
神经音频编解码器通过将连续音频信号转换为离散标记,彻底改变了音频的压缩和处理方式。该技术使用在离散标记上训练的生成模型来生成复杂的音频,同时保持音频的出色质量。这些神经编解码器显著提高了音频压缩率,使得在不影响音质的情况下更有效地存储和传输音频数据成为可能。
然而,目前使用的许多神经音频编解码器模型并非设计用于区分不同的声音域。相反,它们是在大量不同的音频数据集上进行训练的。例如,口语的谐波和结构与音乐或环境噪音的谐波和结构非常不同。无法区分不同的音频域使得有效地建模数据和管理声音制作变得困难。这些模型很难处理各种音频格式的独特品质,这可能会导致性能不理想,特别是在需要精确控制声音制作的应用中。
为了克服这些问题,一个研究小组推出了 Source-Disentangled Neural Audio Codec (SD-Codec),这是一种结合源分离和音频编码的独特技术。SD-Codec 的目标是通过专门识别音频信号并将其分类到不同的域中来增强当前的神经编解码器。与其他潜在空间压缩技术不同,SD-Codec 为各种音频源(包括音乐、音效和语音)分配离散表示或不同的码本。由于这种划分,模型能够更好地识别和保持每种音频形式的独特品质。
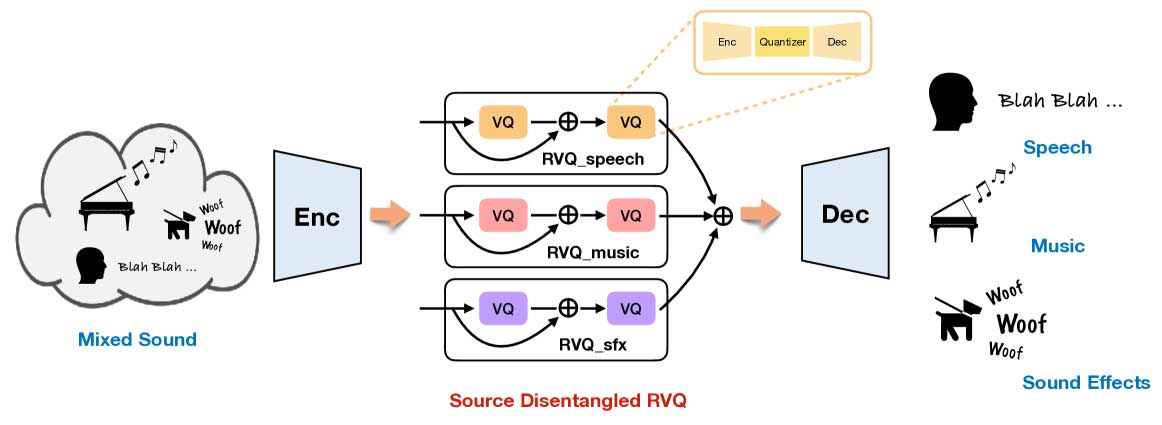
SD-Codec 通过同时学习如何分离和重新合成音频,提高了神经音频编解码器中潜在空间的可解释性。除了帮助保持高质量的音频重新合成之外,它还通过使区分各种来源变得更加容易,从而为音频创建过程提供了额外的控制。由于 SD-Codec 可以在潜在空间内分离来源,因此它可以更精确地操纵音频输出,这对于需要生成或编辑详细音频的应用程序非常有用。
根据实验结果,SD-Codec 成功分离了各种音频源,并在音频再合成质量方面表现出色。这种分离能力带来了更好的可解释性,使理解和处理生成的音频变得更加简单。
该团队总结了他们的主要贡献如下:
- SD-Codec 已被提出,它是一种神经音频编解码器,除了重建高质量音频外,它还能从输入音频片段中提取不同的音频源,例如语音、音乐和音效。这种双重功能提高了编解码器对各种音频处理应用的适应性和实用性。
- 已经研究了 SD-Codec 如何利用共享残差矢量量化 (RVQ)。结果表明,无论是否使用通用码本,性能都不会改变。这突出了编解码器内音频输入的分层处理,并意味着 RVQ 的浅层负责存储语义信息,而较深的层则专注于捕捉局部声学特性。
- 我们已使用大规模数据集来训练 SD-Codec,结果表明它在源分离和音频重建方面表现良好。这种广泛的训练确保了模型在各种声学情况下的可靠性和功能性。
总之,SD-Codec 是神经音频编解码器的一大进步,提供了更先进、更易于管理的音频制作和压缩方法。
论文地址:https://arxiv.org/abs/2409.11228
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/52625.html
