
零样本语音转换 (zero-shot voice conversion) 旨在保留语言内容的同时,将源说话人语音转换成任意目标说话人的语音。随着深度学习技术的引入,零样本语音转换技术取得了巨大的飞跃。但现有的零样本语音转换方法多在训练时进行同一语句的重建过程,而在推理时进行来自不同语句的说话人转换过程,二者之间的不匹配问题以及在解耦过程中存在的语义信息损失阻碍了转换的性能。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和喜马拉雅合作论文“Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy”被语音研究顶级会议INTERSPEECH2024接收。该论文提出了双模式训练策略下的基于渐进式损失约束和残差增强方法的鲁棒零样本语音转换模型 Vec-Tok-VC+,消除训练和推理之间的不匹配问题,减轻了解耦过程中的语义损失,有效提升了转换的自然度和相似度。现对该论文进行简要的解读和分享。
论文题目:Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
合作单位:喜马拉雅
作者列表:马林涵,朱新发,吕元骏,王智超,王子谦,贺雯迪,周鸿斌,谢磊
论文网址:https://arxiv.org/abs/2406.09844
Demo: https://ma-linhan.github.io/VecTokVC-Plus/
背景动机
语音转换 (VC) 旨在将源说话人的语音转换为目标说话人的音色,同时保持语言内容不变 [1]。其已被应用在许多场景中如隐私保护、电影配音等。VC 系统仅限于在预定义的说话人之间进行转换并需要大量的目标说话人语音数据,相比之下零样本语音转换 (zero-shot VC) 则将源说话人语音转换为仅一条语音的任意目标说话人音色,对于实际部署更为实用。它的主要挑战在于对未见说话人音色进行建模以及解耦源语义内容。
Zero-shot VC 的一种流行框架是将源语音分解为说话人音色信息和语义内容,然后将源说话人音色替换成目标说话人音色并与语义内容相结合。之前的许多方法提出采用特定设计的结构、损失函数、训练策略等实现零样本语音转换,如结合信息瓶颈层结构从内容表征中分离音色 [2][3]、采用对抗性训练策略 [4] 和互信息约束 [5] 等降低不同语音因素之间的关联,然而这些解耦方法不可避免地面临在音质和相似度之间的权衡。为了准确地建模音色信息,一些方法使用信号扰动技术改变语音的基频和音色 [6],利用说话人识别 (SV) [7] 模型来提取说话人表征,同时采用自动语音识别 (ASR) 模型来提取内容。然而之前的 VC 模型大多容量有限,难以有效利用大量的训练数据,进一步阻碍了其在真实条件未见说话人上实现高质量的转换。
此外,自监督学习(SSL)模型如 WavLM [8] 等能捕获语音局部结构以形成 SSL 特征用于零样本语音转换 [9]。由于 SSL 特征捕获了发音相似性并保留了语义内容和说话人信息 [8],kNN-VC [10] 引入了k近邻(kNN)方法,基于相似度匹配目标说话人语音的SSL特征用以替换源语音的SSL特征帧直接实现转换。它可以实现较高相似度的转换效果,但需要几分钟的目标说话人语音数据作为匹配集。
最近实验室提出的Vec-Tok [11] Codec 提供了一种新颖的零样本语音转换方式,即首先分别通过SSL模型和K-Means聚类量化将语音表示为连续声学特征和离散语义特征,然后将连续声学特征与源语义特征相结合作为模型的输入,受益于强大的建模能力和规模化的训练数据,Vec-Tok Codec 能从声学特征提示中捕获说话人的音色。然而其基于300类K-Means聚类的解耦过程可能会损伤源语音的语义内容和丢失发音变化信息,导致结果的自然度和内容准确性降低。此外,与大多数转换方法类似,其在训练时进行同一语句的重建而与推理时存在不匹配问题导致性能的下降。
为了解决这些问题,我们提出了改进自 Vec-Tok Codec 的鲁棒零样本语音转换模型 Vec-Tok-VC+,仅需3秒的目标说话人提示即可将残差增强的语义特征转换为目标语音。具体来说,受残差矢量量化 [12] 的启发,我们结合了残差增强的K-Means量化来进一步编码内容的残差信息和丰富的发音变化,以减轻解耦过程的信息损失,增强语义内容和副语言信息。为了获得更好的解耦效果并消除训练和推理之间的不匹配,我们设计了一个教师指导的细化过程以形成双模式(转换模式和重建模式)训练策略。我们进一步引入了多码本渐进式损失约束来帮助模型由粗到细粒度地逐步拟合目标语音。实验结果表明 Vec-Tok-VC+ 在零样本语音转换的自然度和相似度方面均优于强基线模型。
提出的方案
系统概述
如图1所示,Vec-Tok-VC+ 主要由三个部分组成:残差增强的 K-Means 解耦器、基于提示的Conformer [13] 转换器、一个教师模块。首先由SSL特征提取器提取连续的SSL特征,Vec-Tok-VC+是在此特征的基础上构建的。解耦器将残差增强设计与 K-Means 量化相结合,以去除说话人音色信息且获得增强的内容表征。将说话人语句的3秒片段作为说话人提示,并以源语音内容表征作为输入,Conformer转换器预测目标语音的SSL表征。我们在框架中引入了教师模块,在训练期间模拟推理转换的过程。最终采用 HiFiGAN 声码器从SSL表征重建波形。
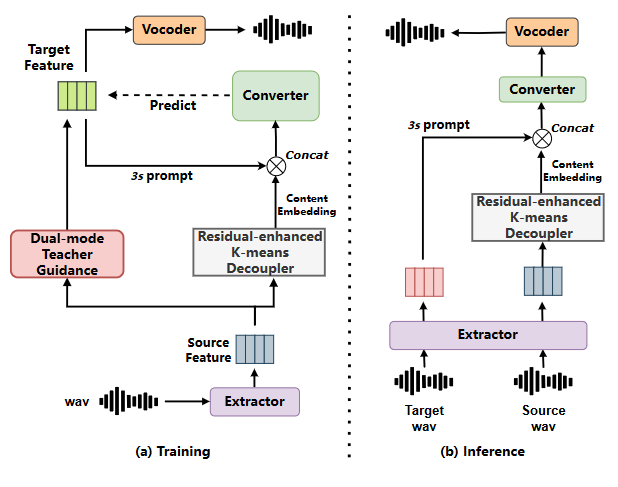
特征提取
我们没有使用频谱图或是语音编解码器特征,而是选择来自 XLS-R (wav2vec 2.0 的一种强大的多语种变体模型) 模型第六层的SSL特征来作为语音表征。Wav2vec 2.0 等的SSL特征已经被证明 [8],由于其丰富的语义和说话人信息,可以直接用于实现高质量的语音重建。
训练阶段
如图1(a)所示,Vec-Tok-VC+ 在给定说话人提示时将源语音SSL特征转换为目标语音的SSL特征。训练时源SSL特征和目标SSL特征具有相同的内容信息,而目标SSL特征的音色信息由教师模块确定。说话人提示是从目标SSL特征序列中随机截取的。
零样本推理
如图1(b)所示,给定目标说话人的SSL特征作为提示,VecTok-VC+ 输出具有源语义内容和目标说话人音色的转换后语音。
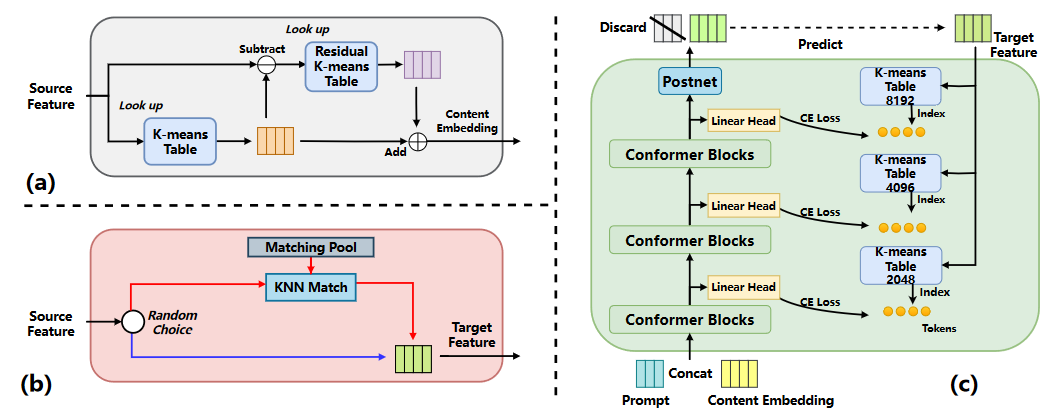
残差增强的 K-Means 解耦器
由于连续SSL特征包含丰富的语义和音色信息,通常做法是通过K-Means量化设置信息瓶颈,从内容信息中去除说话人音色,但会损失部分语言信息和发音变化,进而导致转换结果缺少来自源语音的丰富的韵律特征,自然度下降。受到残差矢量量化机制的启发,我们使用两个 K-Means 过程进行了残差增强的聚类,提升内容信息的解耦效果。如图2(a)所示,第一个1024类的K-Means将SSL特征量化解耦出内容信息。将量化前后的特征之间的残差作为输入,第二个粗粒度的 256 类 K-Means 得到更细节的语义信息和发音变化作为补充。其中量化后的特征均由质心向量表示而非离散索引。
教师指导的双模式训练
kNN-VC [10] 利用了SSL特征特点,通过逐帧进行k最近邻匹配,用目标说话人的 SSL 特征匹配结果替换源 SSL 特征后重建波形,在少样本任意说话人语音转换上取得了显著效果。受其启发,如图2(b)所示,我们引入了一个教师模块在训练中模拟转换,称为转换模式。具体来说,我们收集了490个说话人,每人时长约为7分钟的语音数据,提取 XLS-R SSL 特征组成匹配池。在转换模式训练时,随机从匹配池中选择一个说话人的数据作为对象,与源数据进行帧级 kNN (k=8) 匹配替换构造出目标SSL特征。而在重建模式训练时,源SSL特征与目标SSL特征是相同的,来自于同一训练语句。这两种模式是以各0.5的概率随机激活的。从教师模块输出的目标特征中随机截取了 3 秒长度的片段作为说话人提示。
基于提示的Conformer转换器
转换器的作用是从说话人提示中捕获音色信息并与解耦得到的源内容信息融合获得转换结果。如图2(c)所示,其由6层 Conformer [13] 网络块和一个基于卷积的后处理网络组成。说话人提示特征会在时间维度上拼接在内容特征前面一同输入,而输出序列中开头3秒长度的特征被丢弃,剩余部分与目标SSL特征计算 MSE Loss。
多码本渐进式约束
如图2(c)所示,从底层到顶层是由内容信息转变为复杂的SSL特征,其中转换器的隐层输出的信息丰富度是递增的 [14]。我们在转换器的隐藏层中引入了多码本渐进约束,具体来说,我们预先在训练数据的SSL表征上进行了2048、4096、8192 三种不同粒度的K-Means聚类,并以此得到目标SSL特征的三种离散索引序列。由粗到细粒度的量化能够编码更多样的语音信息,因此分别用交叉熵损失来约束第2、4、6层的隐层输出。
实验
数据集和实验配置
我们使用了总共19,000小时的中英语音数据,包括开源英文数据集LibriTTS、Gigaspeech,以及内部收集的中文有声书数据集。我们使用预训练的 XLS-R 模型 [15] 从第六层提取1024维特征作为语音表征,所有的 K-Means 聚类都是在帧级语音表征上离线进行的。声码器采用 HiFiGAN V1 模型,输入语音表征,输出 24kHz 波形。
我们与两个代表性的零样本语音转换系统 LM-VC [9] 和 SEF-VC [16] 进行比较。LM-VC 采用包含三个LM的两段式框架。SEF-VC 通过交叉注意机制从参考语音中捕获音色信息,并以非自回归方式从 HuBERT 语义标记重建波形。
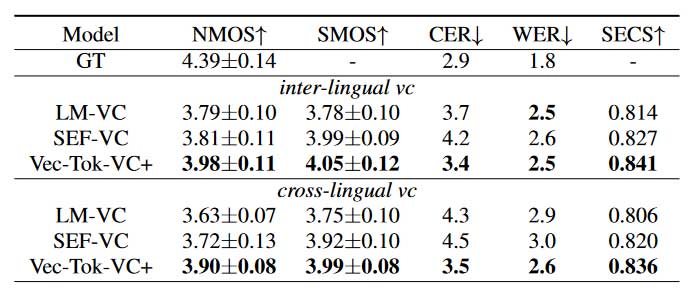
零样本语音转换结果
如表1所示,Vec-Tok-VC+ 相比对比的模型,在语种内零样本转换上取得了更好的自然度和可懂度,我们将此归因于残差 K-Means 聚类增强的解耦过程和渐进式损失函数的约束作用。Vec-Tok-VC+ 在主观和客观评估中都达到了最佳的说话人相似度,这表明转换器中的自注意机制更好地从3秒说话人提示中捕获和融合了音色信息。我们进行了跨语种零样本语音转换实验进一步证明模型的能力,尽管所有模型的跨语种实验结果都会出现性能下降,但 Vec-Tok-VC+ 仍然优于对比的模型。在实验过程中,我们发现 Vec-Tok-VC+ 对于带噪的源语音也表现出鲁棒的转换能力,我们在 Demo 页上展示了这一点。
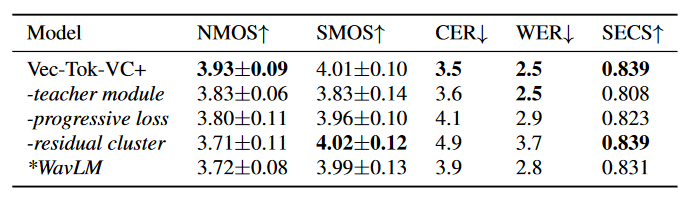
消融实验
为了与 Vec-Tok-VC 对比并验证我们提出的方法的重要性,我们进行了四组消融实验,分别去掉教师指导模块、渐进式损失约束、解耦过程的残差聚类以及使用 WavLM 替换 XLS-R。结果如表2所示,当去除教师模块时,训练期间只进行同一语句的重建过程,导致整体的性能均下降;去掉渐进式损失约束则带来了自然度和相似度的降低。此外,去除残差聚类尽管仍保持了较高的相似度,但自然度显著降低,这表明单级的 K-Means 解耦所捕获的语义内容或韵律细节不足。同样,XLS-R 的替换保持了相似度几乎不变但自然度和可懂度也显著下降,证明了 XLS-R 在多语种语音表征建模中的优势。
完整样例请参考 demo page.
参考文献
[1] S. H. Mohammadi and A. Kain, “An overview of voice conversion systems,” Speech Commun., vol. 88, pp. 65–82, 2017.
[2] D. Wu, Y. Chen, and H. Lee, “VQVC+: one-shot voice conversion by vector quantization and u-net architecture,” in Proc. INTERSPEECH. ISCA, 2020, pp. 4691–4695.
[3] K. Qian, Y. Zhang, S. Chang, X. Yang, and M. HasegawaJohnson, “Autovc: Zero-shot voice style transfer with only autoencoder loss,” in Proc. ICML, vol. 97. PMLR, 2019, pp. 52105219.
[4] J. Wang, J. Li, X. Zhao, Z. Wu, S. Kang, and H. Meng, “Adversarially learning disentangled speech representations for robust multi-factor voice conversion,” in Proc. INTERSPEECH. ISCA, 2021, pp. 846–850.
[5] D. Wang, L. Deng, Y. T. Yeung, X. Chen, X. Liu, and H. Meng, “VQMIVC: vector quantization and mutual information-based unsupervised speech representation disentanglement for one-shot voice conversion,” in Proc. INTERSPEECH. ISCA, 2021, pp. 1344–1348.
[6] K. Qian, Y. Zhang, S. Chang, M. Hasegawa-Johnson, and D. D. Cox, “Unsupervised speech decomposition via triple information bottleneck,” in Proc. ICML, vol. 119. PMLR, 2020, pp. 78367846.
[7] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust DNN embeddings for speaker recognition,” in Proc. ICASSP. IEEE, 2018, pp. 5329–5333.
[8] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y. Qian, Y. Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Largescale self-supervised pre-training for full stack speech processing,” IEEE J. Sel. Top. Signal Process., vol. 16, no. 6, pp. 15051518, 2022.
[9] Z. Wang, Y. Chen, L. Xie, Q. Tian, and Y. Wang, “LM-VC: zeroshot voice conversion via speech generation based on language models,” IEEE Signal Process. Lett., vol. 30, pp. 1157–1161, 2023.
[10] M. Baas, B. van Niekerk, and H. Kamper, “Voice Conversion With Just Nearest Neighbors,” in Proc. INTERSPEECH 2023, 2023, pp. 2053–2057.
[11] X. Zhu, Y. Lv, Y. Lei, T. Li, W. He, H. Zhou, H. Lu, and L. Xie, “Vec-tok speech: speech vectorization and tokenization for neural speech generation,” CoRR, vol. abs/2310.07246, 2023.
[12] N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 30, pp. 495–507, 2022.
[13] A. Gulati, J. Qin, C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu, and R. Pang, “Conformer: Convolution-augmented transformer for speech recognition,” in Proc. INTERSPEECH. ISCA, 2020, pp. 5036–5040.
[14] J. Lee, S. Lee, J. Kim, and S. Lee, “PVAE-TTS: adaptive text-tospeech via progressive style adaptation,” in Proc. ICASSP. IEEE, 2022, pp. 6312–6316.
[15] https://pytorch.org/audio/stable/generated/torchaudio.models.wav2vec2_xlsr_300m
[16] J. Li, Y. Guo, X. Chen, and K. Yu, “SEF-VC: speaker embedding free zero-shot voice conversion with cross attention,” CoRR, vol. abs/2312.08676, 2023.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
