
当前的生成式 AI 模型面临着与稳健性、准确性、效率、成本以及处理细微的类人反应相关的挑战。我们需要更具可扩展性和效率的解决方案,这些解决方案既能提供精确的输出,又能适用于各种 AI 应用。
Nvidia 推出了 Nemotron 70B 模型,旨在为大型语言模型 (LLM) 领域提供新的基准。Nemotron 70B 是 Llama 3.1 系列的一部分,它悄然问世,并没有像往常那样高调发布。尽管如此,它的影响却是巨大的,它专注于整合最先进的架构改进,以在处理速度、训练效率和输出准确性方面超越竞争对手。Nemotron 70B 旨在让企业和开发人员能够轻松使用复杂的 AI 功能,从而帮助实现 AI 的普及。
从技术上讲,Nemotron 70B 拥有变革性的 700 亿参数结构,利用增强的多查询注意机制和优化的变压器设计,确保更快的计算速度而不会影响准确性。与早期模型相比,Llama 3.1 迭代具有更先进的学习机制,使 Nemotron 70B 能够以更少的资源获得更好的结果。该模型具有强大的微调功能,允许用户针对特定行业和任务进行定制,使其具有高度的通用性。通过利用 Nvidia 的专用 GPU 基础设施,Nemotron 70B 显着缩短了推理时间,从而为用户提供了更及时、更可操作的见解。其好处不仅限于速度和准确性——该模型还显著降低了能耗,促进了更可持续的 AI 生态系统。
Nvidia 的 Nemotron 70B 的重要性怎么强调都不为过,尤其是考虑到生成式 AI 的不断发展。凭借其先进的架构,Nemotron 70B 设定了新的性能基准,包括在关键的自然语言理解测试中超过 OpenAI 的 GPT-4 的准确率。根据最近在 Hugging Face 等平台上分享的评估,该模型在上下文理解和多语言能力方面表现出色,非常适合金融、医疗保健和客户服务领域的实际应用。
Nvidia 报告称,Nemotron 70B 在综合语言理解任务中的表现比之前的模型高出 15%,反映了其强大的性能和提供有意义的上下文感知响应的能力。这种性能提升使其成为企业寻求构建更智能、更直观的 AI 驱动系统的重要工具。
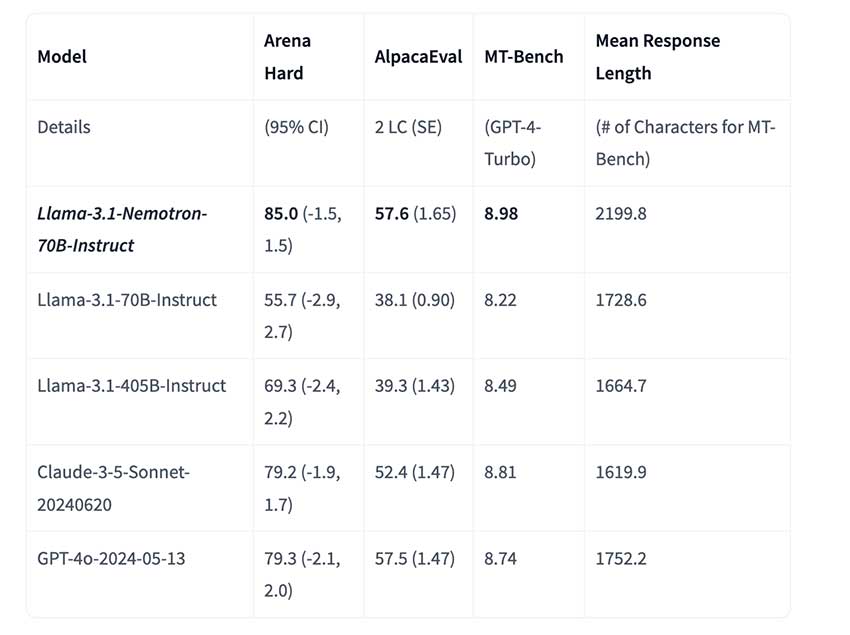

总之,Nvidia 的 Nemotron 70B 模型有望重新定义大型语言模型的格局,解决效率、准确性和能耗方面的关键差距。通过突破生成式 AI 的极限,Nvidia 打造出一款工具,它不仅可以与目前最先进的一些模型(包括 GPT-4)相媲美,而且可以超越它们。Nemotron 70B 具有低能耗、出色的性能和广泛的应用范围,为生成式模型的运行方式和为众多行业做出贡献树立了新标准。Nvidia 的方法将技术实力与实用性相结合,确保 Nemotron 70B 将成为 AI 创新和应用领域的游戏规则改变者。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/53114.html