
多年来,口语对话系统领域取得了长足的发展,从简单的语音界面发展到能够维持实时对话的复杂模型。Siri、Alexa 和谷歌助手等早期系统开创了声控交互的先河,允许用户通过语音命令触发特定操作。这些系统虽然具有开创性,但仅限于事实检索或控制设备等基本任务。然而,GPT 和 Gemini 等大型语言模型(LLM)的出现扩大了口语对话系统的作用,使其能够处理多轮、开放式对话。然而,在当前的语音技术中,复制类似人类的对话仍然是一个挑战,因为人类的对话通常节奏很快,而且包括重叠的语音。
语音对话系统的一个关键问题是多个组件的顺序处理导致的延迟。当前的系统依赖于语音识别、文本处理、自然语言生成以及最终的语音合成等阶段。每个阶段都会引入一定程度的延迟,导致响应时间长达数秒,远远达不到人类对话中典型的快速交流。当前的系统逐个处理对话,这意味着一个说话者必须说完,另一个说话者才能回应,这无法捕捉到真实对话的流畅性。情绪、语调和重叠语音等非语言线索经常被忽略,从而降低了对话质量和整体用户体验。
现有的口语对话工具主要遵循管道模型。在此框架中,首先使用自动语音识别 (ASR) 将语音转换为文本,然后系统使用自然语言理解 (NLU) 来推导文本的含义。基于这种理解,通过自然语言生成 (NLG) 生成响应,然后通过文本转语音 (TTS) 引擎将其转换回语音。这些系统适用于简单的单轮交互,例如查询天气或设置计时器。但是,这些步骤之间的累积延迟会导致长时间延迟。由于这些系统在文本域内运行,因此情感或上下文音频提示等非语言方面会丢失,从而限制交互的丰富性。
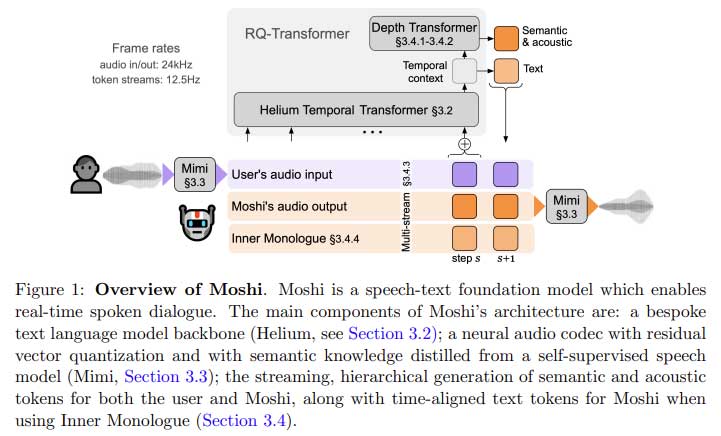
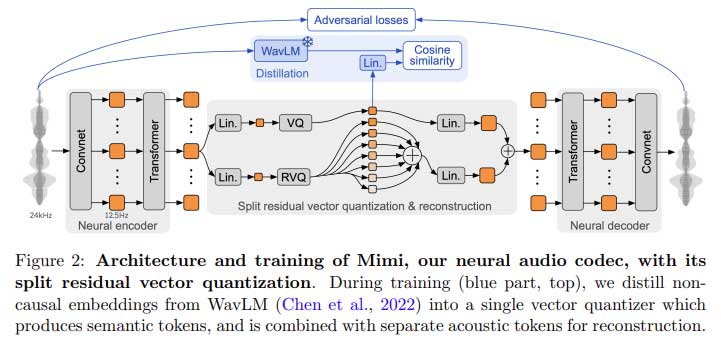
Kyutai Labs 的研究人员推出了 Moshi,这是一款提供全双工通信的尖端实时口头对话系统。与强制采用回合制结构的传统系统不同,Moshi 允许进行连续、不间断的对话,用户和系统可以同时说和听。Moshi 建立在名为 Helium 的基础文本语言模型之上,该模型包含 70 亿个参数,并根据超过 2.1 万亿个公共英语数据标记进行训练。Helium 主干提供推理能力,而系统则通过名为 Mimi 的较小音频模型得到增强。Mimi 使用神经音频编解码器对音频标记进行编码,实时捕捉语义和声学语音特征。这种双流方法消除了严格轮流说话的需要,使得与 Moshi 的交互更加自然和人性化。
Moshi 的架构包括多项创新功能,旨在优化性能和对话流畅度。引入的关键技术之一是“内心独白”方法,该方法将文本标记与音频标记按层次结构对齐。这使系统能够生成连贯且上下文准确的语音,同时保持实时响应率。Moshi 的理论延迟仅为 160 毫秒,实际延迟为 200 毫秒,明显低于现有系统中观察到的几秒钟延迟。Moshi 的多流模型同时处理系统和用户的语音,捕捉自然对话中常见的复杂对话动态,例如重叠语音和中断。
Moshi 的测试结果显示其在多个指标上均表现出色。在语音质量方面,即使在嘈杂或重叠的场景中,Moshi 也能产生清晰、易懂的语音。该系统可以维持长时间对话,上下文跨度超过五分钟,并且在口头问答任务中表现出色。与之前的模型相比,Moshi 可以适应各种对话动态,而之前的模型通常需要一系列明确的说话者轮换。值得注意的是,该模型的延迟与人与人之间互动中测得的 230 毫秒相当,这使得 Moshi 成为第一个能够近乎即时响应的对话模型。这一进步使 Moshi 处于实时全双工口语语言模型的前沿。
Moshi 的架构经过了严格的测试,显示出其在处理一系列口头对话任务方面的有效性。该模型在多个测试案例中根据文本理解、语音清晰度和一致性进行了评估。消融研究(其中删除或更改了特定模型组件)进一步强调了 Moshi 的分层标记生成和内心独白功能的重要性。在一项特别具有挑战性的口头问答测试中,Moshi 的表现优于现有模型,展示了其语言深度和在不牺牲性能的情况下处理实时音频流的能力。

总之,Moshi 代表了口头对话系统的重大飞跃。通过解决延迟、轮换和非语言交流等主要挑战,可以提供更加动态和自然的对话体验。Helium 丰富的语言知识与 Mimi 的实时音频处理能力相结合,使 Moshi 能够生成反映人类对话复杂性的语音。该模型将响应时间缩短到接近人类的水平,并结合情感和语境线索来提高互动质量。凭借其突破性的实时性能和处理延长的多轮对话的能力,Moshi 为口头对话系统树立了新标准。
地址:https://github.com/kyutai-labs/moshi
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/52511.html
