

研究团队
杨勋:中国科学技术大学信息科学技术学院
曾建明:中国科学技术大学先进技术研究院&合肥综合性国家科学中心人工智能研究院
王姗姗:安徽大学物质科学与信息技术研究院
董建锋:浙江工商大学计算机科学与技术学院
郭丹、汪萌:合肥工业大学计算机与信息学院
文章下载
Xun YANG, Jianming ZENG, Dan GUO, Shanshan WANG, Jianfeng DONG & Meng WANG. Robust video question answering via contrastive cross-modality representation learning. Sci China Inf Sci, 2024, 67(10): 202104, doi: 10.1007/s11432-023-4084-6
链接:https://www.sciengine.com/SCIS/doi/10.1007/s11432-023-4084-6;JSESSIONID=8a3b471b-4f44-49b2-824b-ba7748c23ffb
研究意义
视频问答是一个具有挑战性且很重要的多媒体理解任务,其需要对底层的视觉内容和高层的文本语义进行综合理解,进而做出正确的决策。得益于其在室内机器人以及个人助理等应用场景中的潜力,视频问答任务在近几年多媒体和自然语言处理等领域的受到越来越多的研究关注。尽管该任务已取得一定的研究进展,但研究发现当前的视频问答系统存在过于依赖数据集中由数据偏见引发的伪关联关系的问题,忽视了对关键视频内容的理解,导致了不可靠的问答结果。因此,如何有效地理解并建模视频中的时序以及语义特性对于构建一个鲁棒的视频问答系统至关重要,但截止目前仍然缺乏足够的研究。
本文工作
基于上述考虑,本文提出了一种鲁棒的视频问答框架,旨在迫使模型能够更加有效地建模和利用视频时序语义以及综合理解文本和视觉信息,避免过于依赖统计关联信息,进而能够更好地进行跨模态推理,提升视频问答系统鲁棒性。
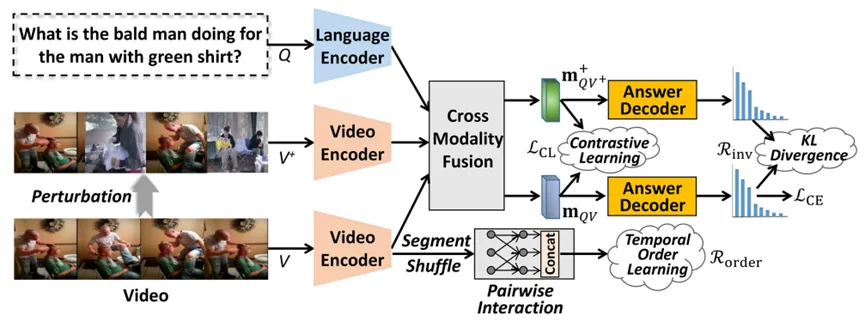
如图1所示,首先,我们引入了一个自监督的对比学习项,通过对视频片段进行随机替换扰动来构建对比学习的正样本对,迫使模型在跨模态交互融合时更加关注视频的全局上下文信息,而不是某些静态关键帧。其次,我们设计了一个时序正则项,旨在让模型学习到的视频表征能够保留视频固有的序列结构特性。另外,我们设计了一个基于Kullback-Leibler散度的扰动不变正则项,可以约束答案分布对视频扰动的敏感度,旨在学习一个扰动不变的视频表征,进而提高模型对视频局部扰动的鲁棒性。最终,将以上所述一个对比学习项和两个正则项结合起来,用来辅助视频问答常规的基于交叉熵损失的优化项,进行模型训练。本文模型最终学习到的视频表征能够较好地保留视频事件的时序上下文信息,并对视频局部的扰动相对鲁棒,提升了视频问答的可靠性。
本文的创新点如下:
(1) 本文提出了一种有效地、能够兼容其他模型的视频问答框架,旨在迫使视频问答模型能够关注更重要的视频内容(比如动作、事件等),而不是过于依赖由数据集偏见导致的伪关联关系,从而进行更可靠的跨模态答案推理。
(2) 本文设计了三个简单且有效的学习目标项,可以容易地与现有的视频问答方法进行结合,较为明显地提升现有视频问答方法的鲁棒性。
(3) 本文在多个标准视频问答数据集上,利用4个视频问答方法,对本文所提出的策略的模型兼容性、有效性进行了较为充分的实验评估,验证了本文方法的有效性。
实验结果
本文在MSVD-QA、MSRVTT-QA、Traffic-QA和NExT-QA四个常用的视频问答数据集上对本文提出的方法进行了实验评估。
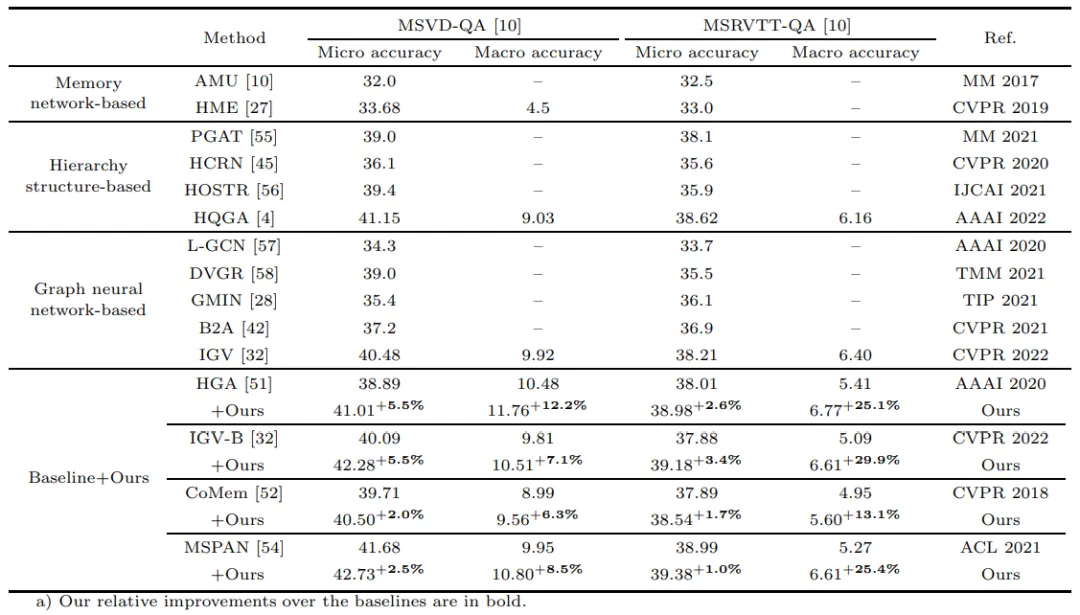
在两个开放式的问答数据集MSVD-QA和MSRVTT-QA上,本文采用Micro得分和Macro得分两个评估指标,可以在数据不平衡的条件下更好地对问答精确度进行评估。如表1所示,我们的方法可以较好地与4个现有的视频问答方法(HGA、IGV-B、CoMem和MSPAN)进行结合,在两个得分指标上都取得了稳定的提升。相比之下,本文的方法在Macro得分指标上,取得了更高的相对性能提升,显示了本文方法在不平衡问答数据集的有效性和稳定性。
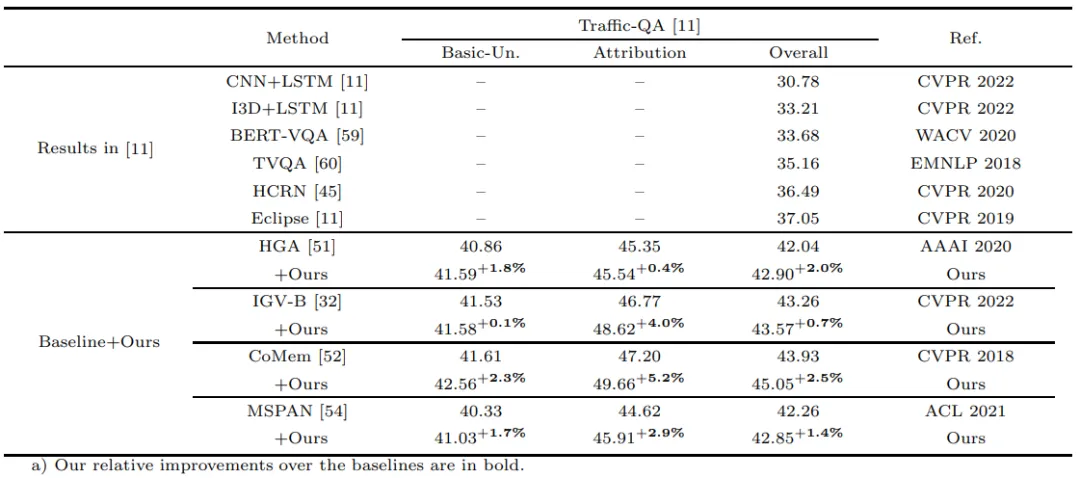
如表2所示,在多选项的交通场景问答数据集Traffic-QA上,本文方法也取得了较好的性能提升,尤其是在归因(Attribution)子集上,我们的性能提升较为明显,反映我们的方法可以使模型更好地感知视频活动的因果关系,比如在回答“什么导致了此次事故?”此类问题上,表现优异。
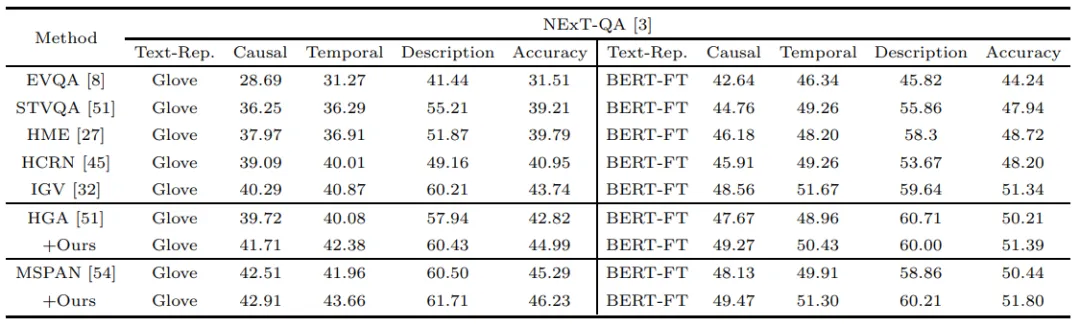
如表3所示,在多选项的NExT-QA数据集上,本文使用了两种不同的文本表征方式,我们观察到我们的方法在与HGA和MSPAN结合以后,在3个测试子集上均取得了较为明显的性能提升,反映了本文方法的有效性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
