用等各行各业基于视频的任务越来越多,对高效视频处理系统的需求也在不断增长。尽管取得了进步,但处理视频中的大量视觉信息仍然是开发可扩展和高效 VLM 的核心挑战。
视频理解中的一个关键问题是,现有模型通常依赖于单独处理每个视频帧,从而生成成千上万的视觉标记。这一过程需要消耗大量的计算资源和时间,限制了模型高效处理长视频或复杂视频的能力。我们面临的挑战是在捕捉相关视觉和时间细节的同时减少计算负荷。如果没有解决方案,需要实时或大规模视频处理的任务就变得不切实际,因此需要兼顾效率和准确性的创新方法。
目前的解决方案试图通过跨帧池化等技术来减少视觉标记的数量。Video-ChatGPT 和 Video-LaVA 等模型侧重于空间和时间汇集机制,将帧级信息压缩为更小的标记。然而,这些方法仍会产生许多标记,MiniGPT4-Video 和 LLaVA-OneVision 等模型会产生数千个标记,导致较长视频的处理效率低下。这些模型通常需要帮助来优化标记效率和视频处理性能,因此需要更有效的解决方案来简化标记管理。
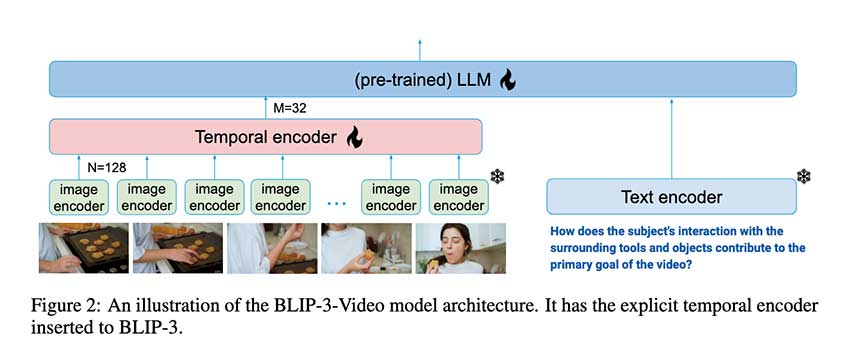
为了应对这一问题,Salesforce AI Research 的研究人员推出了 BLIP-3-Video,这是一种先进的 VLM,专门用于解决视频处理效率低下的问题。该模型集成了一个“时间编码器”,可大幅减少表示视频所需的视觉标记。通过将标记数量限制为 16 到 32 个标记,该模型可显著提高计算效率,而不会牺牲性能。这一突破使 BLIP-3-Video 能够以更低的计算成本执行基于视频的任务,这使其成为可扩展视频理解解决方案的突破性一步。
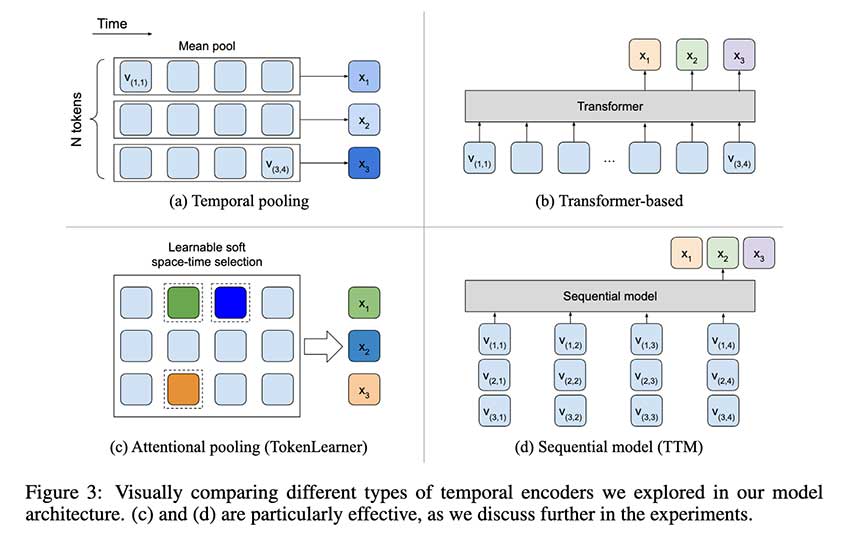
BLIP-3-Video 中的时间编码器是其更高效处理视频的关键。它采用可学习的时空注意力池机制,仅提取视频帧中最具信息量的标记。该系统整合了每帧的空间和时间数据,将它们转换为一组紧凑的视频级标记。该模型包括一个视觉编码器、一个帧级标记器和一个根据视频输入生成文本或答案的自回归语言模型。时间编码器使用顺序模型和注意力机制来保留视频的核心信息,同时减少冗余数据,确保 BLIP-3-Video 能够高效处理复杂的视频任务。
性能结果表明,与大型模型相比,BLIP-3-Video 具有更高的效率。该模型实现了与 Tarsier-34B 等最先进模型类似的视频问答 (QA) 准确率,同时仅使用一小部分视觉标记。例如,Tarsier-34B 对 8 个视频帧使用 4608 个标记,而 BLIP-3-Video 将这个数字减少到仅 32 个标记。尽管有所减少,BLIP-3-Video 仍然保持强劲性能,在 MSVD-QA 基准上获得了 77.7% 的分数,在 MSRVTT-QA 基准上获得了 60.0% 的分数,这两个基准都是用于评估基于视频的问答任务的广泛使用的数据集。这些结果强调了该模型能够在使用更少资源的情况下保持高水平的准确率。
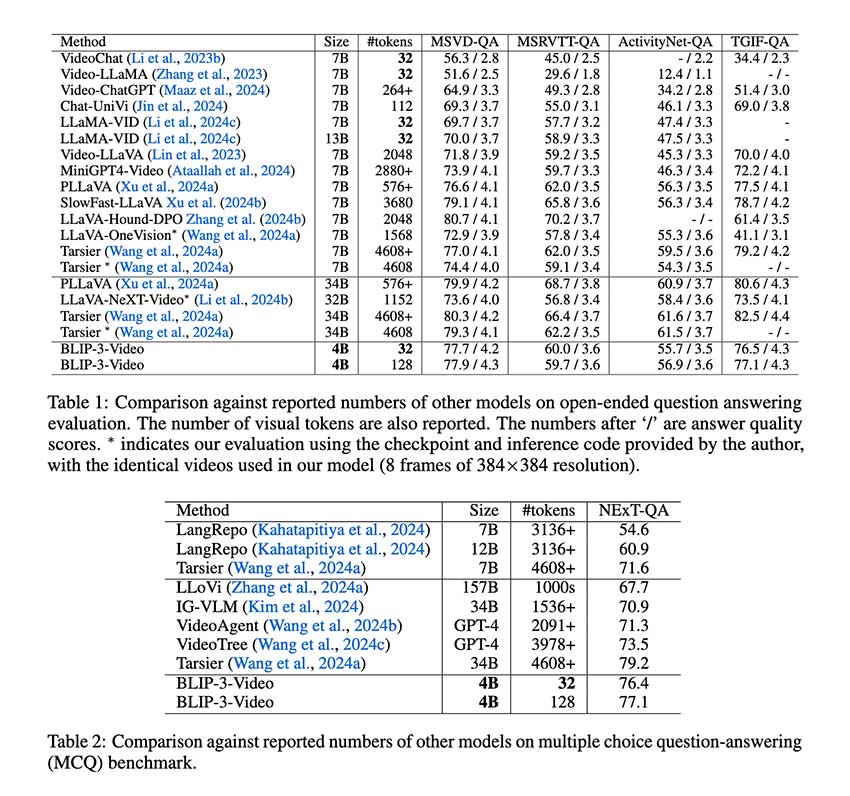
该模型在多项选择问答任务(例如 NExT-QA 数据集)上表现优异,得分为 77.1%。这一点尤其值得注意,因为它每个视频仅使用 32 个标记,比许多竞争模型少得多。此外,在需要理解视频中的动态动作和过渡的 TGIF-QA 数据集上,该模型实现了令人印象深刻的 77.1% 的准确率,进一步凸显了其在处理复杂视频查询方面的效率。这些结果确立了 BLIP-3-Video 是目前最高效的标记效率模型之一,提供与大型模型相当或更高的准确率,同时大幅降低计算开销。
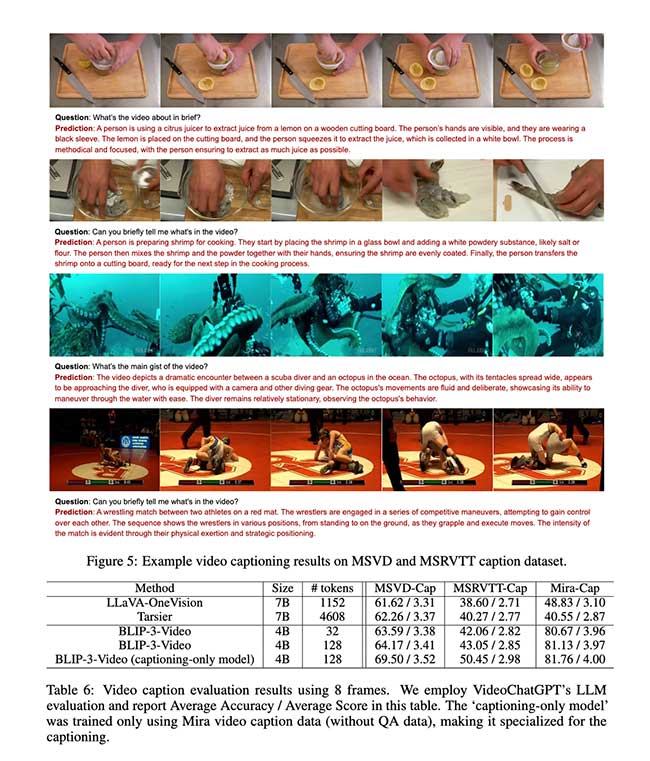
总之,BLIP-3-Video 通过引入创新的时间编码器解决了视频处理中 token 效率低下的挑战,该编码器在保持高性能的同时减少了视觉 token 的数量。该模型由 Salesforce AI Research 开发,表明使用比之前认为的更少的 token 来处理复杂的视频数据是可能的,为视频理解任务提供了更具可扩展性和效率的解决方案。这一进步代表了视觉语言模型向前迈出的重要一步,为 AI 在各个行业基于视频的系统中更实际的应用铺平了道路。
论文地址:https://arxiv.org/abs/2410.16267
项目地址:https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53332.html
