
近日, LiveKit 与 OpenAI 建立合作伙伴关系,提供可以使用与 ChatGPT 的新高级语音(Advanced Voice)功能相同的端到端技术来构建自己的应用程序。
LiveKit 将发布新的多模态代理 API,它内置了对 OpenAI 全新实时 API 的支持。现在,您可以使用 GPT-4o 构建应用程序,像 ChatGPT 一样实时聆听并与用户对话。本文分享如何设计并与 OpenAI 一起构建这一新 API 。
高级语音的工作原理
当您使用高级语音时,ChatGPT 不仅能理解您说什么,还能理解您说话的方式,并且可以在约 300 毫秒内(人类语音的延迟阈值)做出反应,表达一系列人类情感。该功能的工作原理如下:
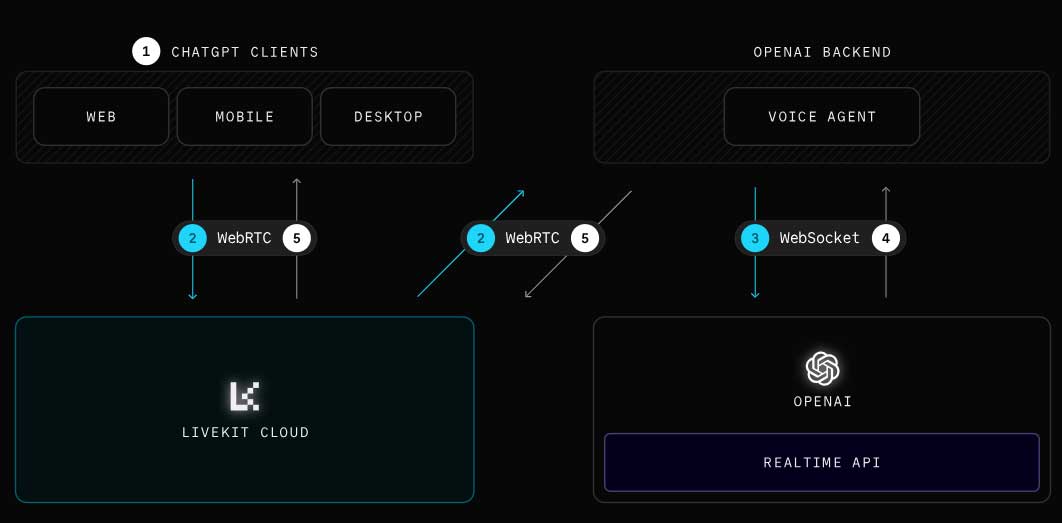
- 用户的语音由 ChatGPT 应用程序中的 LiveKit 客户端 SDK 捕捉。
- 用户的语音通过 LiveKit Cloud传输到 OpenAI 的语音代理。
- 代理将语音提示转发给 GPT-4o。
- GPT-4o 运行推理并将语音包流回代理。
- 代理通过 LiveKit 云将生成的语音转发回用户的设备。
促进上述工作流程需要一种与使用 ChatGPT 发送文本时使用的传统 HTTP 请求-响应模型不同的架构。
OpenAI 使用 WebSocket 来实现语音代理与 GPT-4o 之间的通信,他们现在在 Realtime API 中向开发人员公开了该接口。语音代理不断将音频输入流式传输到 GPT-4o,同时接收来自模型的音频输出。
对于几乎没有数据包丢失的服务器到服务器应用程序,WebSocket 就足够了。但是,对于像 Advanced Voice 这样的最终用户应用程序,我们需要从客户端设备获取音频输入并将音频输出流式传输到客户端设备。WebSocket 并不是最好的选择,因为它处理数据包丢失的方式。绝大多数数据包丢失发生在服务器和客户端设备之间,WebSocket 无法在 WiFi 或蜂窝等有损网络环境中提供编程控制或干预。数据包丢失会导致更高的延迟和断断续续或混乱的音频。
为了克服这一限制,OpenAI 使用了另一种名为 WebRTC 的协议。WebRTC 专为在服务器和客户端之间传输超低延迟音频而设计。协议实现具有内置编解码器支持,可根据网络条件调整比特率,并且可在大多数平台上使用。但是,直接使用它会带来很多复杂性和扩展挑战。
LiveKit 是简化 WebRTC的开源基础设施,而LiveKit Cloud是一个全球服务器网络,经过优化,可以大规模、可靠地传输音频并实现尽可能低的延迟。
为了从最终用户的设备发送和接收音频,OpenAI 将 LiveKit 客户端 SDK 集成到 ChatGPT 应用中。在后端,另一个专为在服务器环境中使用 WebRTC 而设计的 LiveKit SDK 接收来自用户的流式音频并将音频流式传输回用户。用户和代理都使用 LiveKit Cloud 上的 WebRTC 相互连接。
将 LiveKit 与 OpenAI 的实时 API 结合使用
LiveKit 在 Agents 框架中推出了一个新的 API 以及新的前端挂钩和组件,这使得任何人都可以轻松构建像 Advanced Voice 这样的产品。
后端
Python 和 Node 中提供的新型多模式代理 API 旨在完全包装 OpenAI 的实时 API,抽象出原始线路协议,并为 GPT-4o 提供干净的“直通”接口。
MultimodalAgent类动态处理流式文本和音频模式。您可以将任一模式作为输入发送,并以任一模式接收输出。使用语音时,API 会自动将文本转录与音频在用户设备上播放时进行时间对齐。这对于隐藏式字幕等功能非常有用。如果您的用户在播放过程中通过说话打断了 GPT-4o,API 将检测到它并与 GPT-4o 同步状态,以确保其上下文窗口回滚到中断点。
所有实时 API 参数(如语音选择、温度和转换预测配置)均得到透明支持。关于转换预测,我们很快将提供与 OpenAI 具有相同默认值的代理端转换预测,并公开更多设置。
MultimodalAgent还与 Agents 框架的现有功能集成:
- 缓冲播放。GPT -4o 生成音频的速度比播放速度快。我们的 SDK 会自动缓冲、流式传输、处理用户中断并以正确的时间播放音频。
- 函数调用。您可以使用自然语言指定的调用触发器来定义参数化函数。Agents 框架会将 GPT-4o 工具调用映射到您的函数,并使用适当的参数来调用它。
- 负载平衡。部署代理时,它们会向 LiveKit 服务器注册。一旦用户连接,LiveKit 服务器就会调度附近的代理,监控其运行状况,并处理故障转移和重新连接。
- 集成电话。LiveKit具有与 Agents 框架集成的电话堆栈。一旦你向 Twilio 或 Telynx 等提供商提供并配置电话号码,你的用户就可以通过电话与 GPT-4o 通话。
这是一个MultimodalAgent在 Python 中使用 的简单示例:
from livekit.agents import MultimodalAgent, AutoSubscribe, JobContext, WorkerOptions, WorkerType, cli
from livekit.plugins.openai.realtime import RealtimeModel
async def entrypoint(ctx: JobContext):
await ctx.connect(auto_subscribe=AutoSubscribe.AUDIO_ONLY)
agent = MultimodalAgent(
model=RealtimeModel(
instructions="...",
voice="alloy",
temparature=0.8,
modalities=["text", "audio"],
)
)
agent.start(ctx.room)
if __name__ == "__main__":
cli.run_app(WorkerOptions(
entrypoint_fnc=entrypoint,
worker_type=WorkerType.ROOM
))负载平衡直接内置于 LiveKit 的媒体服务器中,因此您可以在本地主机、自托管部署或 LiveKit Cloud 上以完全相同的方式运行此代理。
前端
在前端,LiveKit 有新的钩子、移动组件和可视化工具,可简化将客户端应用程序连接到代理的过程。以下是 NextJS 中的一个示例:
import { LiveKitRoom, RoomAudioRenderer, BarVisualizer, useVoiceAssistant } from '@livekit/components-react'
function MultimodalAgent() {
const { audioTrack, state } = useVoiceAssistant()
return (
<div>
<BarVisualizer trackRef={audioTrack} state={state} />
</div>
)
}
export default function IndexPage({ token }) {
return (
<LiveKitRoom serverUrl={process.env.NEXT_PUBLIC_LIVEKIT_URL} connect={true} audio={true} token={token}>
<MultimodalAgent />
<RoomAudioRenderer />
</LiveKitRoom>
)
}有关在生产中运行的类似上述代码的示例,请查看 LiveKit 的主页或开源 Realtime API playground. 。
使用案例
随着高级语音的功能现已以 API 的形式提供,我们将看到开发人员构建出令人难以置信的 AI 原生应用程序。GPT-4o 跨多种模式的联合训练显著减少了推理延迟,并赋予了它跨语言理解和表达人类情感的能力。我认为我们将在以下几个领域看到这项新技术立即得到应用:
- 客户支持和远程医疗。语音(通过电话)是这些行业的默认方式,拥有灵活、更具同理心的自动化服务提供商将对现有电话树和 IVR 系统的 UX 进行重大升级。
- 语言学习。学习一门新语言最快的方法就是沉浸在其中——世界各地的语言在结构和使用方式上都各不相同。在此之前,人工智能无法模仿母语人士。
- 视频游戏 NPC。想象一下整个游戏世界中丰富、动态的故事情节,通过您实时遇到并与之交谈的类人角色栩栩如生地呈现。
- 治疗和冥想。我们的内心想法是人类体验中最典型的方面之一。能够与人工智能互动,无需担心受到评判,从而锻炼心理健康,将对社会产生广泛的积极影响。
原文:https://blog.livekit.io/openai-livekit-partnership-advanced-voice-realtime-api/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/52882.html
