
利用自回归大语言模型(LLM) 生成视频是一个新兴领域,发展前景广阔。虽然 LLM 在自然语言处理中生成连贯且冗长的标记序列方面表现出色,但它们在视频生成中的应用仅限于几秒钟的短视频。为了解决这个问题,研究人员推出了 Loong,这是一种基于自回归 LLM 的视频生成器,能够生成长达数分钟的视频。
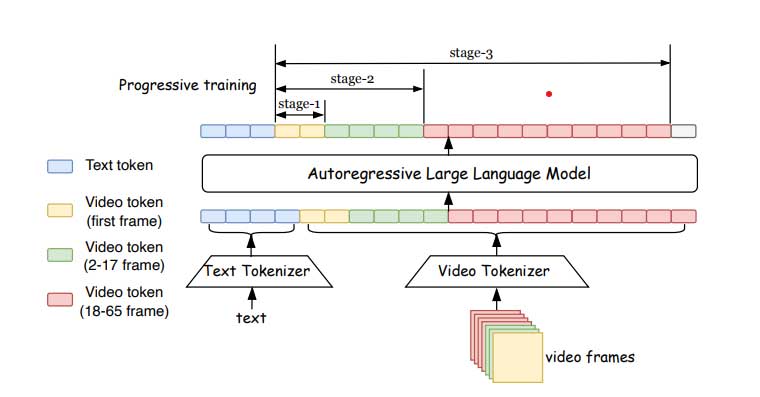
训练像 Loong 这样的视频生成模型涉及一个独特的过程。该模型从头开始训练,将文本标记和视频标记视为统一序列。研究人员提出了一种渐进式的短到长训练方法和损失重新加权方案,以缓解长视频训练的损失不平衡问题。这使得 Loong 可以在 10 秒的视频上进行训练,然后扩展为以文本提示为条件生成分钟级的长视频。
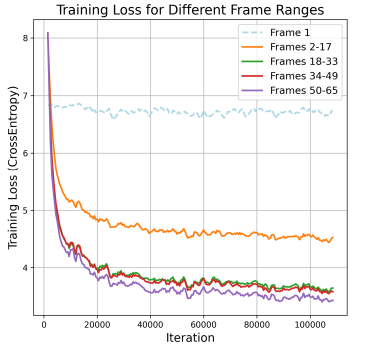
然而,大视频的生成相当棘手,未来还有许多挑战。首先,训练过程中存在损失不平衡的问题。当以下一个 token 预测为目标进行训练时,从文本提示预测早期帧的 token 比根据前几帧预测晚期帧的 token 更难,导致训练期间损失不均衡。随着视频长度的增加,来自简单 token 的累积损失掩盖了来自困难 token 的损失,主导了梯度方向。其次,该模型根据真实 token 预测下一个 token,但在推理过程中依赖于自己的预测。这种差异会造成误差累积,尤其是由于强帧间依赖性和许多视频 token,导致长视频推理中的视觉质量下降。
为了缓解视频 token 难度不平衡的挑战,研究人员提出了一种渐进式短到长训练策略,并重新调整损失,如下所示:
循序渐进的短期至长期训练
训练分为三个阶段,这增加了训练长度:
第一阶段:在大型静态图像数据集上使用文本到图像生成对模型进行预训练,帮助模型为建模每帧外观奠定坚实的基础
第二阶段:模型在图像和短视频片段上进行训练,学习捕捉短期时间依赖性
第三阶段:增加视频帧数,继续进行联合训练
Loong 采用双组件系统设计,一个将视频压缩为标记的视频标记器、一个解码器和一个根据文本标记预测下一个视频标记的转换器。
Loong 使用 3D CNN 架构作为tokenizer,灵感来自 MAGViT2。该模型适用于低分辨率视频,并将超分辨率留给后期处理。Tokenizer 可以将 10 秒的视频(65 帧,128*128 分辨率)压缩为 17*16*16 个离散 token 序列。基于自回归 LLM 的视频生成将视频帧转换为离散 token,使文本和视频 token 形成统一的序列。文本到视频的生成被建模为基于文本 token 的自回归预测视频 token,使用仅解码器的 Transformers。
大型语言模型可以推广到较长的视频,但超出训练时长可能会导致错误积累和质量下降。有很多方法可以纠正它:
- 视频令牌重新编码
- 采样策略
- 超分辨率和细化
该模型采用 LLaMA 架构,参数大小从 700M 到 7B 不等。模型从头开始训练,没有文本预训练权重。词汇表包含 32,000 个文本标记、8,192 个视频标记和 10 个特殊标记(共 40,202 个)。视频标记器复制了 MAGViT2,对第一个视频帧使用因果 3D CNN 结构。空间维度压缩了 8 倍,时间维度压缩了 4 倍。量化使用聚类矢量量化 (CVQ),与标准 VQ 相比,提高了码本的使用率。视频标记器有 246M 个参数。

Loong 模型可以生成外观一致、运动动态大、场景过渡自然的长视频。Loong 采用统一顺序的文本标记和视频标记进行建模,并通过渐进式短到长训练方案和损失重加权克服了长视频训练的挑战。该模型可用于协助视觉艺术家、电影制片人和娱乐目的。但与此同时,它可能被错误地用于创建虚假内容和传递误导性信息。
论文地址:https://arxiv.org/abs/2410.02757
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/52825.html
