
人工智能 (AI) 正在迅速变革,尤其是在多模态学习方面。多模态模型旨在结合视觉和文本信息,使机器能够理解和生成需要来自两个来源的输入的内容。此功能对于图像字幕、视觉问答和内容创建等任务至关重要,因为这些任务需要多种数据模式。虽然已经开发了许多模型来应对这些挑战,但只有一些模型有效地协调了视觉和文本数据的不同表示,导致实际应用中效率低下和性能不佳。
多模态学习面临的一个重大挑战在于文本和图像数据的编码和表示方式。文本数据通常使用从查找表派生的嵌入来定义,以确保格式结构化且一致。相比之下,视觉数据使用视觉转换器进行编码,从而产生非结构化的连续嵌入。这种表示上的差异使现有的多模态模型更容易无缝融合视觉和文本数据。因此,模型很难解释复杂的视觉-文本关系,从而限制了它们在需要跨多种数据模态进行一致理解的高级 AI 应用中的能力。
传统上,研究人员尝试通过使用连接器(例如多层感知器 (MLP))将视觉嵌入投射到可以与文本嵌入对齐的空间中来缓解此问题。虽然这种架构在标准多模态任务中很有效,但它必须解决视觉和文本嵌入之间的根本错位。LLaVA 和 Mini-Gemini 等领先模型采用了交叉注意机制和双视觉编码器等先进方法来提高性能。然而,由于标记化和嵌入策略的固有差异,它们仍然面临限制,这凸显了需要一种在结构层面解决这些问题的新方法。
阿里巴巴集团和南京大学的研究团队推出了新版本的Ovis:Ovis 1.6 是一种新的多模态大型语言模型 (MLLM),它在结构上将视觉和文本嵌入对齐以应对这一挑战。Ovis 采用独特的视觉嵌入查找表,类似于用于文本嵌入的查找表,以创建结构化的视觉表示。该表使视觉编码器能够生成与文本嵌入兼容的嵌入,从而实现更有效的视觉和文本信息集成。该模型还利用多次映射到视觉嵌入表中的视觉块的概率标记。这种方法反映了文本数据中使用的结构化表示,促进了视觉和文本输入的连贯组合。
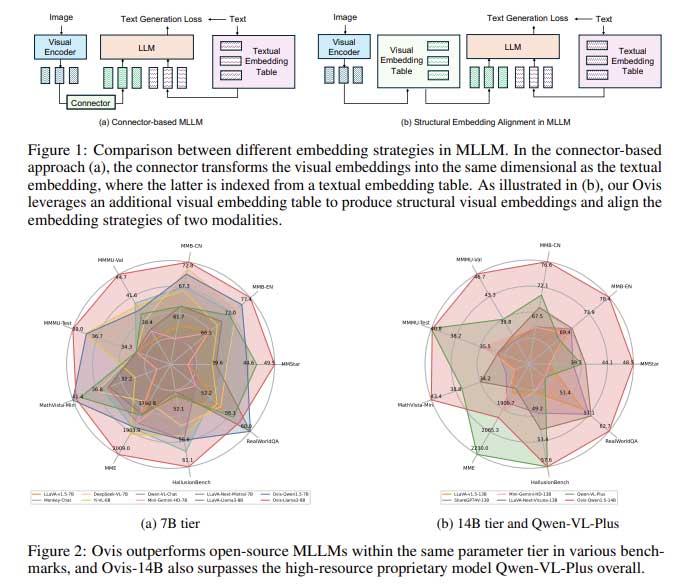
Ovis 的核心创新在于使用视觉嵌入表将视觉标记与其文本对应项对齐。概率标记表示每个图像块,并多次索引视觉嵌入表以生成最终的视觉嵌入。此过程捕获每个视觉块的丰富语义,并产生结构上类似于文本标记的嵌入。与依赖线性投影将视觉嵌入映射到联合空间的传统方法相比,Ovis 采用概率方法来生成更有意义的视觉嵌入。这种方法使 Ovis 能够克服基于连接器的架构的局限性,并在多模态任务中实现更好的性能。
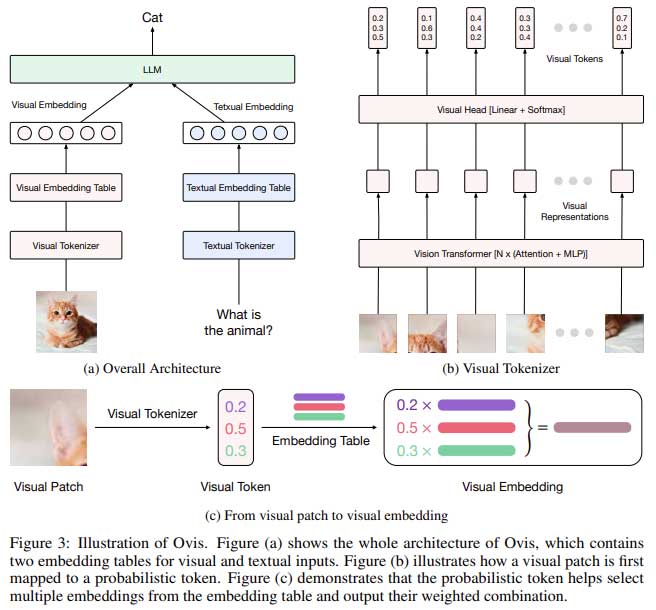
对 Ovis 的实证评估表明,它优于其他类似规模的开源 MLLM。例如,在 MathVista-Mini 基准测试中,Ovis 得分为 1808,明显高于其竞争对手。同样,在 RealWorldQA 基准测试中,Ovis 的表现优于 GPT4V 和 Qwen-VL-Plus 等领先的专有模型,得分为 2230,而 GPT4V 得分为 2038。这些结果凸显了 Ovis 在处理复杂多模态任务方面的优势,使其成为该领域未来发展的有希望的候选者。研究人员还在一系列通用多模态基准测试中对 Ovis 进行了评估,包括 MMBench 和 MMStar,其中它始终以 7.8% 到 14.1% 的优势超越 Mini-Gemini-HD 和 Qwen-VL-Chat 等模型,具体取决于具体基准测试。

研究要点:
- 结构对齐: Ovis 引入了一种新颖的视觉嵌入表,可以在结构上对齐视觉和文本嵌入,从而增强模型处理多模态数据的能力。
- 卓越的性能: Ovis 在各种基准测试中均优于类似规模的开源模型,比基于连接器的架构提高了 14.1%。
- 高分辨率功能:该模型在需要对高分辨率图像进行视觉理解的任务中表现出色,例如 RealWorldQA 基准测试,其得分为 2230,比 GPT4V 高出 192 分。
- 可扩展性: Ovis 在不同的参数层(7B、14B)中表现出一致的性能,使其能够适应各种模型大小和计算资源。
- 实际应用:凭借其先进的多模式功能,Ovis 可应用于复杂且具有挑战性的现实场景,包括现有模型难以解决的视觉问答和图像字幕制作等。
总之,研究人员成功解决了视觉和文本嵌入之间长期存在的不一致问题。通过引入结构化视觉嵌入策略,Ovis 可以实现更有效的多模态数据集成,从而提高各种任务的性能。该模型能够超越类似参数尺度的开源和专有模型(例如 Qwen-VL-Max),这凸显了其作为多模态学习新标准的潜力。研究团队的方法为开发 MLLM 迈出了重要一步,为未来的研究和应用提供了新的途径。
论文地址:https://arxiv.org/abs/2405.20797
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/52735.html
