
IBM 推出 PowerLM-3B 和 PowerMoE-3B 标志着 IBM 在提高语言模型训练效率和可扩展性方面取得了重大进展。IBM 基于创新方法推出了这些模型,这些方法解决了研究人员和开发人员在训练大型模型时面临的一些关键挑战。这些模型建立在IBM 的 Power 调度器之上,体现了 IBM 致力于在优化计算成本的同时提高 AI 能力。
语言模型已成为许多人工智能应用的基础,从自动客户支持到高级自然语言理解系统。大规模语言模型(例如 GPT、LLaMA 等)已被证明能够有效地生成连贯的文本、理解上下文以及解决需要推理的复杂问题。但是,训练这些模型需要大量的计算资源。超参数(例如学习率、批大小和标记数)的最佳设置对于确保这些模型在训练期间的有效性至关重要。尽管早期模型有所改进,但优化这些超参数仍然是一项艰巨的任务,尤其是在扩展到数十亿个参数时。
学习率调度问题
学习率是训练深度神经网络,尤其是 LLM 时最关键的超参数之一。精心选择的学习率可以确保更快的收敛速度,同时避免过拟合。传统的学习率调度器(如余弦调度器)已被广泛用于训练大型模型。但是,它们通常需要预先定义训练步数,而且不够灵活,无法适应训练过程中不断变化的数据。此外,训练过程中的中间检查点通常不是最佳的,导致中断后恢复训练时效率低下。随着模型大小、批量大小和训练标记的增加,这个问题会变得更加复杂。
IBM 的 Power 调度器旨在通过引入与批量大小和标记数量无关的学习率调度器来解决这些问题。这就确保了无论这些变量如何变化,都能高效地训练模型。Power 调度器基于学习率与训练标记数之间的幂律关系。它能让模型在训练过程中动态调整学习率,而无需提前指定训练步数。
IBM 的 Power 调度器
Power 调度器的开发旨在克服现有学习率调度器的局限性。余弦调度器等传统调度器的一个主要问题是,它们需要提前定义训练步数。这种缺乏灵活性的问题对于大规模模型尤为突出,因为在大规模模型中,很难预测需要多少训练标记或训练步数才能达到最佳性能。
Power 调度器引入了一种灵活的方法,可根据训练标记的数量和批量大小调整学习率。幂律方程模拟了这些变量之间的关系,确保学习率在整个训练过程中保持最佳状态,即使训练代币数量发生变化也是如此。
Power 调度器的一个主要优点是,它允许在不牺牲性能的情况下进行持续训练。这对于希望在初始训练阶段后对模型进行微调或在训练过程中调整训练数据的企业来说尤其有用。从任何检查点恢复训练而无需重新优化学习率的能力确保了训练的效率和效果。
PowerLM-3B 和 PowerMoE-3B 模型
PowerLM-3B 和 PowerMoE-3B 模型的推出是 Power 调度器优势的实际体现。这两个模型均使用 IBM 的 Power 调度器进行训练,并在各种自然语言处理任务中展现出最先进的性能。
PowerLM-3B
PowerLM-3B 是一个具有 30 亿个参数的密集 Transformer 模型。它使用高质量开源数据集和合成语料库进行训练,训练了 1.25 万亿个标记。密集模型架构可确保所有模型参数在推理过程中处于活动状态,从而为各种任务提供一致的性能。
尽管训练时使用的 token 数量比其他最先进的模型要少,但 PowerLM-3B 的性能却与大型模型相当。这凸显了 Power 调度器的效率,确保模型即使在训练 token 数量有限的情况下也能有效学习。
PowerMoE-3B
PowerMoE-3B 是一个 mixture-of-experts (MoE) 模型,采用 IBM 的创新 MoE 架构。与密集模型相比,MoE 模型在推理过程中仅激活模型参数的子集,从而使其计算效率更高。PowerMoE-3B 拥有 30 亿个参数,但在推理过程中仅激活 8 亿个参数,从而显著降低了计算成本,同时保持了高性能。
PowerMoE-3B 是在 2.5 万亿个 token 上进行训练的,使用的数据组合与 PowerLM-3B 类似。mixture-of-experts 架构与 Power 调度器相结合,使该模型能够实现与具有更多参数的密集模型相当的性能,从而证明了 MoE 方法的可扩展性和效率。
实际应用和性能
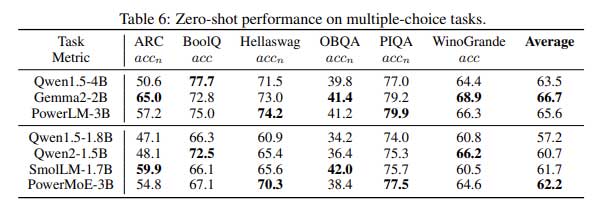
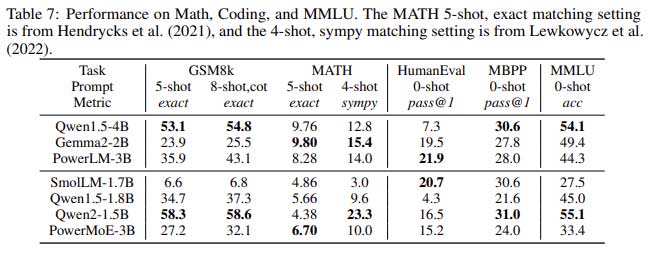
PowerLM-3B 和 PowerMoE-3B 在各种自然语言处理任务上进行了评估,包括多项选择题回答、常识推理和代码生成。结果表明,尽管 PowerMoE-3B 训练时使用的 token 更少,并且在推理过程中使用的活动参数也更少,但这些模型的表现仍与其他最先进的模型相当。
例如,PowerLM-3B 在 ARC(AI2 推理挑战赛)和 PIQA(物理交互问答)等任务上取得了高分,超越了许多具有类似参数数量的模型。另一方面,PowerMoE-3B 在需要计算效率的任务中表现出色,以更低的推理成本取得了具有竞争力的结果。
这些结果凸显了 IBM 的 Power 调度器和 MoE 架构在彻底改变大型语言模型的训练和部署方式方面的潜力。通过优化学习率并降低计算要求,这些模型为希望利用高级语言模型而无需承担与传统密集模型相关的巨额成本的组织提供了前进的道路。
结论
IBM 发布的 PowerLM-3B 和 PowerMoE-3B 标志着 LLM 和 NLP 领域取得了重大进展。事实证明,IBM 的创新型 Power 调度器是优化这些模型训练过程的高效工具,可实现更高效的训练和更好的可扩展性。通过结合密集和 mixture-of-experts 架构,IBM 提供了一个强大的框架来构建强大的 AI 模型,这些模型可以在各种任务中表现良好,同时减少计算开销。
模型地址:https://huggingface.co/collections/ibm/power-lm-66be64ae647ddf11b9808000
相关论文:https://arxiv.org/pdf/2408.13359
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/52317.html
