
尽管多模态大型语言模型 (MLLM) 近期取得了进展,但这些模型的开发主要围绕英语和以西方为中心的数据集。这种侧重导致语言和文化代表性存在巨大差距,全球许多语言和文化背景仍未得到充分代表。因此,现有模型在多语言环境中通常表现不佳,并且不符合代表性不足语言的社会文化规范。这带来了巨大的限制,尤其是考虑到这些模型在全球范围内的采用日益广泛,而公平的代表性对于有效的实际应用至关重要。
卡内基梅隆大学的研究人员团队推出了 PANGEA,这是一种多语言多模态语言模型 (LLM),旨在弥合视觉理解任务中的语言和文化差距。PANGEA 是在新整理的数据集 PANGEAINS 上进行训练的,该数据集包含 39 种语言的 600 万个教学样本。该数据集经过精心设计,通过结合高质量的英语教学、机器翻译教学和文化相关的多模态任务来提高跨文化覆盖率。此外,为了评估 PANGEA 的能力,研究人员推出了 PANGEABENCH,这是一个涵盖 14 个数据集的评估套件,涵盖 47 种语言。这项全面评估深入了解了该模型在多模态和多语言任务上的表现,表明 PANGEA 在多语言场景中的表现优于许多现有模型。
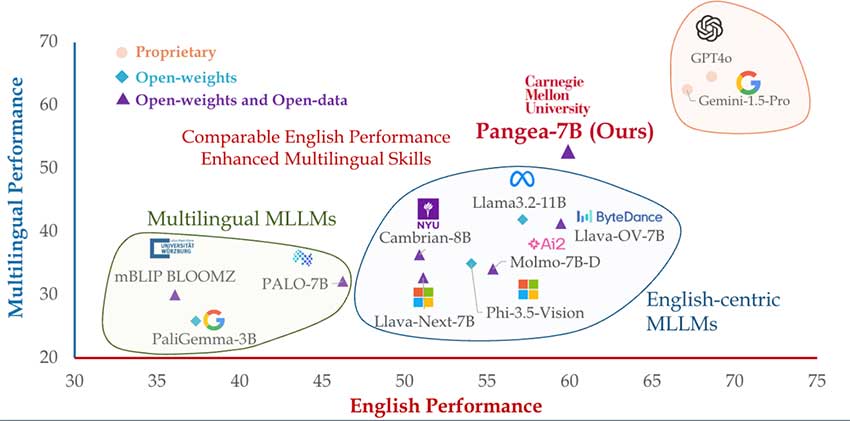
PANGEA 是使用 PANGEAINS 开发的,PANGEAINS 是一个丰富多样的数据集,其中包括一般视觉理解、文档和图表问答图像字幕等指令。该数据集旨在解决多语言多模式学习的主要挑战:数据稀缺、文化差异、灾难性遗忘和评估复杂性。为了构建 PANGEAINS,研究人员采用了几种策略:翻译高质量的英文指令、生成文化意识任务以及整合现有的开源多模式数据集。研究人员还开发了一个复杂的管道来过滤文化多样化的图像并生成详细的多语言和跨文化字幕,确保模型能够在不同的语言和文化背景下理解并做出适当的反应。
PANGEA 在 PANGEABENCH 上的评估结果充分展现了其优势。70 亿参数模型 PANGEA-7B 相比现有开源模型有显著提升,在英语任务上平均提升 7.3 分,在多语言任务上平均提升 10.8 分。PANGEA 在多元文化理解方面也表现出色,这一点从其在 CVQA 和 xChat 基准上的表现就可以看出。有趣的是,该模型在多语言设置下的性能下降幅度并不像其他模型那么大,这表明其跨语言能力均衡。此外,PANGEA 在多个领域的表现与 Gemini-1.5-Pro 和 GPT4o 等专有模型相当甚至更好,表明它是多语言 MLLM 领域的强大竞争对手。
PANGEA 代表着在创建包容性和强大的多语言多模式 LLM 方面迈出了重要一步。研究人员利用机器翻译和文化意识数据生成策略成功解决了数据稀缺和文化表征挑战,创建了一个涵盖 39 种语言的综合数据集。PANGEAINS、PANGEABENCH 和 PANGEA 模型的开源有望促进该领域的进一步发展和创新,促进跨语言和文化界限的公平性和可访问性。尽管其性能令人鼓舞,但仍有需要改进的地方,例如提高多模式聊天和复杂推理任务的性能,研究人员希望在未来的迭代中解决这些问题。
论文地址:https://arxiv.org/abs/2410.16153
项目地址:https://neulab.github.io/Pangea/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53246.html
