
论文提出了一种无需预对齐的解析引导时序一致性模型(PGTFormer),用于盲视频人脸修复。PGTFormer 通过语义解析的引导选择最佳的面部先验,以生成时序一致且无伪影的结果。具体方法包括预训练一个时空向量量化自动编码器,从高质量的视频人脸数据集中提取表达丰富的上下文先验,然后通过时序解析引导的代码书预测器(TPCP)在不同姿态下基于面部解析上下文线索恢复人脸,无需进行面部预对齐。最后,通过时序保真度调节器(TFR)增强时序特征的交互,从而提高视频的时序一致性。
来源:IJCAI 2024
题目:Beyond Alignment: Blind Video Face Restoration via Parsing-Guided Temporal-Coherent Transformer
作者:Kepeng Xu 等人
论文链接:https://arxiv.org/abs/2404.13640
开源代码:https://github.com/kepengxu/PGTFormer
内容整理:徐克鹏
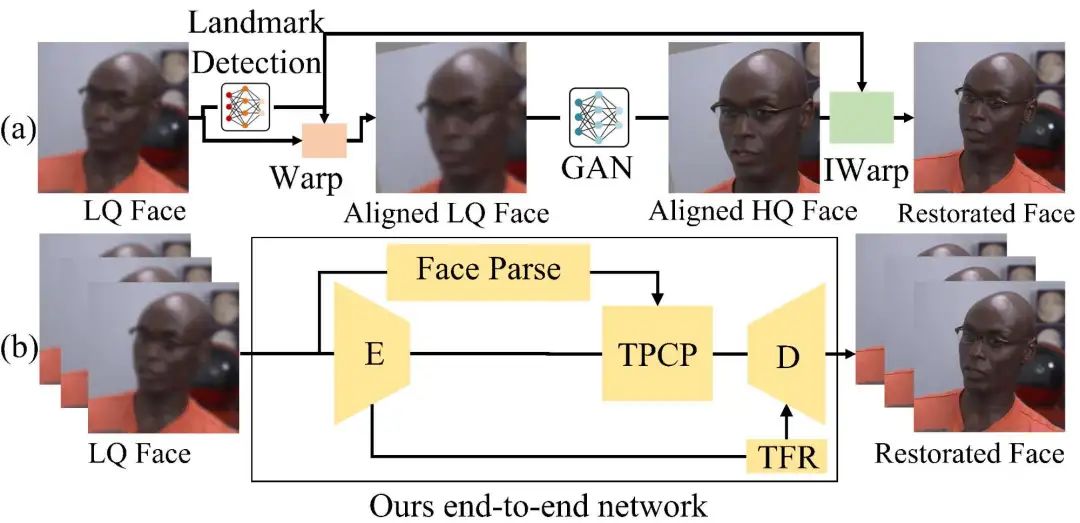
视频人脸修复在计算机视觉领域中占有重要地位,尤其在高质量视频处理的场景下,如电影修复、视频通信和监控系统等。然而,现有的大多数方法主要集中于静态图像处理,缺乏对视频中时序信息的有效捕捉,且通常依赖复杂的对齐操作。在处理长视频时,容易出现恢复结果不一致的问题。为解决这些挑战,提出的方法提出了PGTFormer(Parsing-Guided Temporal-Coherent Transformer),这是第一个专门为视频人脸修复设计的端到端方法,能够避免传统对齐操作,显著提升修复的连贯性和效率。
方法概述
网络架构设计
PGTFormer的网络架构设计分为两个关键阶段,分别负责捕捉高质量视频人脸的时空特征以及实现高效的端到端人脸修复:
- 第一阶段:TS-VQGAN(时空VQGAN)的训练
在这个阶段,提出的方法训练了TS-VQGAN模型,用于捕捉高质量视频人脸的时空特征。TS-VQGAN通过自监督学习生成逼近真实人脸的先验嵌入,为PGTFormer的后续修复任务提供了丰富的先验知识基础。 - 第二阶段:PGTFormer的训练
在这一阶段,PGTFormer利用第一阶段生成的高质量人脸先验,通过人脸解析模块和时空Transformer模块,完成视频人脸的修复。具体流程为:首先对输入的低质量视频帧进行解析,提取出关键面部特征;随后通过时空Transformer模块查询TS-VQGAN生成的先验信息,并通过解码器将这些高质量特征整合到原始视频中,生成具有高度时序一致性的高质量人脸修复结果。
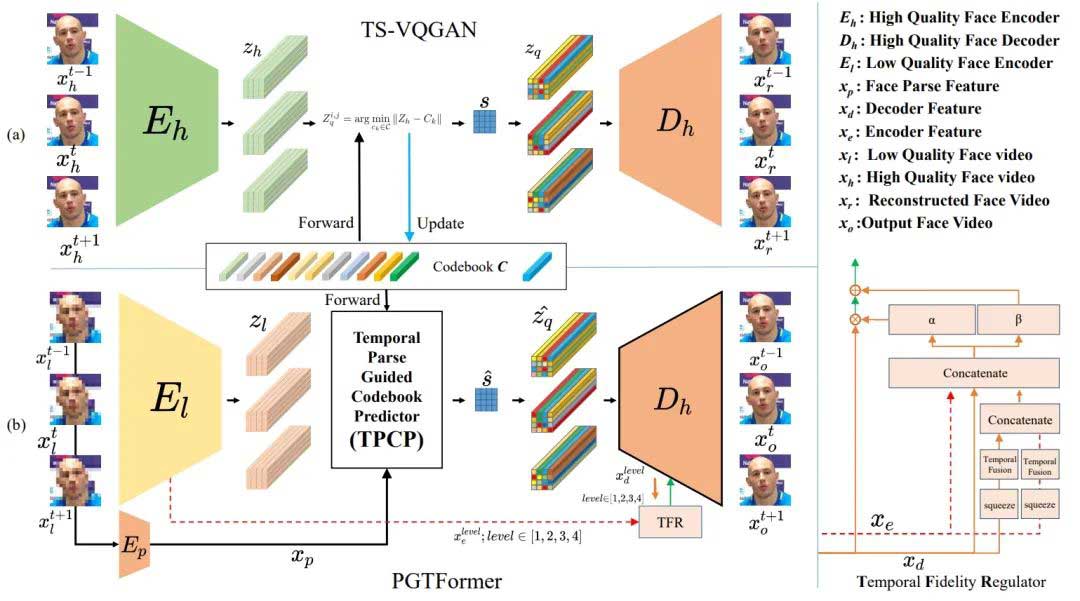
设计理念与创新点
PGTFormer的设计理念旨在解决传统视频人脸修复方法中的两个主要挑战:时序一致性不足和复杂的对齐操作。
时空先验的构建提出的方法通过构建时空VQGAN(TS-VQGAN)重建人脸视频,从而捕获高质量的视频人脸先验。这一先验信息为后续的修复任务提供了关键支持,使得系统能够在复杂姿态和光照变化下保持一致的修复效果。
对齐操作的简化传统的视频人脸修复方法通常需要复杂的对齐操作来确保帧与帧之间的准确匹配。这不仅增加了计算成本,还可能引入对齐误差,影响最终修复质量。PGTFormer通过去除对齐操作,采用端到端的解析引导方式,实现了更为简化的处理流程。通过利用语义解析引导的先验信息选择,PGTFormer能够生成更加稳定且自然的修复结果。
时空先验匹配PGTFormer利用Transformer匹配对应的高质量人脸先验,相比于仅仅依赖单帧的方案,既提升了匹配精确度,也提升了视频的连续性。通过在时序上捕捉更精确的特征,PGTFormer能够显著提升最终的修复效果,实现更加连贯自然的面部表现。
时序保真度增强为了进一步提升修复的视觉效果,PGTFormer还采用了时序保真度调节器(TFR)来增强时序特征的交互。TFR的作用是在不同视频帧之间建立更强的时序关联,从而提高视频的整体一致性和自然感。这一机制有效避免了在视频处理过程中可能出现的抖动和不稳定现象。
实验验证与结果分析
定量结果分析
为了全面评估PGTFormer的有效性,提出的方法在多个公开数据集上进行了实验,并与当前最先进的修复方法进行了对比分析。以下展示了PGTFormer在多项定量指标上的表现,包括对齐和非对齐人脸视频的训练与测试结果。

- PSNR(峰值信噪比):PGTFormer在对齐和非对齐视频上的PSNR值分别达到30.74和29.66,显著优于其他方法,证明了其在高质量图像重建方面的能力。
- SSIM(结构相似性):PGTFormer在SSIM指标上表现优异,分别在对齐和非对齐数据集上达到0.8668和0.8408,表明其在保持结构一致性上的出色能力。
- LPIPS(感知相似度):PGTFormer的LPIPS值分别为0.2095(对齐)和0.2230(非对齐),显示出其生成的图像在视觉质量上更接近高质量图像,且视觉一致性更佳。
- 其他指标(Deg、LMD、TLME、MSRL):PGTFormer在其他衡量面部特征、扭曲程度、时间一致性和细节保留的指标上也表现突出,全面超越了现有最先进的修复方法,展现出其强大的修复能力。
主观视觉对比实验
除了定量评估,提出的方法还进行了主观视觉对比实验,以进一步验证PGTFormer在实际应用中的效果。实验结果显示,PGTFormer在恢复面部细节方面表现尤为突出,尤其在眼睛、嘴巴等关键部位的纹理还原上更为清晰自然。

与其他方法相比,PGTFormer生成的人脸更具自然感,色彩还原度更高,几乎没有伪影或不自然的过渡现象。
结论
PGTFormer作为首个专为视频人脸修复设计的端到端模型,在解决时序一致性和对齐操作复杂性方面取得了显著进展。通过解析引导和时序一致性建模,PGTFormer成功实现了更加高效且自然的修复效果。未来,提出的方法将继续优化PGTFormer的网络结构,并探索其在更广泛的视频增强任务中的应用潜力,力求在实际应用中展现更多的技术突破。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
