
这篇文章主要介绍了该团队在深度强化学习(DRL)的基础上提出的一种高效的拥塞控制机制,即 QUIC 的近端带宽-延迟快速优化(PBQ)。它将传统的瓶颈带宽和往返传播时间(BBR)与近端策略优化(PPO)相结合。在 PBQ 中,PPO 代理根据网络状态输出拥塞窗口(CWnd)并进行自我改进,而 BBR 则指定客户端的步调速率。然后,将所提出的 PBQ 应用于 QUIC,并形成一个新版本的 PBQ 增强型 QUIC。实验结果表明,所提出的 PBQ 增强 QUIC 在吞吐量和 RTT 等方面都比现有的流行 QUIC 版本(如带 Cubic 的 QUIC 和带 BBR 的 QUIC)具有更好的性能。
题目:PBQ-Enhanced QUIC: QUIC with Deep Reinforcement Learning Congestion Control Mechanism
作者:Zhifei Zhang, Shuo Li, Yiyang Ge, Ge Xiong, Yu Zhang, Ke Xiong
论文链接:https://www.mdpi.com/1099-4300/25/2/294
来源:Entropy
内容整理:李俊杰
研究问题/任务
将 DRL 中的 PPO算法与 BBR 拥塞控制算法相结合,利用 DRL 在环境感知和决策方面的优点来提高拥塞控制算法的效率。
问题还重要吗
拥塞控制算法的一种新思路
当前 SOTA 工作与所属团队
- DRL Empowered Actor-critic ScheduleR,DEAR,结合 5G/B5G 混合网络多路径 QUIC 设计,BITS Pilani
- 基于多智能体 DRL 的多路径 quic ,国防科技大学
动机与贡献
动机
大多数启发式拥塞控制算法通常基于简单的网络模型感知网络状态,并采用固定策略(发生丢包或 RTT 增加时缩小窗口,在收到确认字符 ACK 时扩大窗口)。同时丢包事件并不意味着发生拥塞。但是,启发式拥塞控制算法无法区分这一点。当网络设置更改时,此问题会导致 QUIC 协议在吞吐量和延迟方面的性能不佳。
因此,为了使 QUIC 在不同的网络环境下获得更好的性能,文中尝试利用 DRL 在环境感知和决策方面的优点来设计 DRL 增强的 QUIC。
主要贡献
- 通过将近端策略优化(PPO)与传统 BBR 相结合,开发了一种新的拥塞控制机制,称为近端带宽-延迟快速优化(PBQ)。它能够在训练阶段有效提高收敛速度和链路稳定性。然后,将所提出的 PBQ 应用于 QUIC 协议,并形成了一个新版本的 QUIC,即 PBQ enhanced QUIC,旨在增强其自适应性和吞吐量性能。
- 使用连续动作比(continuous action ratio)作为 PBQ智能体的输出动作,来调整拥塞窗口。此外,在效用函数的设计中采用相对简单的目标函数公式作为优化目标,并引入了延迟约束。
- 在网络仿真软件 ns-3 上为 QUIC 构建了一个强化学习环境,进行 PBQ 增强的 QUIC 的训练和测试。实验结果表明,用 PBQ 增强的 QUIC 比现有的流行版本的 QUIC 实现了更好的 RTT 和吞吐量性能。
提出方法
PBQ的实现基本思路
- BBR 通过将传输中的总数据(inflight)等于 BDP( 瓶颈带宽 BtlBw × 往返传播时间 RTprop ),来最大化传输速率、最小化延迟和丢包。同时定期提高发送的数据量来探测 BtlBw 是否改变。
- PPO 算法是 PG 算法的升级。策略梯度上升算法主要思路为,获取环境数据、根据策略输出动作,同时根据采取的动作来计算奖励值,奖励值来训练策略。如果环境发生变化,之前训练的参数难以使用,从而诞生了 PPO。修改期望回报函数,以往的训练数据也可以用于当前的决策。
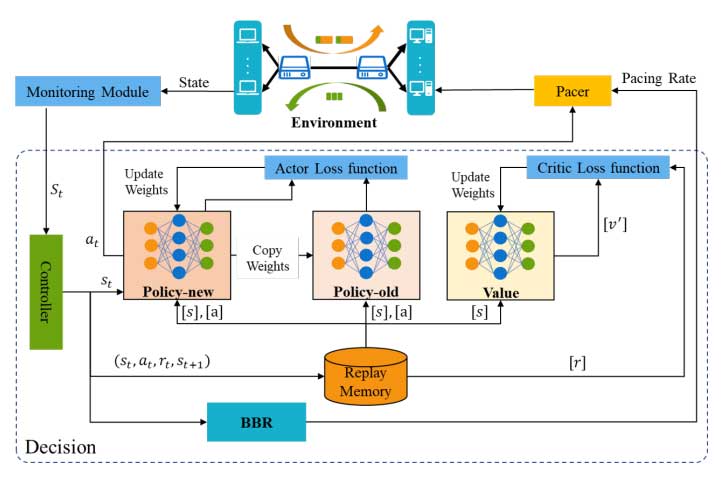
PBQ 将 PPO 与 BBR 相结合,以准确识别网络状态。PBQ 分为三个主要部分:监控、决策和 pacer 模块。
- 监控模块收集环境状态并将其发送到决策模块。决策模块根据网络状态输出动作,包括 at 和 pacer rate。Pacer 模块将操作分发给相应的发送方。
- 在决策模块中,控制器(controller)将网络状态分发给 PPO 和 BBR。
- PPO 部分使用 new policy 按照 st 输出 at,并通过 Pacer 将其反馈到环境中。old policy 则负责根据过去以及现在的的状态对 actor loss function 进行修改。actor loss function 则对 policy-new 的参数进行更新。
- 过往存储模块(replay memory)存储过去交互数据。
- 经过多次交互后,策略网络和价值网络根据过去的交互进行更新。
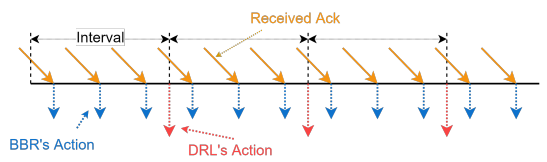
- Decision 模块采用了两级调节机制,如图2所示。底层 BBR 算法执行由 ACK 驱动的经典决策行为。DRL 代理评估网络拥塞,并根据监控模块的状态输出预测 BDP。
Reward Function Design
效用函数定义为:
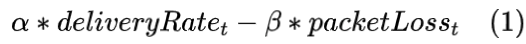
优化问题表示为:最大化给定 RTT 约束下的线性效用函数,即 RTTt ≤ minRTTt , t = 1,2,3…,n。其中 RTTt 表示时间 t 中的最后一个 RTT,minRTTt 表示从建立连接到时间 t 的最小 RTT。
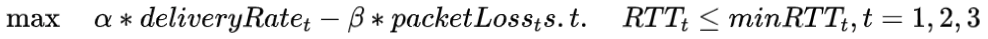
Rt 为回报函数,我们需要使得其期望回报最大。其中 γ 表示惩罚阈值,η 表示 RTTt > γ ∗ minRTTt 时的惩罚因子。

Action Design
借鉴传统拥塞控制中的加法增加乘法减少思想,将动作输出设置为 CWndRatio。CWndRatio 与拥塞窗口的映射关系如下:
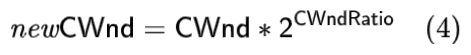
Learning Algorithm for PBQ
我们在 actor -critic 神经网络中使用 tanh 作为激活函数。由于传统拥塞算法中的状态转换并不复杂,因此在较为简单的神经网络上进行训练。该网络包括三层神经网络,其中隐藏层包含 64 个神经元。
- 在算法 1 的第 1-2 行,设置了训练回合 Episodes,并初始化了回放内存 D,用于存储状态、动作和奖励。策略参数 θnew 和 value 参数 φ 也使用随机权重进行初始化。我们将策略参数 θold 设置为等于 θnew。
- 算法在每个训练回合 episode 中重复执行,直到达到预定的回合数。
- 在每一次迭代,重置环境并获得初始状态 s0 和初始奖励 r0。
- 并且设置 t=1 作为时间步,如果当前时间步 t 是输出 ppo action,运行策略并获取动作 at。执行:

- 如果当前时间步 i 是 BBR 的动作,则输出 pacingRate_t
- 在每个步骤中,PBQ 收集网络状态 st 和 st+1、动作值 at 和相应的奖励 rt ,并更新重放内存 D。
- 当步骤数累积到策略更新阈值 update_timestep 时,将更新策略参数 θold、θnew 和 value 函数 φ。

实验设计与验证
团队在开源网络模拟器 ns-3 进行训练和测试,并将结果与使用不同拥塞控制算法的 QUIC 进行了比较。同时进行训练的时候和将 PPO 方法应用于拥塞控制部分的 quic 进行比较。一些参数如下:

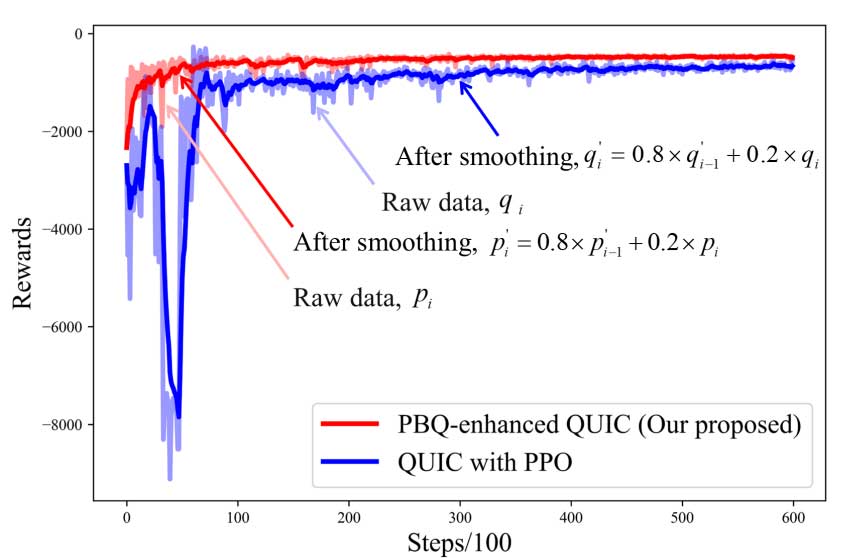
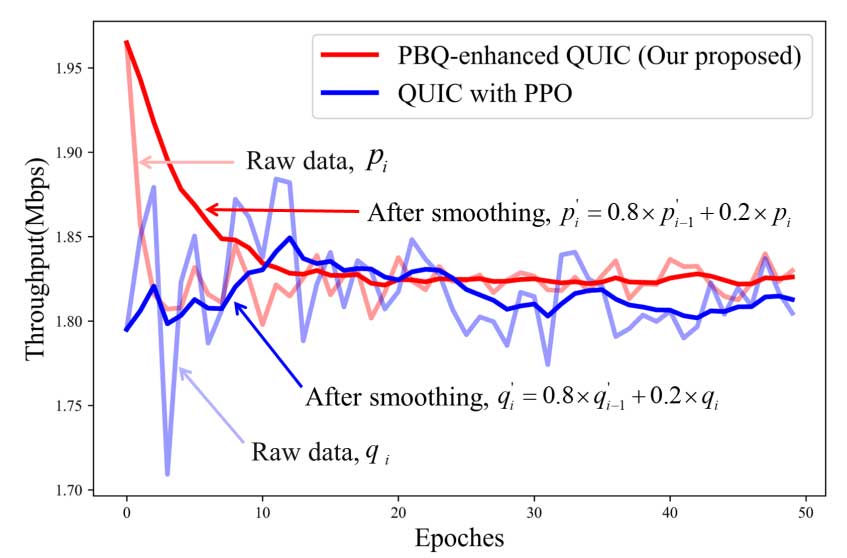
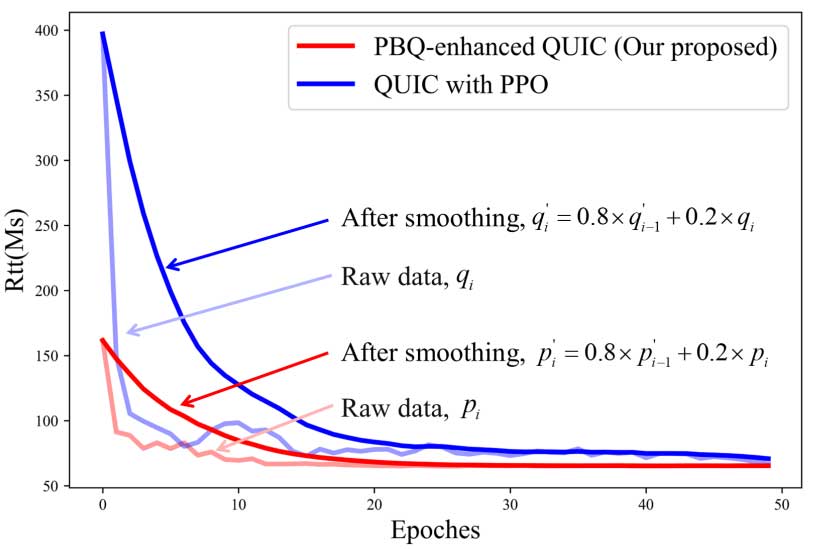
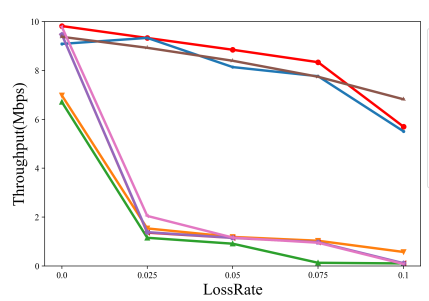
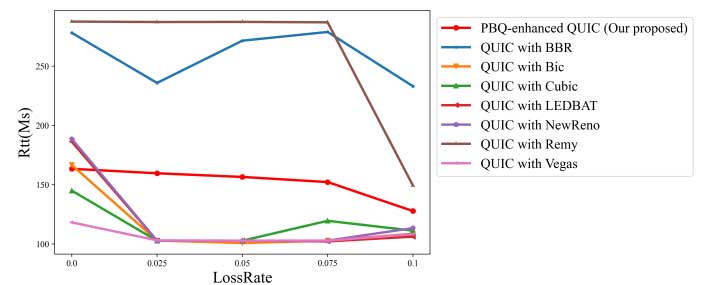
同时比较了 PBQ 增强的 QUIC 与使用当前基于学习的拥塞控制算法 Remy 等进行比较。当发生丢包时,采用将丢包事件作为信号的拥塞控制算法的 QUIC,例如 Cubic、NewReno,会频繁进入快速恢复,导致吞吐量低、RTT 低。随着丢包率提高,PBQ 在有很好的吞吐量的同时,兼顾了 RTT。

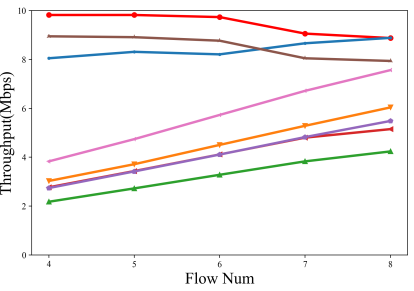
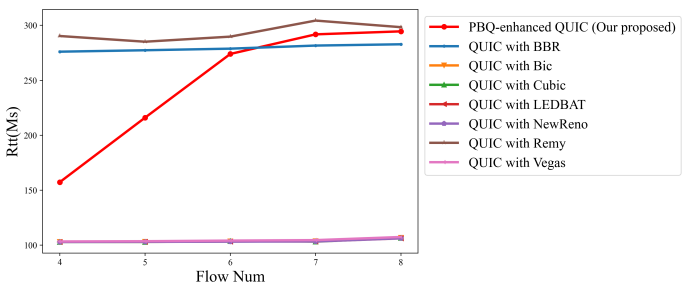
然后,将丢包率设置为 2.5%,并修改了流数,并比较了不同 QUIC 实现的吞吐量和延迟性能。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
