
IBC 是历史悠久,规模最大的国际广播及新媒体技术盛会。本工作是上海交通大学图像所 MediaLab 在 IBC 2024 大会成果介绍。本文提出了一种基于预训练神经渲染场 (NeRF) 模型的生成式 3D 视频会议系统,旨在解决传统视频会议系统在弱网络条件下存在的画面冻结和质量下降问题。该系统通过提取和编码面部参数进行传输,同时接收和解析来自其他参与者的参数来生成图像。实验结果表明,该系统在比特率低于 5kbps 的情况下仍能保持良好的视频质量,其客观和主观质量分别与 HEVC 编码器在 18kbps 和 50kbps 时的水平相当。通过整合实时面部参数跟踪、实时通信 (RTC) 和实时体积视频渲染,该系统为 3D 视频会议协作提供了新的可能性。
作者:Jianglong Li, Jun Xu, Yuelin Hu, Zhiyu Zhang, Li Song
来源:IBC 2024
论文题目:NeRF based 3D generative video conferencing system
论文链接:https://www.ibc.org/technical-papers/ibc2024-tech-papers-nerf-based-3d-generative-video-conferencing-system/12075.article
内容整理:李江龙
引言
目前,主流的视频会议系统依赖于传统的视频编码框架,如HEVC、VVC和AV1等,它们虽然在像素级保真度、通用性和稳定性以及硬件性能要求方面具有优势,但在极低带宽条件下的表现不佳。因此,研究者们开始探索基于深度学习的生成方法,这些方法能够利用有限的信息生成面部图像,为视频会议中的面部语义通信提供了新的可能性。
近年来,随着人工智能生成内容(AIGC)技术的发展,3D面部表示技术如NeRF和3D GS的出现,为视频通信领域带来了创新的解决方案。这些技术能够通过神经网络预测3D点的颜色和密度,实现从2D图像到3D模型的转换,并提供实时渲染的能力。
本文提出了一个基于预训练的NeRF模型的生成式3D视频会议系统,该系统能够在极低的比特率下实现高保真的3D头部重建和实时渲染。与WebRTC等传统系统相比,该系统仅传输面部参数而非图像数据,显著降低了比特率,同时在视频质量上与传统系统相当。此外,该系统还集成了实时面部跟踪、实时通信(RTC)和实时体积视频渲染技术,增强了3D视频会议的协作潜力。
本研究的主要贡献包括:
- 提出了一个基于开源组件的3D视频会议系统,所有模块均实时且实用,整体端到端延迟低于90毫秒,是首个集成3D表示模型的实时系统。
- 通过参数编码模块和姿势控制模块,实现了超低比特率传输,同时支持自由视角观看。
- 实验结果表明,该系统在5kbps以下的比特率下,视频质量在客观和主观指标上均优于传统的x265编码器在18kbps和50kbps的表现。这标志着在视频会议领域,通过创新的3D生成技术,即使在网络条件受限的情况下,也能提供高质量的视频通信体验。
系统概览
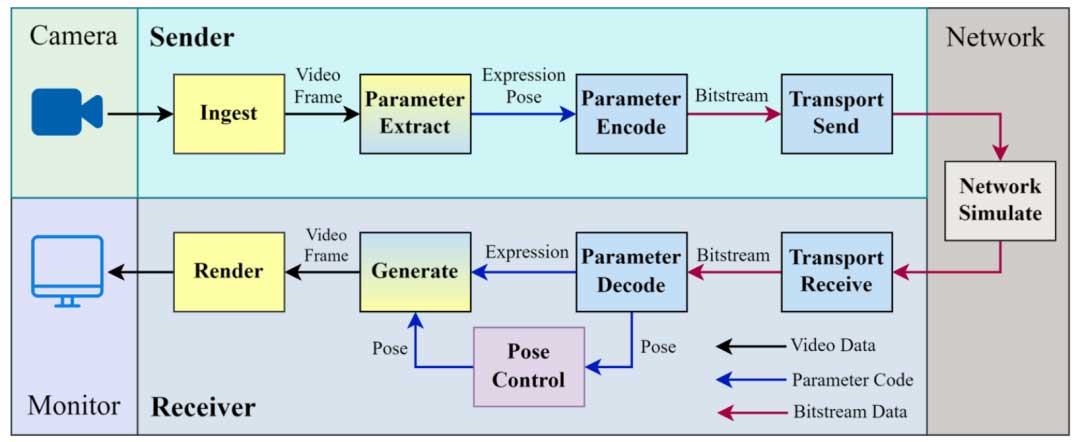
图1展示了我们提出的3D生成式视频会议系统的框架,包括发送方、网络模拟和接收方。我们视频会议系统的工作原理如下:在发送方,首先从摄像头捕获视频。然后从每一帧中提取面部表情参数和姿势参数。这些参数被编码成比特流以进行网络传输。在接收方,从网络接收比特流,解码以检索表情参数和姿势参数,并用它们来驱动基于NeRF的3D头部表示模型生成和显示面部图像。在我们的系统中,不同的模块通过FIFO(先进先出缓冲区)进行通信,这使得模块间能够进行异步数据传输和缓冲,从而实现实时操作。
图像摄取和渲染
在发送方,摄取模块从摄像头捕获视频数据。然后,视频数据被分割成帧并送入FIFO队列,该队列将其转发给后续处理模块。
在接收方,渲染模块负责显示接收到的视频帧。为了确保视频平稳渲染,我们建立了一个播放缓冲区,用于K帧,并设置第一帧的播放时间为基准时间。每个后续帧根据帧率被分配一个目标播放时间。
参数提取模块
该模块从视频帧中提取面部表情参数和头部姿势参数,采用开源的CPEM模型,配备预训练的权重。
CPEM使用线性3D形变模型(3D Morphable Model,3DMM)作为其3D面部模型,该模型包括形状和纹理组件。形状组件细分为面部基础和表情基础。CPEM提取的表情参数代表表情基础的系数,以FaceWarehouse数据库为指导,该数据库为每个表情基础明确标注了特定的语义(例如,左眼闭合,左眼眯起)。CPEM生成的姿势参数包括旋转和位移参数。旋转参数控制观看的角度,位移参数控制人脸在渲染框中的位置。
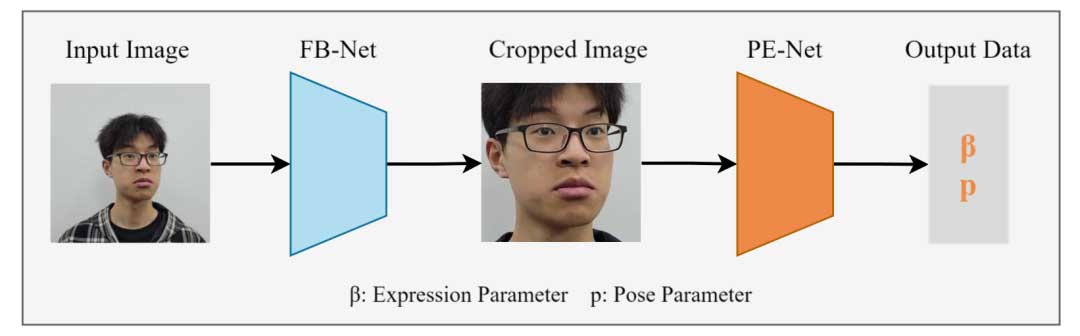
提取模块的工作流程如图2所示。它从人脸边界网络开始,从图像中分割出面部区域。随后,将分割的面部图像输入到基于ResNet50架构的参数估计网络,以估计表情系数和姿势参数。提取的参数信息被发送到FIFO,然后传递到编码模块进行编码。
编码和解码
此过程对提取的表情和姿势参数(浮点数)进行编码,包括量化、预测和零阶指数哥伦布编码。
在量化步骤中,每个浮点数被转换为8位整数。为了提高量化精度,我们记录了模型训练数据集中每个维度的最大值和最小值。这些界限用作表情参数和姿势参数的上限和下限。
预测模块利用帧间预测计算连续帧之间的差异,只通过零阶指数高尔码编码编码结果残差,从而显著减少要编码的数据量。
解码模块执行逆操作以恢复表情参数和姿势参数。
生成模块
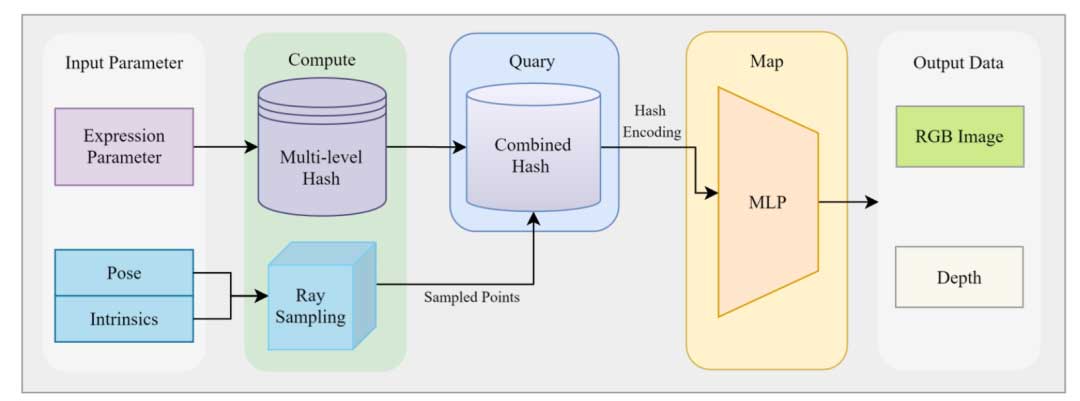
接收端的生成模块使用表情和姿势参数来驱动NeRF模型,从特定视点生成面部图像。在生成过程中,表情参数决定面部表情,而姿势参数确定生成面部的观察角度。接收者可以使用发送者传输的姿势参数进行真实视角的面部生成,或者通过姿势控制模块从任意视角生成。我们的系统支持沿x、y和z轴的自由视角生成,范围在±45°内。
这一功能是使用开源的NerfBlenderShape实现的。NerfBlenderShape是基于NeRF的语义面部模型,可以在10-20分钟内使用短单目RGB视频输入进行训练,并可以根据表情和姿势参数在几十毫秒内渲染面部图像。它将面部语义表示为基于MLP的隐式函数,并将表情基础与多级哈希表关联起来。每个哈希表对应特定的面部语义,表情系数可以从多个哈希表中组合编码。渲染期间使用的摄像机参数包括内在参数和由头部姿势表示的外在参数。
在NerfBlenderShape提供的开源方法的基础上,我们使用自己的专有数据集重新训练了NeRF模型,以获得生成模块中使用的权重。训练过程的详细描述在实现部分介绍。
发送和接收
发送和接收模块使用QUIC作为底层传输协议,以提高数据传输的效率和可靠性。发送模块首先将编码的面部表情和姿势参数封装成QUIC数据包。然后,这些数据包通过网络发送,在QUIC协议的帮助下快速且可靠地到达对等方。利用QUIC的顺序特性和可靠传输,系统确保了表情和姿势数据的连续性和完整性。此外,QUIC的一往返时间(1RTT)握手和强大的拥塞控制机制有效降低了传输延迟。
我们还提供了一个网络模拟模块,该模块使用TC工具来模拟网络轨迹,这有助于验证我们提出的系统对弱网络条件的适应性。为了更好地模拟各种和极其弱的网络条件,我们选择在单个主机上部署我们的系统。网络传输通过本地回环进行,使用TC工具进行控制。
系统实现
我们在Ubuntu 20.04 64位操作系统上使用Python实现了我们的3D生成式面部视频会议系统。整个系统运行在两块Intel® Xeon® Gold 6240 CPU 2.60GHz上,配备256 GB的RAM,并使用两块GeForce RTX 4090 GPU进行神经网络计算。为确保实时性能,发送端的提取模块和接收端的生成模块各自在单独的GPU上运行。
NeRF模型训练
遵循RAD-NeRF提供的方法,我们构建了自己的数据集。数据集构建包括以下步骤:
- 视频录制:拍摄一段100秒的视频,捕捉各种面部表情和头部姿势。
- 语义分割:将每一帧进行语义分割,以识别背景、头部、颈部和躯干。
- 背景提取:通过分析图像序列中的前景和背景,智能提取稳定的背景图像。
- 躯干图像提取:使用第2步中的语义分割图像和原始图像,提取躯干图像,并将原始图像中的背景替换为第3步中的稳定背景,以创建真实的图像。
- 面部跟踪:使用面部跟踪获取每张图像的姿势参数,包括三维欧拉角和三维平移,然后将其转换为标准的4×4位置矩阵。
- 表情参数提取:使用CPEM模型从每张图像中提取46维的表情参数。
- 训练文件准备:将表情和姿势参数编译成训练文件。
使用NerfBlenderShape提供的训练方法,我们重新训练了我们的NeRF头部模型,以适应我们的会议系统。为了优化,我们采用了Adam优化器,初始学习率设置为0.001,动量betas配置为(0.9, 0.99)。为了在训练过程中有效管理学习率,我们引入了一个MultiStepLR调度器,在预定的时期动态调整学习率。整个训练过程设计运行200个周期。
基于QUIC的网络传输
Quiche是QUIC传输协议和HTTP/3的实现,由IETF规定。它提供了一个用Rust实现的QUIC内核,并提供C/C++ API。利用Quiche库,我们使用C++设计了发送和接收模块。通过FIFO命名管道实现基于Python的系统和基于C++的网络传输模块之间的通信。
加速模型推理速度
为了实现实时的3D视频会议系统,我们使用了一些推理加速方法。具体来说,在发送端,面部分割和CPEM模型导出为ONNX格式以代替PyTorch进行推理。在接收端,面部图像的渲染使用fp16精度进行。此外,两个模块在系统激活前都经过预热处理,以提高模型推理的效率。
实验
比特率和延迟性能是视频会议系统最关键的指标,直接影响用户体验。我们分别对这两个指标进行了实验。
比特率性能
我们使用传统的HEVC编码器x265进行比较分析。测试视频包括十个视频序列,每个序列有1000帧。每帧被裁剪到512×512并使用8位量化深度进行编码。
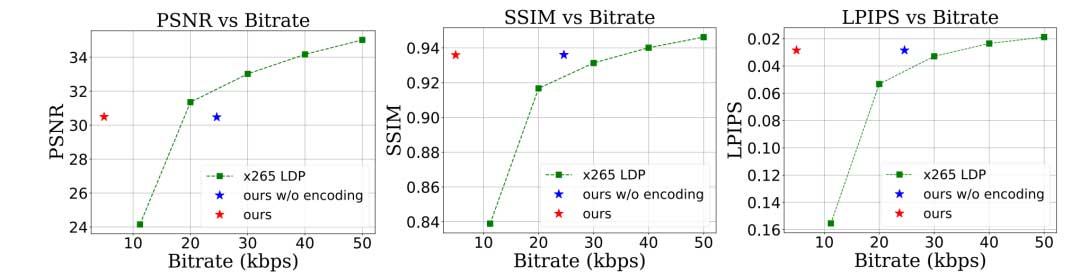
从图4中可以看出:
- 对人脸参数进行编码不影响生成的图片质量,而,码率降低为四分之一(红星和蓝星)。
- 本系统在约5kbps的码率下的PSNR相当于x265编码器18kbps,SSIM和LPIPS相当于x265编码器的35kbps.

如图5所示,我们在快速头部运动期间的优势更加明显。对于快速移动的图像,我们的系统仅使用x265十分之一的比特率就实现了更高的主观质量。这是因为x265依赖于相邻帧之间的预测,而我们的基于语义的方法独立处理每帧的表情参数和姿势参数。
延迟性能

每个模块都作为单独的进程运行,因此端到端的延迟等于每个模块延迟的总和,即89.5毫秒。延迟最高的模块是生成模块,为49.2毫秒,低于50毫秒,这表明我们的系统可以在20帧每秒的帧率下实时运行。
未来工作方向
- 由于当前3D重建技术的局限性,我们的系统仅生成头部图像。未来,我们计划包括上半身图像,以增强现实感。
- 我们的系统仅传输面部信息,生成的图像缺乏背景。未来的工作将专注于整合2D虚拟背景或将参与者的3D头部头像放置在同一3D虚拟环境中。
- 我们采用基于残差的预测性编码进行编码和解码。网络数据包丢失可能会影响相邻帧的解码。为了应对弱网络条件,我们将引入GOP策略,以限制GOP内解码的依赖性。
- 本系统要求参与者拥有彼此的预训练NeRF模型,而这些基于NeRF的头部模型体积庞大(超过500MB)。对于实际部署,我们计划整合在线训练。对于没有模型的新参与者,我们将最初进行传统的视频会议,并在20分钟内基于接收到的面部图像训练个人的NeRF头部模型。当网络条件恶化时,这些预训练模型可以用于会议。此外,已经有关于将这些模型压缩到20MB以下的工作,我们计划将其整合到我们的系统中。
结论
在本文中,我们提出了并实现了一个超低比特率的生成式3D视频会议系统。利用最新的3D面部重建技术,我们实现了在超低比特率下进行3D视频会议的目标,同时提供了可接受的视频质量。我们的系统支持从任意角度观看,为参与者提供了沉浸式体验。在未来的工作中,我们将进一步改进我们的系统,为视频会议系统提供新的范例。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
