
视觉语言模型 (VLM) 评估面临的一个主要挑战是了解它们在各种实际任务中的各种能力。现有的基准测试往往存在不足,侧重于狭窄的任务集或有限的输出格式,导致无法充分评估模型的全部潜力。在评估需要在众多应用领域进行全面测试的较新的多模式基础模型时,这个问题变得更加明显。这些模型需要一个基准测试套件,能够在各种输入和输出场景中评估它们的能力,同时最大限度地降低推理成本。
MEGA-Bench 团队的研究人员推出了 MEGA-Bench,这是一种创新而全面的基准测试,可将多模态评估扩展到涵盖 500 多个实际任务。MEGA-Bench 旨在针对各种输入、输出和技能要求对多模态模型进行高质量、系统的评估,涵盖比以前的基准测试更广泛的用例。与早期专注于多项选择题等标准化输出的基准测试不同,MEGA-Bench 涵盖了各种各样的输出,例如数字、短语、代码、LaTeX 和 JSON。这可以准确评估生成和预测能力,从而揭示模型性能的更精细细节。
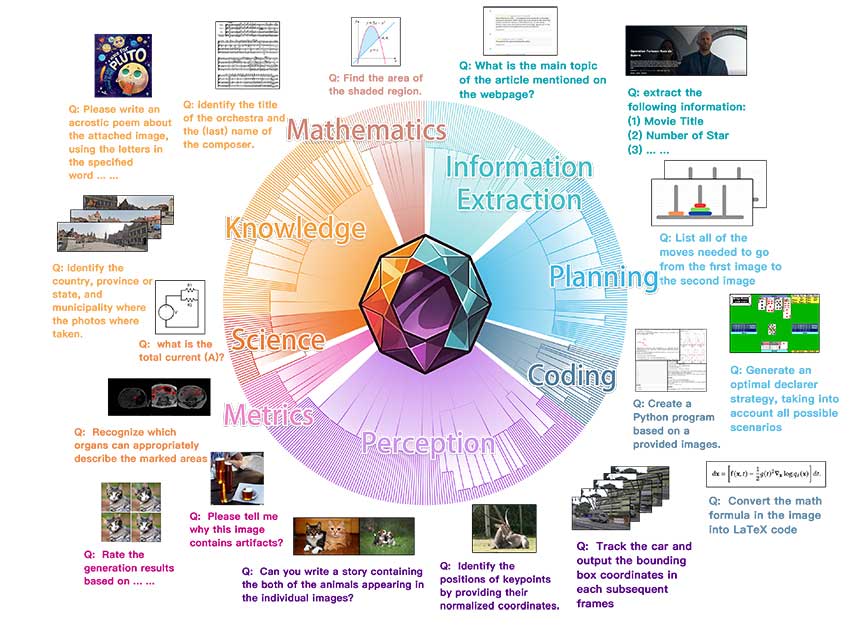
MEGA-Bench 的结构经过精心设计,可确保全面覆盖。它包含 505 个多模态任务,由 16 位专家撰稿人和注释。基准分类法包括应用程序类型、输入类型、输出格式和技能要求等类别,确保任务覆盖范围多样而全面。为了适应各种输出,开发了 40 多个指标,提供对模型功能的细粒度和多维分析。该基准还为用户引入了一个交互式可视化工具,使他们能够探索不同维度的模型优势和劣势,使 MEGA-Bench 成为比传统基准更实用的评估工具。
将 MEGA-Bench 应用于各种最先进的 VLM 的结果突出了一些关键发现。在旗舰模型中,GPT-4o 的表现优于其他模型,包括 Claude 3.5,得分高出 3.5%。在开源模型中,Qwen2-VL 实现了顶级性能,几乎与专有模型相匹配,并且比排名第二的开源模型高出约 10%。对于效率模型,Gemini 1.5 Flash 被发现是总体上最有效的,在与用户界面和文档相关的任务中具有特定的优势。另一个见解是,专有模型受益于思想链提示,而开源模型则难以有效地利用它。
总之,MEGA-Bench 代表了多模态基准测试的重大进步,为视觉语言模型的功能提供了全面而细致的评估。通过支持多样化的输入和输出以及详细的性能指标,它可以更真实地评估这些模型在实际任务中的表现。该基准测试使开发人员和研究人员能够更好地理解和优化 VLM 以用于实际应用,为多模态模型评估树立了新标准。
论文地址:https://tiger-ai-lab.github.io/MEGA-Bench/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
