
大规模语言模型在涉及多发言人语音合成、音乐生成和音频生成的生成任务中取得了重大进展。将语音模态集成到多模态统一大型模型中也变得流行起来,例如 SpeechGPT 和 AnyGPT 等模型。这些进步主要归功于神经编解码器模型中使用的离散声学编解码器表示法。然而,它在弥合连续语音和基于标记的语言模型之间的差距方面带来了挑战。虽然当前的声学编解码器模型提供了良好的重建质量,但在高比特率压缩和语义深度等领域仍有改进空间。
现有的方法主要集中在三个方面来应对声学编解码模型的挑战。第一种方法包括通过 AudioDec 和 DAC 等技术提高重建质量,前者证明了鉴别器的重要性,后者则通过量化器滤除等技术提高质量。第二种方法使用了增强的压缩主导开发成果,如 HiFi-Codec 的并行 GRVQ 结构和 Language-Codec 的 MCRVQ 机制,这两种方法都以较少的量化器实现了良好的性能。最后一种方法旨在加深对编解码器空间的理解,TiCodec 对与时间无关的信息和与时间有关的信息进行建模,而 FACodec 则将内容、风格和声音细节分开。
来自浙江大学、阿里巴巴集团和 Meta 人工智能基础研究的团队提出了一种新型声学编解码器模型 WavTokenizer,与音频领域以往的先进模型相比,它具有显著的优势。WavTokenizer 通过减少量化器的层数和离散编解码器的时间维度,实现了极致压缩,一秒 24kHz 音频只需 40 或 75 个 token。此外,它的设计包含更宽的 VQ 空间、扩展的上下文窗口、改进的注意力网络、强大的多尺度判别器和反傅里叶变换结构。它在语音、音频和音乐等不同领域都表现出了强大的性能。
WavTokenizer 的架构设计用于跨多语言语音、音乐和音频等领域的统一建模。其大型版本使用来自各种数据集(包括 LibriTTS、VCTK、CommonVoice 等)的约 80,000 小时数据进行训练。其中型版本使用 5,000 小时子集,而小型版本则使用 585 小时 LibriTTS 数据进行训练。使用来自各种框架(例如 Encodec 2、HiFi-Codec 3 等)的官方权重文件,根据最先进的编解码器模型评估 WavTokenizer 的性能。它在 NVIDIA A800 80G GPU 上进行训练,输入样本为 24 kHz。使用具有特定学习率和衰减设置的 AdamW 优化器对所提出的模型进行优化。
结果证明了 WavTokenizer 在各种数据集和指标上的出色表现。在 UTMOS 指标和 LibriTTS 测试清洁子集上,WavTokenizer-small 的表现比最先进的 DAC 模型高出 0.15,这与人类对音频质量的感知非常吻合。此外,该模型在所有指标上的表现都优于 DAC 的 100 个标记模型,仅使用 40 个和 75 个标记,证明了其在使用单个量化器进行音频重建方面的有效性。在 STOI、PESQ 和 F1 分数等客观指标上,WavTokenizer 的表现与具有 4 个量化器的 Vocos 和具有 8 个量化器的 SpeechTokenizer 相当。
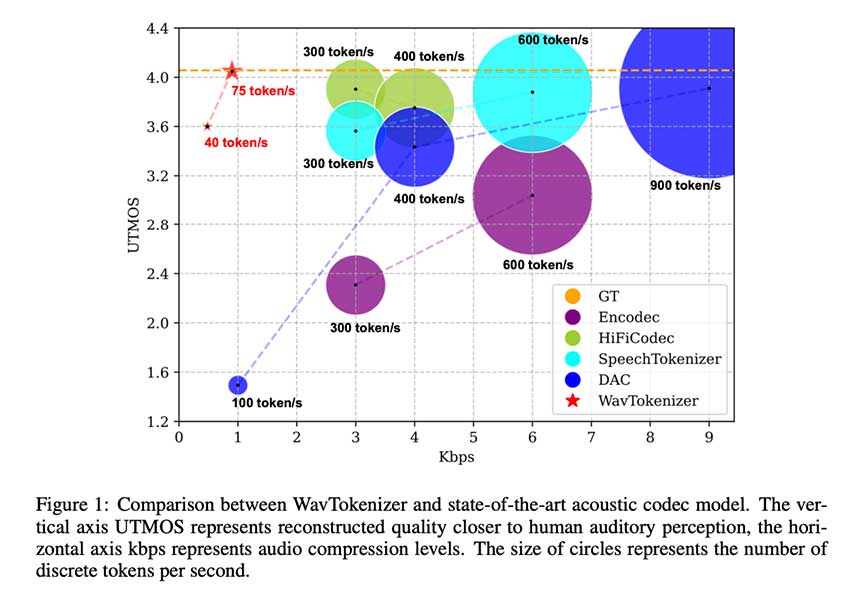
总之,WavTokenizer 显示了声学编解码器模型的重大进步,它能够将一秒钟的语音、音乐或音频量化为 75 或 40 个高质量token。该模型在 LibriTTS 清洁测试数据集上取得了与现有模型相当的结果,同时提供了极高的压缩率。研究小组对 VQ 空间和解码器背后的设计动机进行了全面分析,并通过消融研究验证了每个新模块的重要性。研究结果表明,WavTokenizer 有可能在各个领域彻底改变音频压缩和重建。未来,研究人员计划巩固 WavTokenizer 作为声学编解码器模型领域尖端解决方案的地位。
论文地址:https://arxiv.org/abs/2408.16532v1
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
