
多模态属性图 (MMAG) 尽管在图像生成方面用途广泛,但并未受到太多关注。MMAG 以图形结构的方式表示具有组合复杂性的实体之间的关系。图中的节点包含图像和文本信息。与文本或图像调节模型相比,图形可以转换成更好、更具信息量的图像。Graph2Image 是该领域的一项有趣挑战,它需要生成模型来综合文本描述和图形连接的图像调节。虽然 MMAG 很有用,但它们不能直接合并到图像和文本调节中。
以下是使用 MMAG 进行图像合成时最相关的挑战:
- 图形尺寸爆炸式增长:这种现象是由于图形的组合复杂性而发生的,当我们在模型中引入包含图像和文本的局部子图时,图形尺寸会呈指数增长。
- 图形实体依赖关系 :节点特征相互依赖,因此,它们的接近度反映了文本和图像中实体之间的关系以及它们在图像生成中的偏好。为了举例说明,生成浅色衬衫应该偏好浅色调,例如粉彩色。
- 图形条件可控性需求:必须控制生成图像的可解释性以遵循图形中实体之间的连接定义的所需模式或特征。
伊利诺伊大学的一组研究人员开发了 InstructG2I 来解决此问题。这是一个利用多模态图信息的图上下文感知扩散模型。此方法通过将图中的上下文压缩为固定容量的图条件标记来解决图空间复杂性问题,并通过基于语义个性化 PageRank 的图采样进行增强。Graph-QFormer 架构通过解决图实体依赖性问题进一步改进了这些图标记。最后但并非最不重要的是,InstructG2I 以可调边长引导图像生成。
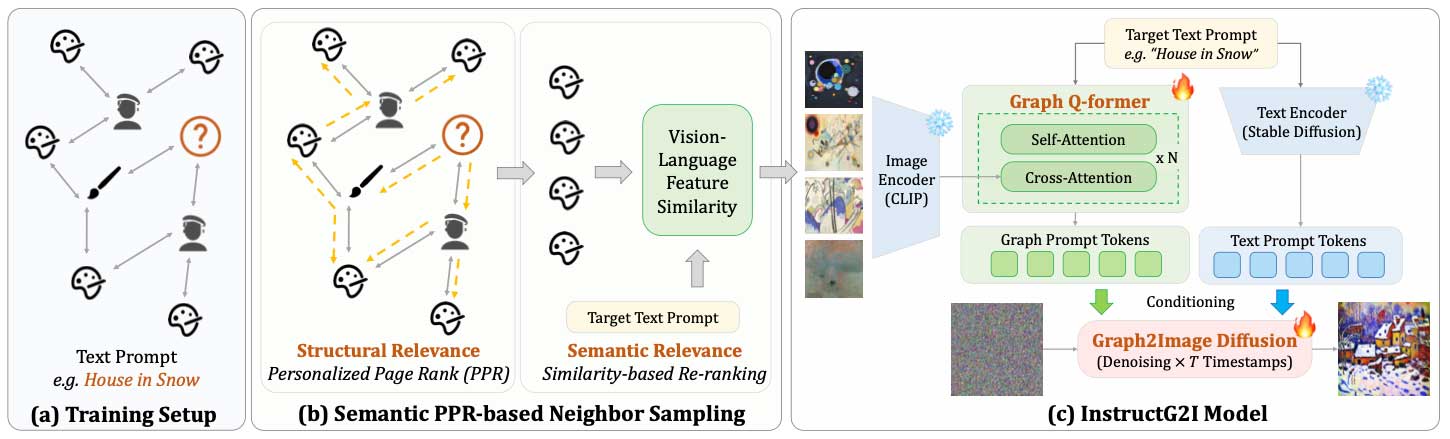
InstructG2I 将图形条件引入稳定扩散,并采用基于 PPR 的邻居采样。PPR 或个性化 PageRank 从图形结构中识别相关节点。为了确保生成的图像在语义上与目标节点相关,使用基于语义的相似度计算函数进行重新排序。本研究还提出了 Graph-QFormer,这是一个双转换器模块,用于捕获基于文本和基于图像的依赖关系。Graph-QFormer 对图像-图像依赖关系采用多头自注意力,对文本-图像依赖关系采用多头交叉注意力。交叉注意力层将图像特征与文本提示对齐。它使用来自自注意力层的隐藏状态作为输入,并使用文本嵌入作为查询来生成相关图像。Graph-QFormer 的两个转换器的最终输出是图形条件提示标记,它们指导扩散模型中的图像生成过程。最后,为了控制生成过程,使用无分类器指导,这基本上是一种调整图强度的技术
InstructG2I 在三个来自不同领域的数据集上进行了测试——ART500K、Amazon 和 Goodreads。对于文本到图像的方法,Stable Diffusion 1.5 被确定为基线模型,对于图像到图像的方法,选择了 InstructPix2Pix 和 ControlNet 进行比较;两者都使用 SD 1.5 初始化,并在选定的数据集上进行微调。研究结果显示,在两个任务中,与基线模型相比,InstructG2I 的表现都有显著改善。InstructG2I 在 CLIP 和 DINOv2 得分方面优于所有基线模型。对于定性评估,InstructG2I 从图中生成了最符合文本提示和上下文语义的图像,确保在从图上的邻居那里学习并准确传达信息时生成内容和上下文。
InstructG2I 有效地解决了多模态属性图中的爆炸式增长、实体间依赖性和可控性等重大挑战,并取代了图像生成中的基线。在未来几年中,将有很多机会使用和将图形纳入图像生成,其中很大一部分包括处理 MMAG 上图像和文本之间复杂的异构关系。
论文地址:https://arxiv.org/abs/2410.07157
代码地址:https://github.com/PeterGriffinJin/InstructG2I
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/52974.html
