

研究团队:
张文韬,张保勇,袁德明:南京理工大学自动化学院;
施阳:加拿大维多利亚大学机械工程系
文章下载:
Wentao ZHANG, Yang SHI, Baoyong ZHANG & Deming YUAN. Improved Dynamic Regret of Distributed Online Multiple Frank–Wolfe Convex Optimization. Sci China Inf Sci, 2024, doi: 10.1007/s11432-023-4086-5
地址:https://www.sciengine.com/SCIS/doi/10.1007/s11432-023-4086-5;JSESSIONID=6dbd2052-e010-4700-9093-eda153defc3f
研究意义
近年来,随着人工智能和信息科学技术的不断发展,多智能体分布式优化受到国内外学术界和工业界广泛关注。分布式在线优化允许局部损失函数随迭代时间变化且仅需损失函数的后验信息,能够有效应对复杂、实时的动态应用场景。Frank-Wolfe算法因其线性子程序的轻量化计算特征在有高维和结构性约束的分布式在线优化问题研究中备受关注,并涌现了一些分布式在线算法。
然而,现有动态遗憾标准下多智能体分布式在线Frank-Wolfe优化研究工作尚不完善且仍存在诸多限制,如现有动态遗憾上界受限于优化问题的多个规律特征、所得结果存在较大的保守性、算法步长依赖于某些先验知识使其难以在实际场景中准确调整。上述局限性极大地削弱了算法的灵活性和应用性。因此,设计有效算法消除这些局限性并建立更优的收敛性能具有显著的研究意义和研究价值。
本文工作
针对多智能体分布式在线约束优化问题,本文在时变多智能体网络上,通过结合一种多步迭代技术,提出一种分布式在线多步迭代Frank-Wolfe算法(如下图)。并从在线优化与多步迭代技术原理的视角,给出了多步迭代技术能够增强分布式在线优化算法收敛性能的理论依据。

然后,在凸和光滑的损失函数条件下,建立了所提算法的次线性动态遗憾上界和线性子程序复杂度上界。相比于不使用多步迭代技术的分布式在线Frank-Wolfe算法,所提算法不仅保留了线性子程序在处理有高维约束优化问题的优势,还消除了算法步长依赖先验知识的局限性,实现了更紧的动态遗憾上界。特别地,当已知某些先验知识时,可进一步获得算法的最优遗憾界。此外,考虑到多步迭代技术所要求的额外计算成本,讨论了动态遗憾、计算成本和通信成本之间的权衡关系。
本文的创新点如下:
(1) 通过结合多步迭代技术,本文提出了一种时变网络拓扑上的分布式在线多步迭代Frank-Wolfe算法,该算法可以有效地解决具有结构和高维约束集的分布式在线优化问题。
(2) 从在线优化与多步迭代技术原理的视角,给出了多步迭代技术能够增强分布式在线优化算法收敛性能的理论依据。在两种内迭代参数的设置下,均建立了动态遗憾上界和线性子程序复杂度上界。值得一提的是,所得遗憾上界不依赖于带有先验知识的步长,且可以通过调整参数获得更紧的遗憾界。
(3) 在已知某些先验知识的情况下,给出了算法的最优遗憾界。此外,考虑到多步迭代技术所要求的额外计算成本,讨论了动态遗憾、计算成本和通信成本之间的权衡关系。
实验结果
本文所设计的分布式在线多步Frank-Wolfe优化算法在下式所示的分布式岭回归问题上进行了验证,并在两种约束上,即单纯形约束和范数球约束,分析了所提算法的有效性。
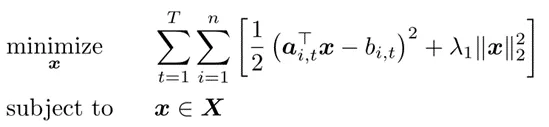
(1) 单纯形约束
在单纯形约束下,图1-a展示了所提算法的平均动态遗憾的上包络线、下包络线以及全局值曲线都是收敛的,这一致于理论结果。通过比较现有算法和本文所提算法,可知所提算法收敛地更快,且固定内迭代参数设置下算法性能优于时变设置。此外,图1-c给出了不同内迭代参数对算法收敛性能的影响。
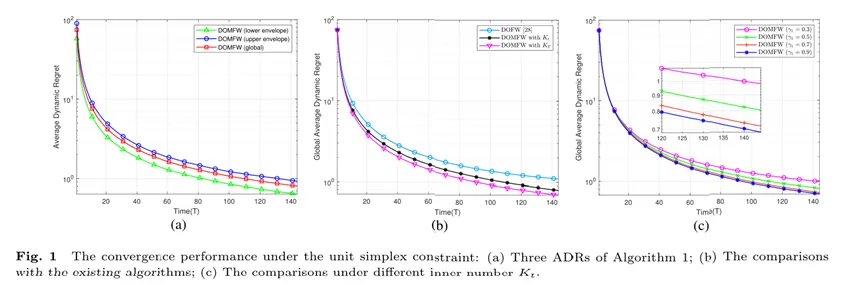
(2) 范数球约束
在范数球约束下,图2展示了所提算法是收敛的,且通过对比仿真实验证实了多步迭代技术在收敛性能方面具有显著优势。根据不同内迭代参数对算法收敛性能的影响实验可知,内迭代参数的合理设置对于权衡获得高质量决策和节省资源之间的关系非常重要。
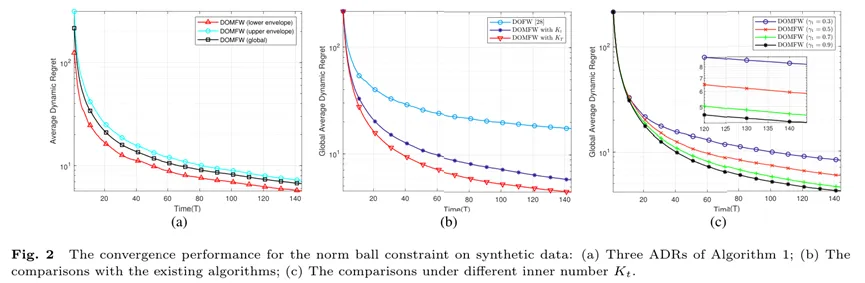
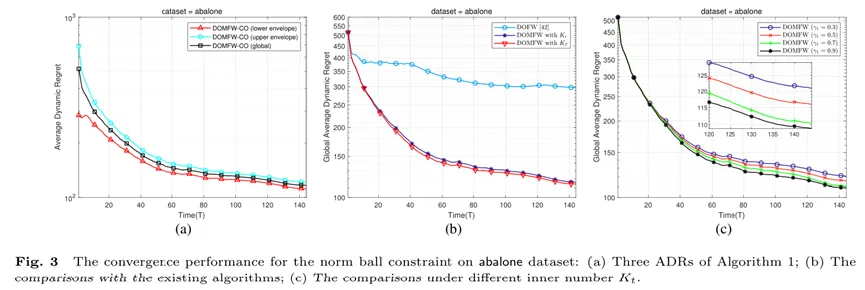
最后,为了进一步说明所开发算法的有效性和广泛适用性,本文在真实数据集上探究了所提算法的收敛性能。图3所得实验结果与合成数据上的仿真结论以及理论分析是一致的,充分验证了所提算法的有效性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
