
近期的图像和视频生成工作采用了自回归的大语言模型(LLM)架构,这种架构具有通用性,可能更容易与多模态系统集成。将语言生成中的自回归训练应用于视觉生成的关键在于离散化——也就是将图像和视频等连续数据表示为离散的tokens。常见的图像和视频离散化方法对原始像素值进行建模,这种方法过于冗长;或者使用向量量化,这需要复杂的先验训练。在本工作中,作者提出直接将图像和视频建模为计算机上使用经典编解码器(如JPEG、AVC/H.264)保存的压缩文件。作者使用Llama2-7B模型,没有进行任何视觉特定的修改,从零开始预训练了JPEG-LM用于生成图像(以及作为概念验证的AVC-LM用于生成视频),通过直接输出JPEG和AVC格式的压缩文件字节来实现生成。对图像生成的评估表明,这种简单直接的方法比基于像素的建模和复杂的向量量化基线更有效(本文提出的方法在FID指标上比基线降低了31%)。分析表明,JPEG-LM在生成长尾视觉元素方面相比向量量化模型具有特别的优势。
题目: JPEG-LM: LLMs as Image Generators with Canonical Codec Representations
作者: Xiaochuang Han, Marjan Ghazvininejad, Pang Wei Koh, Yulia Tsvetkov
文章来源: https://arxiv.org/abs/2408.08459
内容整理: 张俸玺
引言
随着大语言模型(LLMs)的发展,自然语言处理领域已转向使用单一的 LLM 进行多任务处理(如机器翻译、代码生成、行动规划),并且只需少量数据进行适配。未来的研究将继续向多模态、多任务处理方向发展,其中文本和视觉数据将混合使用。然而,当前图像和视频生成的范式与文本生成有显著差异,通常需要专门且复杂的训练和表示方法。在本研究中,我们通过使用与主流 LLM 完全相同的自回归 transformer 架构来简化图像和视频生成任务,基于经典和通用的编解码器:用于图像的 JPEG和用于视频的 AVC/H.264。
训练用于图像和视频生成的自回归模型的关键障碍是离散化,因为像图像和视频这样的连续数据需要表示为离散 token。目前,遵循自回归语言建模目标的生成视觉模型通常采用矢量量化(VQ)来将图像或视频编码为某种学习的潜码,然后应用语言模型。然而,VQ 方法通常要求复杂的 tokenizer 训练,需要对视觉特定模块(如卷积中的下采样因子)进行仔细的超参数选择,并在多个损失之间进行平衡。此外,VQ 涉及一个非端到端的两阶段学习过程(首先是神经 tokenizer,然后是潜码语言模型)。这使得模型的下游适配变得不够灵活(例如,微调 VQ tokenizer 会干扰已学习的潜码语言模型)。总体而言,将常规的 LLM 架构(端到端自回归序列建模)作为生成视觉模型的应用尚未成为主流。ImageGPT 的开创性工作试图通过使用常规 GPT 架构按顺序建模像素来弥合这一差距。他们在 32×32 像素的低分辨率上展示了小规模的成功。对于更现实的 256×256 尺寸的图像,建模每个序列中庞大的 token 数量(65K 或 196K 个 token,取决于颜色模式)是非常困难的,更不用说视频了。这一问题阻碍了该方法在更广泛领域的应用。
在本研究中,作者致力于解决 LLM 架构在图像和视频生成中的训练问题,这种方法既不会像 VQ 方法那样为流程增加显著复杂性,也不会像 ImageGPT 那样在计算上过于昂贵。具体来说,作者使用经典文件编码/编解码器——JPEG 用于图像,AVC/H.264 用于视频——作为非神经的预处理器来离散化数据。实验表明,基于编解码器的表示方式大大缓解了序列长度的限制,同时保持了简单且有效的特点。该设计能够在现实环境中使用常规的语言建模目标训练一个普通的 transformer 来进行图像和视频生成。作者预训练了两个 7B 模型,采用 Llama-2 架构,分别命名为 JPEG-LM 和 AVC-LM,能够生成 256×256 的图像和 15 帧的 256×144 视频,平均上下文长度分别为 5K 和 15K。在主要图像建模/生成评估中,JPEG-LM 在生成质量上超过了强大的 VQ 模型(平均 FID 减少 31%),并产生了令人惊讶的逼真定性示例。实验结果还表明,AVC-LM 能够生成具有逼真运动的视频。此外,本文分析了 JPEG-LM 在某些方面比 VQ 模型更强,发现本文提出的非神经、免训练的编解码器表示在捕捉图像中的长尾元素(例如小尺寸的人脸/眼睛和文本字符)方面更有优势。
总的来说,这项工作展示了如何将常规 LLM 架构用作生成视觉内容的通用模型。使用经典编解码器的方法既没有在流程中引入视觉特定的复杂性,也没有遇到之前工作中序列长度不可行的问题。与基线相比,这种模型训练更简单且更有效。
JPEG-LM与AVC-LM
尽管图像和视频是连续数据,且自然具有二维或三维数据结构,但它们通过压缩/编解码器被高效地存储为计算机中的文件,从而形成离散的 1D 表示。本文旨在探索标准的 LLM 架构是否可以直接学习建模和生成经典的视觉文件编码,这些编码随后可以被读取或打开为生成的图像或视频。在这种范式下进行生成将大大缓解 ImageGPT 中序列长度的不可行性,同时与 VQ 方法相比,具有简单且可端到端训练的优点。此外,经典文件编码/编解码器通常是非神经网络的且无需训练,并且对分布变化具有鲁棒性。本文分别选择了图像和视频领域最受欢迎和成熟的文件编码/编解码器,即 JPEG(Wallace, 1991)和 AVC/H.264(Wiegand 等人,2003)。
Canonical Codecs
像 JPEG 和 AVC 这样的经典非神经网络编解码器具有一个高层次的直觉,即对人眼不太容易察觉的信号进行更为激进的压缩。JPEG 对每张图像的编码主要分为三个步骤:离散余弦变换(DCT)、量化和熵编码。DCT 将每个图像块转换为一组包含低频和高频模式的预设块的加权组合。量化则将加权组合中的一些高频模式置零,因为人眼不容易感知这些模式。然后,使用诸如霍夫曼编码之类的熵编码来减少表示这些图像块所需的总数/比特数。
AVC(H.264)对视频帧的块(宏块)进行操作。每个块可以使用当前帧中已编码的像素块进行编码(帧内预测),或者使用其他帧中已编码的像素块进行编码(带有运动估计的帧间预测)。预测结果从当前块中减去,形成残差。然后,残差经过类似于 JPEG 的处理过程,包括 DCT、量化和比特流编码。编码后的内容是后续容器文件(如 MP4)的关键部分。几十年来,这两种编解码器已被广泛使用,与基于原始像素的建模相比,它们大幅压缩了数据量(在我们的设置中,JPEG 压缩比约为 40 倍,AVC 压缩比约为 110 倍)。本文的重点是将这些经典编解码器作为现成工具,来高效地将图像和视频转换为离散字节序列。基于此希望让一个 LLM 隐式学习这些经典编解码器的语法和语义。
JPEG-LM and AVC-LM

JPEG 和 AVC 将图像和视频转换为字节。这些字节大多数是在熵编码后表示图像和视频内容的字节。然而,也存在一些元数据和特殊的块/宏块分隔符,它们在图像或视频中是恒定的,并占用了多个字节(如图 1:JPEG-LM 和 AVC-LM 是直接建模和生成经典文件编码的简单自回归 transformers)。为了处理这些字节以及其他通过熵编码压缩不佳的未知常见字节组合(例如,JPEG 的标准固定霍夫曼表),作者进一步通过字节对编码(BPE)略微扩展了默认的字节词汇表(256 个离散值)。BPE 是 LLMs 中的标准预处理方案,它将频繁一起出现的字节合并为一个新的单一 token。由于 JPEG 和 AVC 根据图像和视频的内容生成长度可变的序列,作者还在词汇表中添加了序列开始和结束的特殊 token。词汇表中的条目被视为模型的 JPEG/AVC tokens。
给定图像 x,我们提出了 JPEG-LM 来建模 p(JPEG-token(x)i| JPEG-token(x)1:i-1 )。给定视频 x,我们提出了 AVC-LM 来建模 p(AVC-token(x)i| AVC-token(x)1:i-1)。我们使用传统的 LLM 架构(自回归 transformers),不进行任何特定于视觉的修改(无卷积,无二维位置嵌入),以最大化模型的通用性。
实验
JPEG-LM
作者从头开始预训练了一个 Llama-2 (7B)模型,使用了 2300 万张 256×256 的图像。每张图像通过 JPEG 编码,质量因子为 25。首先使用 1 万张图像提取了 320 个 BPE tokens 作为词汇表条目。训练数据中的平均每张图像会生成 5K 个 tokens。为了提高批处理效率,将数据集中所有序列拼接,并以 12K 的序列长度进行分块。总共有 950 万个序列,因此每个 epoch 包含 1140 亿个 JPEG tokens。模型大约训练了两个 epoch,最大学习率为 3e-4。
AVC-LM
作为经典视频编解码器用于视频生成的概念验证,类似于 JPEG-LM,作者从头开始预训练了一个 Llama-2 (7B) 模型作为 AVC-LM,使用了 200 万个 256×144 视频。由于实验规模限制,作者只保留了每个视频的前 5 秒,以 3 帧每秒的速率采样(因此每个视频共 15 帧)。然后使用 AVC/H.264 编解码器对视频进行处理,量化参数设为常数 37.8。作者使用 1 万个视频提取了 1024 个 BPE tokens 作为词汇表条目。训练数据中的每个视频平均包含 15K 个 tokens。作者进行数据拼接,并以 32K 的上下文长度进行分块以实现高效批处理。总共有 130 万个序列,因此共有 420 亿个 AVC tokens。
Baseline
VQ transformer: 使用了预训练的 VQ tokenizer,该模型使用了 2 亿张图像(ITHQ-200M,闭源数据集)训练了一个 VQ-VAE 模型。这个 VQ tokenizer 对 JPEG-LM 训练集中的 2300 万张图像进行处理(词汇表大小为 4096,序列长度为 1024)。随后,使用与 JPEG-LM 相同配置的 Llama-2 (7B) 进行训练。在本研究中,将此 VQ 模型作为与 JPEG-LM 进行主要比较的基准。
ImageGPT+Super-resolution: ImageGPT 使用 GPT-2 XL 作为其底层架构。预训练模型在 1400 万张来自 ImageNet 的 32×32 图像上进行了训练。为了进行可比评估,在 ImageGPT 的输出上使用了一个超分辨率模型。
结果

质量分析

图2和图3展示了来自JPEG-LM和基线模型的生成样本,这些样本来自现有训练集之外的独立数据。可以观察到JPEG-LM 通过直接输出JPEG文件字节,能够生成出令人惊讶的逼真面部表情(尤其是在眼睛方面,相较于强大的VQ transformer),以及风景、常见物体、图像形式的文本等。

定量分析
表1展示了在 ImageNet-1K 上对 JPEG-LM、VQ transformer 和其他基线模型进行不同级别的部分图像提示。FID 评估包含从 ImageNet-1K 验证集中随机抽取的 5000 张图像。这是零样本生成(相对于模型的训练集)且不进行类别条件化。实验使用不同的种子进行了三次。JPEG-LM 在所有提示比例下始终优于 VQ transformer,且大多超过了具备图像修复能力的扩散模型基线。
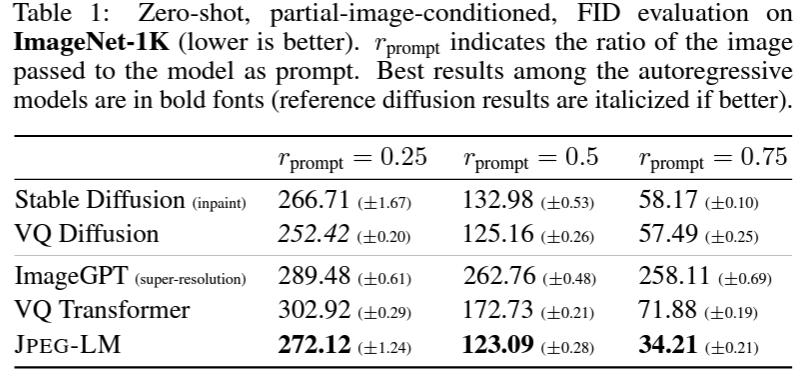
表2展示了对 FFHQ 数据集中部分图像提示的模型评估。同样是零样本设置且不进行 FFHQ 分布的训练,评估了随机抽取的 1000 张 FFHQ 图像。JPEG-LM 始终优于 VQ transformer 和其他基线。
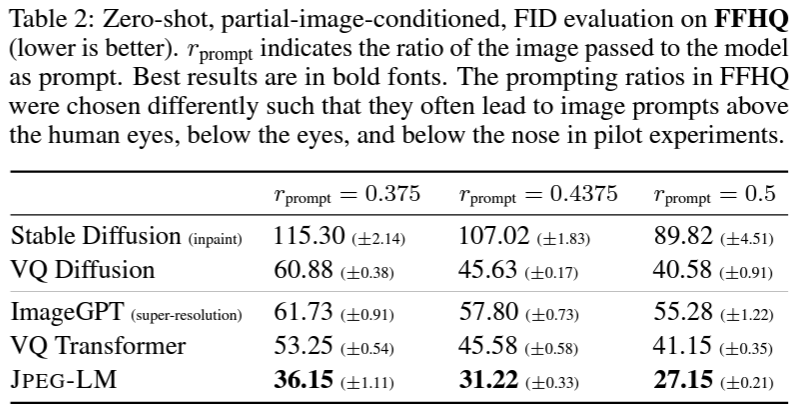
表3进一步验证了 JPEG-LM 和 VQ transformer 在完全无条件生成任务上的表现。由于它们在相同的训练数据上进行训练,因此可以比较它们在保留的独立同分布评估集上的无条件生成 FID。再次观察到 JPEG-LM 获得了更好的 FID。这些结果表明,JPEG-LM 作为一个纯 LLM 架构的图像生成模型,在建模经典文件编码方面表现出了全面的能力。

长尾元素
为了进一步探讨 JPEG-LM 相较于基线模型(尤其是 VQ transformer)的优势所在,首先比较了在 JPEG-LM 和 VQ 模型中数据在进入 transformer 进行训练之前的处理和压缩方式。
JPEG-LM 和 VQ transformers 都可以被理解为首先执行压缩,然后进行自回归建模。与非神经网络的 JPEG 压缩不同,VQ 模型的 VQ-VAE 量化器通过大量数据进行了训练。图 3 中可以观察到两种压缩方法在压缩和解压缩一般场景(如自然/风景背景)方面都相对成功。然而,可以看到 VQ 在处理图像中一些小但高度可感知的元素(如人脸或眼睛)时表现不佳。对于包含小字符文本的图像,观察到 VQ 的图像退化以一种不可预测的方式发生,生成的字符看似清晰但无法辨识。相比之下,由于非神经网络且无需训练的 JPEG 压缩导致的图像退化是可预测的,因而在一定程度上更可取,特别是在图像中包含具有重要意义的长尾元素时。
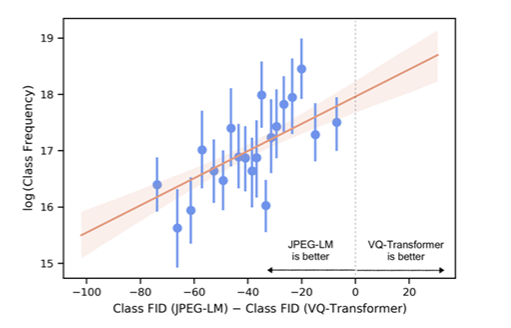
图 4 展示了在 ImageNet-1K 生成实验中的每个类别的 FID。对于每个类别的图像,计算它们与 JPEG-LM 生成结果的 FID 与 VQ transformer 生成结果的 FID 之间的差异。通过查询 Google 图片搜索并记录返回结果的总数,估算每个类别图像在互联网上的频率/覆盖度。可以观察到每个类别的 FID 差异与类别频率之间存在统计显著的相关性。JPEG-LM 相较于 VQ 模型的优势越大,所对应的类别在互联网上的频率越低。换句话说,JPEG-LM 在长尾子分布中表现得更加突出。
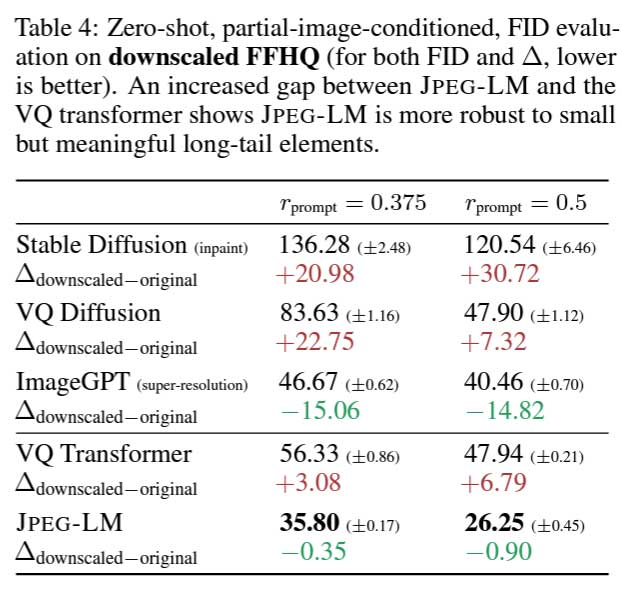
表 4 进一步对 FFHQ 图像进行干预,将其缩小到原尺寸的 0.5 倍,同时用黑色背景填充图像以保持整体尺寸不变,旨在测试不同模型在较小视觉概念(如人脸)上的表现。这些概念虽然尺寸较小,但对人类仍然高度可感知,并且具有重要意义。因此,希望模型在这些概念上表现出鲁棒性。对 JPEG-LM、VQ transformer 和其他基线模型进行了类似的提示图像生成实验。可以发现,JPEG-LM 依然始终优于 VQ transformer(以及其他基线模型)。特别是,JPEG-LM 在图像缩小的实验中表现出略好的性能,而 VQ transformer 相较于原始图像尺寸的实验则表现得更差。这种性能变化方向上的差异进一步凸显了 JPEG-LM 的鲁棒性。
视频生成的概念验证
在 LLM 范式下使用经典文件编码进行视觉生成的一个优势是简洁性。从生成图像的 JPEG-LM 出发,作者自然而然地进一步训练了视频生成模型 AVC-LM,它使用自回归 transformers 来建模经典视频编解码器(AVC/H.264)。作为概念验证,作者用训练数据集中保留的一部分视频(即帧)来提示 AVC-LM,并研究模型对这些视频的补全能力。图 5 展示了 AVC-LM 生成的定性示例。我们观察到,AVC-LM 能够合理地捕捉到运动物体的动态。

结论
本文提出了 JPEG-LM 和 AVC-LM,这两种方法利用主流的 LLM 架构(自回归 transformers)结合经典的编解码表示(图像使用 JPEG,视频使用 AVC/H.264)生成图像和视频。该方法在很大程度上缓解了基于像素的序列建模中存在的长度不可行性问题,同时与复杂的矢量量化方法相比,能够实现更简单、灵活且端到端的训练。图像生成评估显示,JPEG-LM 相较于基线模型取得了更好的结果,尤其在生成长尾视觉元素方面具有明显优势。
本研究的一大意义在于展示了使用经典编解码器进行视觉生成的普通自回归建模确实是可行的。这种方法几乎没有相关的先前工作,可能是因为人们认为该方法存在许多潜在的、假设的挑战。例如,由于熵编码的存在,JPEG 和 AVC 都是在比特层面上操作的。文件中的字节并不具有一致的意义,它们依赖于上下文以及隐含的霍夫曼表。为了保持通用性,本文的模型也没有使用任何特定于视觉的模块,如卷积或二维位置嵌入,这可能使任务变得更具挑战性。然而,作者发现,传统的普通语言建模在训练过程中意外地克服了这些挑战,而不需要特别的设计(例如,JPEG-LM 几乎没有产生任何损坏的 JPEG 图块,便能生成逼真的图像)。基于本研究的发现,未来的工作可以继续探讨这一类模型的扩展性,或设计更适合经典编解码器的架构,同时保持对其他模态的通用性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
