
语音识别技术已成为各种现代应用中的关键,尤其是实时转录和语音激活命令系统。它对于听力障碍人士的辅助工具、演示期间的实时字幕以及智能设备中的语音控制至关重要。这些应用需要即时、精确的反馈,而这些反馈通常发生在计算能力有限的设备上。随着这些技术扩展到更小、更具成本效益的硬件,对高效、快速的语音识别系统的需求变得更加关键。在没有稳定互联网连接的情况下运行的设备面临着额外的挑战,因此有必要开发能够在这种受限环境中正常运行的解决方案。
实时语音识别的主要挑战之一是减少延迟,即说出的单词与其转录之间的延迟。传统模型需要帮助来平衡速度和准确性,尤其是在计算资源有限的环境中。对于需要近乎即时结果的应用程序,转录中的任何延迟都会严重影响用户体验。此外,许多现有系统以固定长度的块处理音频,而不管语音的实际长度如何,这会导致不必要的计算工作。虽然这种方法适用于较长的音频片段,但在处理较短或长度不一的输入时会导致效率低下,造成不必要的延迟并降低性能。
OpenAI 的 Whisper 因其准确性而成为通用语音识别的首选模型。然而,它采用固定长度的编码器,以 30 秒为单位处理音频,因此需要对较短的序列进行零填充。这种填充会产生恒定的计算开销,即使音频输入短得多,也会增加整体处理时间并降低效率。尽管 Whisper 的准确性很高,尤其是对于长篇转录,但它很难满足实时反馈至关重要的设备端应用程序的低延迟需求。
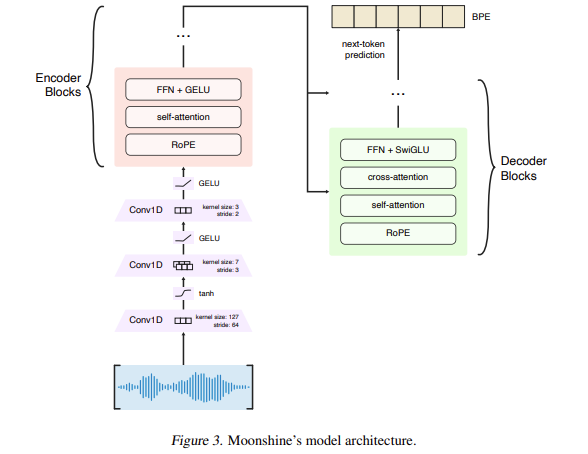
Useful Sensors 的研究人员推出了 Moonshine 系列语音识别模型来解决这些低效率问题。Moonshine 模型采用可变长度编码器,可将计算处理缩放到音频输入的实际长度,从而避免使用零填充。这一突破使模型能够更快、更高效地运行,尤其是在资源受限的环境中,例如低成本设备。Moonshine 旨在匹配 Whisper 的高转录准确度,但计算需求显著降低,使其成为实时转录任务的更合适选择。通过采用旋转位置嵌入 (RoPE) 等先进技术,该模型可确保高效处理每个语音段,从而提高整体性能。
Moonshine 的核心架构基于编码器-解码器转换器模型,该模型消除了传统的手工设计特征,例如梅尔频谱图。相反,Moonshine 直接处理原始音频输入,使用三个卷积层将音频压缩 384 倍,而 Whisper 的压缩率为 320 倍。此外,Moonshine 还使用来自公开 ASR 数据集的超过 90,000 小时的综合数据集进行训练,另外还使用来自研究人员数据集的 100,000 小时,总计 200,000 小时的训练数据。这个庞大而多样化的数据集使 Moonshine 能够以更高的准确率处理各种音频输入,从不同的长度到不同的口音。
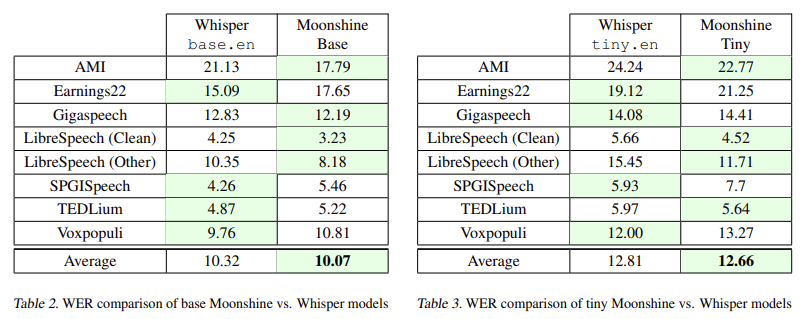
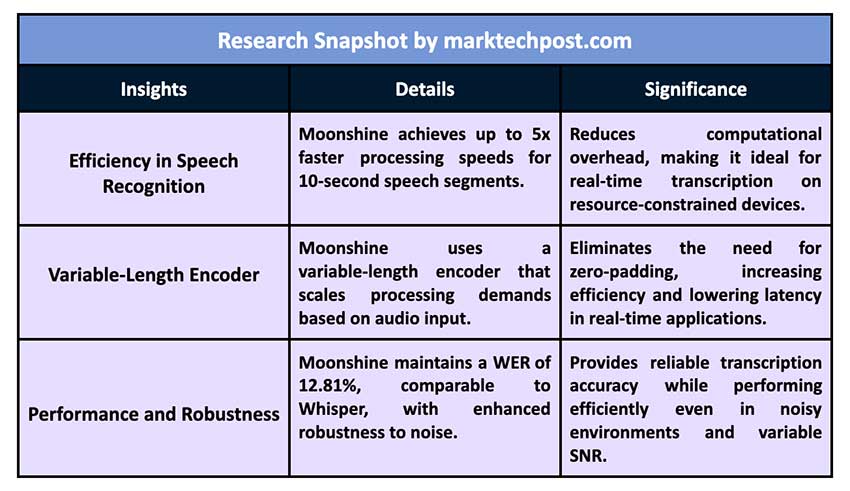
与 OpenAI 的 Whisper 进行测试时,结果表明 Moonshine 在 10 秒语音片段的处理速度上最高可提高五倍,且词错误率 (WER) 并未增加。例如,Moonshine Tiny 是该系列中最小的模型,与 Whisper Tiny 相比,其计算需求减少了五倍,同时保持了相似的 WER 分数。在具体基准测试中,Moonshine 模型在大多数数据集中的表现均优于 Whisper,包括 LibriSpeech、TEDLIUM 和 GigaSpeech,并且不同音频时长的 WER 更低。Moonshine Tiny 的平均 WER 为 12.81%,而 Whisper Tiny 的 WER 为 12.66%。虽然这两个模型的表现相似,但 Moonshine 的优势在于其对较短输入的处理速度和可扩展性。
研究人员还强调了 Moonshine 在嘈杂环境中的表现。在针对信噪比 (SNR) 各异的音频(例如来自计算机风扇的背景噪音)进行评估时,Moonshine 在较低的 SNR 水平下仍保持了出色的转录准确度。Moonshine 对噪声的稳健性,加上其有效处理可变长度输入的能力,使它成为即使在不太理想的条件下也需要高性能的实时应用的理想解决方案。
关于 Moonshine 的研究得出的关键结论是:
- 对于 10 秒语音片段,Moonshine 模型的处理速度比 Whisper 模型快 5 倍。
- 可变长度编码器消除了零填充的需要,从而减少了计算开销。
- Moonshine 接受了 200,000 小时数据的训练,包括开放数据和内部收集的数据。
- 最小的 Moonshine 模型(Tiny)在各种数据集中保持了 12.81% 的平均 WER,与 Whisper Tiny 的 12.66% 相当。
- Moonshine 模型表现出对噪声和不同 SNR 水平的卓越鲁棒性,使其成为资源受限设备上实时应用的理想选择。
总之,研究团队解决了实时语音识别的一个重大挑战:在保持准确性的同时减少延迟。Moonshine 模型通过使用随音频输入长度缩放的可变长度编码器,为传统 ASR 模型(如 Whisper)提供了一种高效的替代方案。这项创新可提高处理速度、降低计算需求并实现相当的准确性,使 Moonshine 成为低资源环境的理想解决方案。通过在广泛的数据集上进行训练并使用尖端的 Transformer 架构,研究人员开发了一系列模型,这些模型非常适用于现实世界的语音识别任务,从实时转录到智能设备集成。
论文地址:https://arxiv.org/abs/2410.15608
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53292.html
