
神经辐射场 (NeRF) 在照片般逼真的静态场景中表现出色,激发了众多促进体积视频的努力。然而,由于表示体积视频需要大量数据,渲染动态和长序列辐射场仍然具有挑战性。在本文中,我们提出了一种新的动态 NeRF 表示和压缩的端到端联合优化方案,称为 JointRF,从而与以前的方法相比显着提高了质量和压缩效率。具体而言,JointRF 采用紧凑的残差特征网格和系数特征网格来表示动态 NeRF。这种表示可以在不影响质量的情况下处理大运动,同时减少时间冗余。我们还引入了一个顺序特征压缩子网络来进一步减少时空冗余。最后,表示和压缩子网络在 JointRF 内进行端到端训练。大量实验表明,JointRF 可以在各种数据上实现卓越的压缩性能。
题目:JointRF: End-to-End Joint Optimization for Dynamic Neural Radiance Field Representation and Compression
作者:Zihan Zheng*, Houqiang Zhong*, Qiang Hu, Li Song et al.
来源:ICIP 2024 Oral
文章地址:https://arxiv.org/abs/2405.14452
内容整理:钟后强
引言
照片般逼真的体积视频在虚拟现实和远程呈现中提供身临其境的体验。动态神经辐射场 (NeRF)在表示照片般逼真的体积视频方面表现出巨大潜力。然而,使用 NeRF 存储和传输体积视频仍然存在挑战,尤其是对于涉及任意运动和长持续时间的序列。困难在于确定一种有效的表示和压缩方法,以便动态 NeRF 传递和存储长序列。
直接将逐帧的静态 NeRF 方法扩展到动态场景是不现实的,因为它们忽略了场景的时空连续性,导致网络参数过多。一些方法将辐射场扩展到4D时空域,但这些方法在渲染质量上表现欠佳,并且在流媒体场景中面临较大的模型存储挑战。目前,只有少数工作专注于动态辐射场的压缩以用于流媒体,ReRF 是其中的代表。尽管 ReRF 通过传统的图像编码方法减少了动态特征的冗余,但传统图像编码器不适合高维特征域,导致动态细节丢失和压缩效率降低。
本文提出了一种新方法 JointRF,通过联合优化动态 NeRF 的表示和压缩,获得更高的质量和压缩效率。受 FactorFields 的启发,JointRF 将辐射场分解为系数特征网格和基特征网格。JointRF 显式地建模长参考基函数与非长参考基函数之间的残差特征网格。对于第一个关键帧,JointRF 仅使用长参考基函数和系数网格表示。对于后续帧,则使用紧凑的残差网格和系数网格来补偿误差和新观察到的区域。这种表示法的主要优势在于充分利用相邻帧之间的特征关联。此外,JointRF 将特征网格依次进行量化和熵编码,以进一步减少冗余。
本文的主要贡献如下:
- 提出了一种新的端到端学习方案 JointRF,可以联合优化动态NeRF的表示和压缩,获得优异的 RD 性能,并消除了复杂的多阶段训练需求。
- 提出了高效且紧凑的表示方法,将 4D 辐射场表示为一系列残差特征网格,支持可流式的动态和长序列辐射场。
- 引入了一种熵最小化压缩方法,以确保辐射场特征具有低熵。
方法
动态残差表征
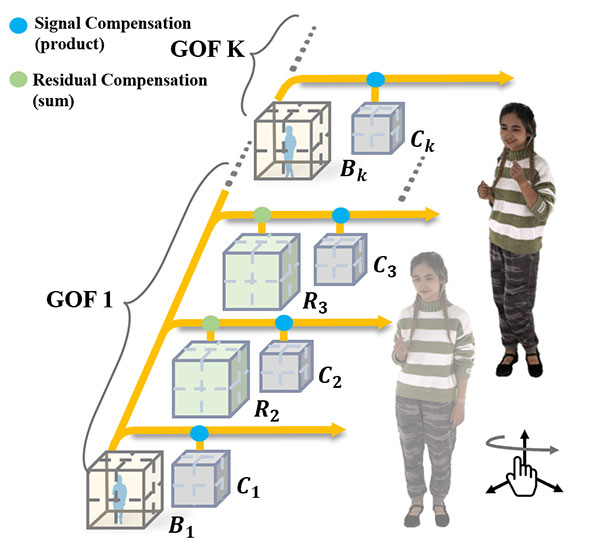


端到端联合优化
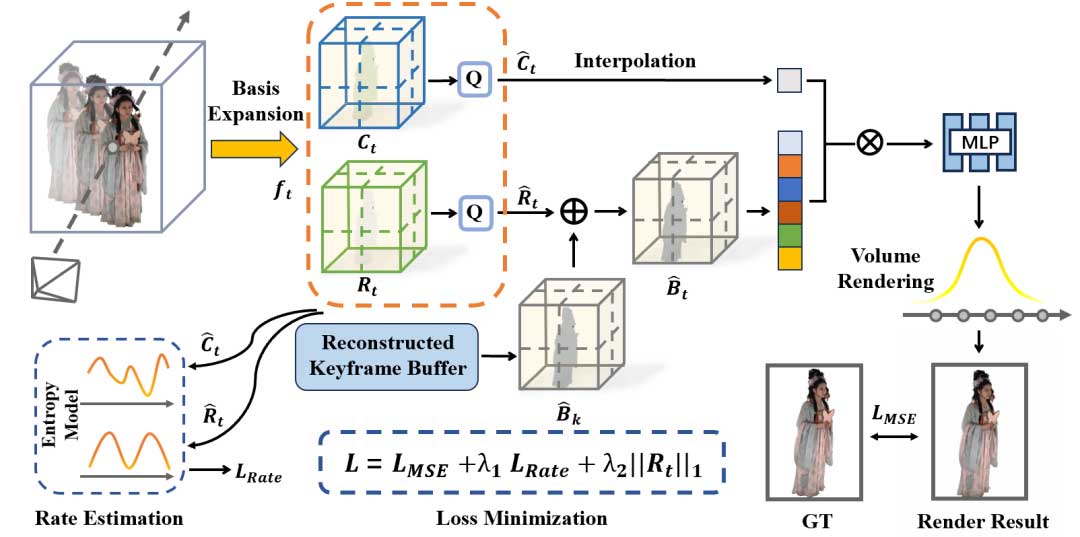
我们在此引入一种端到端的优化方法,联合优化动态辐射场的表示和压缩,以进一步提高压缩效率。我们提出的方法总体框架如图 2 所示。我们对特征网格ft进行模拟量化,并使用基于熵模型的比特率估计来支持端到端训练。JointRF的目标是在保持高重建质量的同时,确保从模型中学习到的辐射场表示具有低熵。
我们对量化后的特征网格进行熵编码,以生成高度压缩的比特流。如果能够在训练阶段获取比特率,那么可以将这一指标集成到损失函数中,以鼓励特征分布更低的熵,从而在网络更新时有效地施加比特率约束。然而,与量化过程不同,熵编码不保留梯度。为了解决这一问题,我们在训练阶段引入了熵模型,用于估计网格的熵值,这相当于压缩后比特率的下限。熵模型可以通过计算量化特征网格 ŷ 的累积分布函数(CDF)来近似其概率质量函数(PMF)。
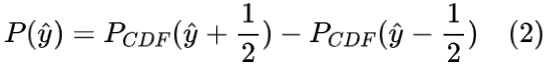
为了保持精度,我们避免对3D网格假设任何预设的数据分布。相反,我们在熵模型中构建了一种新的分布,以更接近实际数据分布。在训练过程中,熵模型预测压缩比特流的大小,作为整体损失的一部分。JointRF的训练过程如图2所示。
整个系统的总损失函数可以写为:

实验
对比实验
数据集: ReRF 和 DNA-Rendering 多视角视频数据集
1.表征质量-模型大小性能比较

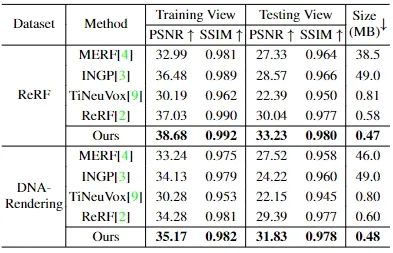
据我们所知,JointRF 是首个将动态 NeRF 与其相关的压缩过程以统一的端到端方式进行联合训练的方法。为了验证我们方法的有效性,我们与多种动态场景的先进方法进行了比较,包括 INGP、MERF、TiNeuVox、ReRF,进行了定性和定量的对比。在图 3 中,我们展示了两个序列的视觉结果。如图所示,我们的方法在模型大小的紧凑性和细节渲染的精确性方面,明显优于逐帧静态重建方法 INGP 和 MERF,以及动态场景重建方法 TiNeuVox 和 ReRF。在表 1 展示的定量比较结果中,我们分别计算了所有训练和测试视角中每帧的平均PSNR、SSIM 和存储空间。可以看出,我们的方法优于其他方法,以最低的模型存储获得了最好的重建质量。INGP 在建模 3D 场景时需要大量的存储负载,并且无法很好地建模未知视角。虽然 MERF 可以通过烘焙操作减少存储负载,但仍需要数十 MB,重建效果不理想。另一方面,TiNeuVox 能够在一致的内存占用内表示任意长度的序列。然而,随着帧数的增加,它会出现严重的模糊效应。与 ReRF 相比,我们的方法在 PSNR、SSIM 和模型存储方面也表现得更好。
2. 率失真性能
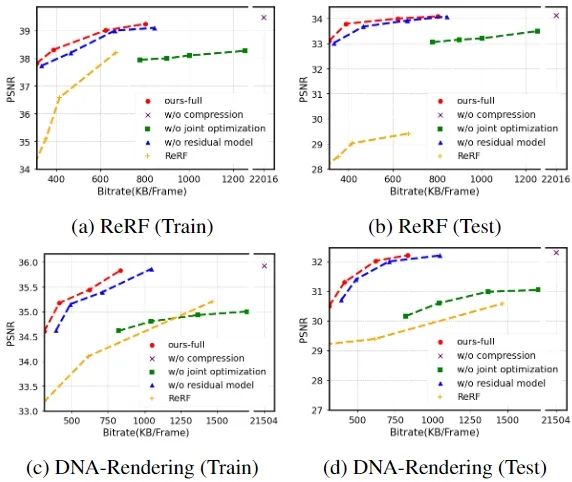
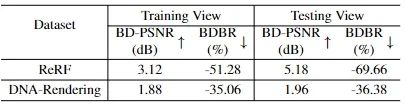
图 4 和 表 2 显示了我们的 JointRF 和 ReRF 之间的 RD 性能比较。与 ReRF 相比,我们的 JointRF 实现了更好的 RD 性能。在 ReRF 数据集上,我们观察到训练和测试视图的平均 BDBR 减少分别为 51.28% 和 69.66%。同样,在 DNA-Rendering 数据集上,训练和测试视图的平均 BDBR 节省分别为 35.06% 和 36.38%。我们方法的卓越性能可以归因于 ReRF 采用了传统的编码器,不适合特征网格压缩。相比之下,JointRF 对表示和压缩进行了端到端的联合优化,从而提高了 RD 性能。
3. 消融实验
我们在 ReRF 和 DNA-Rendering 数据集上对训练和测试视角进行了三项消融研究,以验证我们方法中各个组件的有效性。在第一次消融研究中,我们去除了压缩步骤,但保留了基于残差的动态建模。在第二次实验中,我们在训练过程中没有联合优化动态建模和压缩这两部分,而是在训练完成后再进行压缩。最后,我们逐帧单独建模动态场景并进行了联合优化,但未引入基于残差的表示。
消融研究的结果也在图 4 中展示。结果表明,我们的压缩方法在保持相当的重建质量的同时,将模型存储需求减少了大约40倍。此外,联合优化不仅可以减小模型大小,还可以略微提高 PSNR,因为通过联合优化获得的特征更易于压缩且对量化误差更具鲁棒性。最后,动态残差表示能够有效地实现更好的率-失真(RD)性能。消融研究的结果证明了我们的动态残差表示、压缩模块和联合优化策略的关键重要性。
结论
在本文中,我们提出了 JointRF,一种联合优化动态 NeRF 表示和压缩的新方法。我们首先介绍了一种适用于动态和长序列 NeRF 的高度紧凑的建模方法。为了进一步减少时空冗余,我们设计了一种能够与动态 NeRF 表示同步优化的压缩方法,实现端到端训练。我们的方法不依赖预设的特征分布,而是在训练过程中建模数据分布,以实现精确的比特率估计和可微分的定量近似。实验结果显示,JointRF 在多个数据集的率-失真(RD)性能上优于现有最先进的方法。凭借其在长序列动态场景中的独特表示和压缩能力,我们相信 JointRF 为体积视频的多种潜在应用奠定了坚实的基础。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
