
手势在人类交流中起着关键作用。最近的共语手势生成方法虽然能够生成与节拍对齐的动作,但在生成与话语语义对齐的手势方面仍然存在困难。相比于自然与音频信号对齐的节拍手势,语义连贯的手势需要对语言与人体动作之间复杂的互动进行建模,并可以通过关注特定词语来进行控制。因此,我们提出 了ConvoFusion,一种基于扩散的多模态手势合成方法,它不仅可以基于多模态语音输入生成手势,还可以在手势合成中实现可控性。我们的方法提出了两个引导目标,使用户能够调节不同条件模态(例如音频与文本)的影响,并选择在手势过程中需要强调的特定词语。我们的方法具有多功能性,可以训练生成独白手势,甚至是对话手势。为了进一步推进多方互动手势的研究,我们发布了 DnD Group Gesture 数据集,该数据集包含6小时的手势数据,展示了5个人之间的互动。
作者:Muhammad Hamza Mughal等
论文题目:ConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis
来源:CVPR 2024
论文链接:https://arxiv.org/abs/2403.17936
内容整理:王怡闻
引言
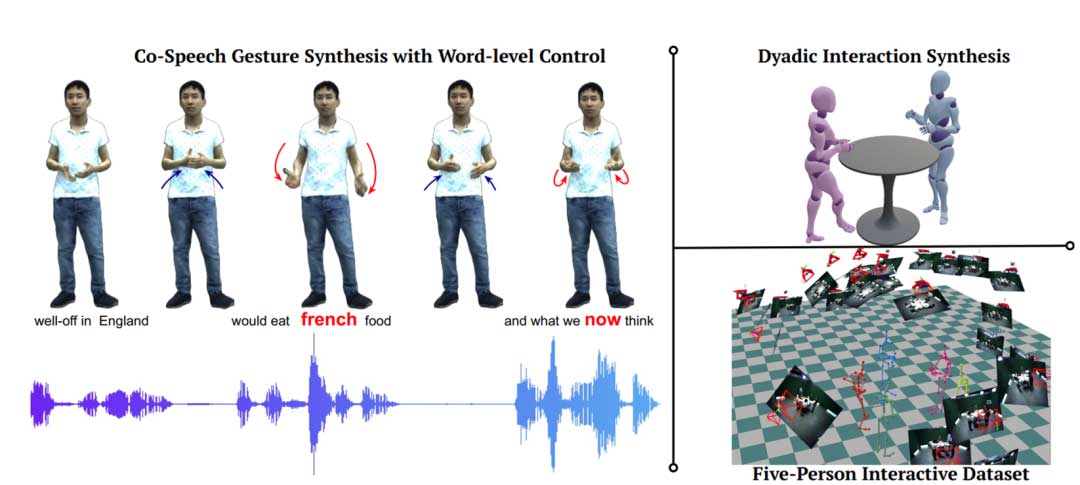
尽管大多数方法成功捕捉到了与语音节奏对齐的节拍手势,它们在手势生成中的语言控制方面仍然不足,因此难以生成对语句整体意义有贡献的精确语义手势。这可以归因于节拍手势的运动在时间上与语音信号良好对齐,并且一般对所有说话者和内容都遵循类似的空间模式,因此更容易通过学习技术进行建模。另一方面,语义连贯性与词语、其意义以及个人说话者之间有更复杂的时间交互。在这项工作中,我们提出了CONVOFUSION——一种新颖的可控手势合成方法,不仅可以生成共语手势,还可以生成反应(和被动)手势。我们设计的运动潜在空间具有时间感知功能,从而使我们能够学习运动和语音之间的时间关联,并能够进行连续的手势合成。
我们的模型支持多种输入(对话中的说话者的文本和音频)。为了实现模型的可控多模态推理,CONVOFUSION 还允许我们通过细粒度的文本引导增强与特定词语相关的微手势。拥有测试时的模态控制和词级文本引导,使我们能够对生成的动作进行粗粒度和细粒度的控制;这是现有手势合成工作中所缺少的特性。
我们框架的目标之一是对对话场景中表现出的手势进行建模。然而,大多数现有数据集仅包含独白内容,如 TED 和 SHOW 数据集。即使是记录在对话场景中的数据集,也仅为一个人提供注释。为了解决这个问题,我们引入了 DND GROUP GESTURE 数据集。该数据集包含五名参与者进行多场 DND 游戏——一种流行的角色扮演游戏的多次会话。数据集包括所有参与者的高质量全身动作捕捉、多通道音频记录和文本转录。通过大约6小时的捕捉,DND GROUP GESTURE 数据集使我们能够提出一种新的方法来生成双人互动场景中的手势。
方法
潜在空间设计
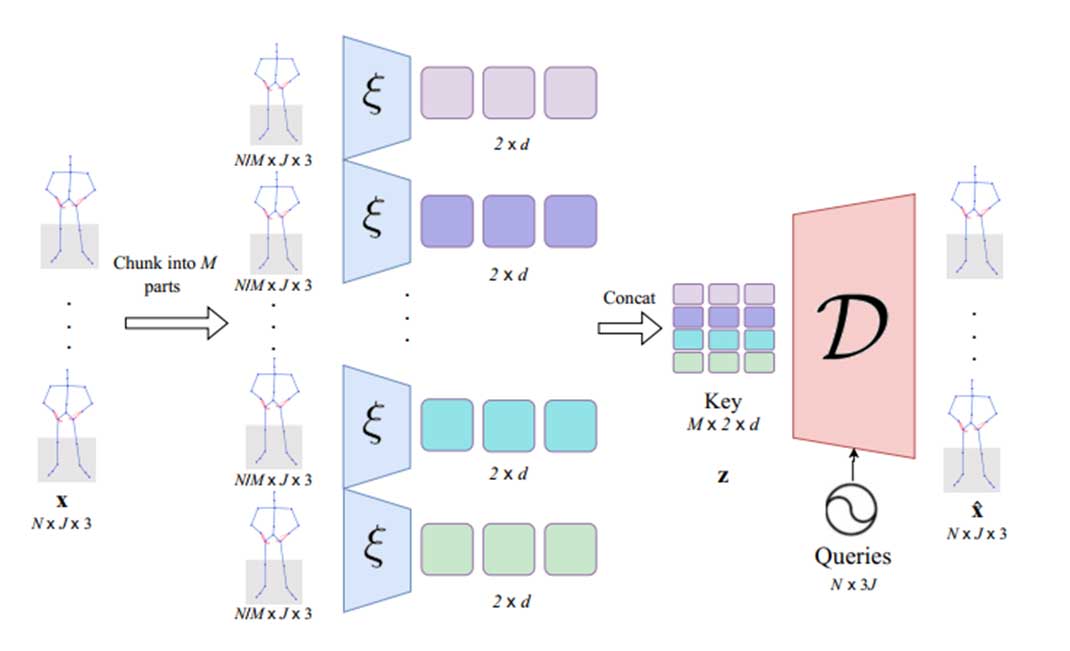
输入N帧的动作序列,我们首先将它们压缩至潜在空间,随后在潜在空间上进行扩散-去噪过程。基于经典的VAE架构,我们额外使用了分块编码的设计,因为:
- 单一向量难以捕捉长时间序列中的微妙时间依赖和变化
- 分块编码可以对生成的动作序列进行局部的微调或控制

多模态手势生成
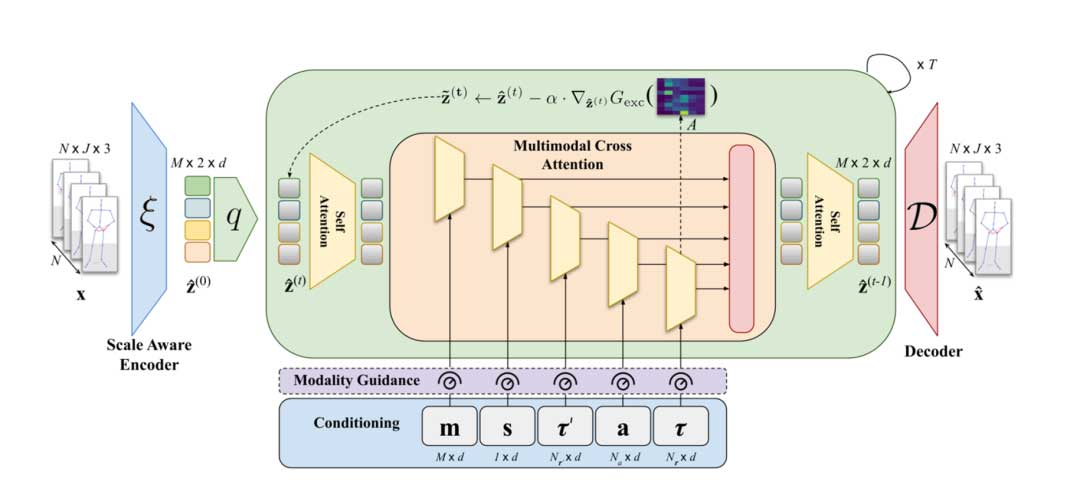
我们在两种情况下进行条件控制:
单人
单人设置指的是基于说话者自己的话语生成手势,通常发生在独白场景中。对此,我们将条件信号表示为 C={a,τ,s},a 指代音频,τ 指代文本,s 指代 speaker id。
双人
双人设置,即在对话场景中,生成的手势必须同时与第二个人的话语相关联。在这种情况下,我们有 C={a,τ,τ′,s,m} ,其中 τ′ 指代共同参与者的说话内容即文本。这里也可以选择他们的音频。m∈{0,1}^𝑀指示说话者是积极地以言语回应还是被动地通过比如笑或点头来回应
我们使用带有多头注意力机制的 Transformer 作为 Backbone ,每个模态有一个注意力头。
词-细粒度的控制(WEG)
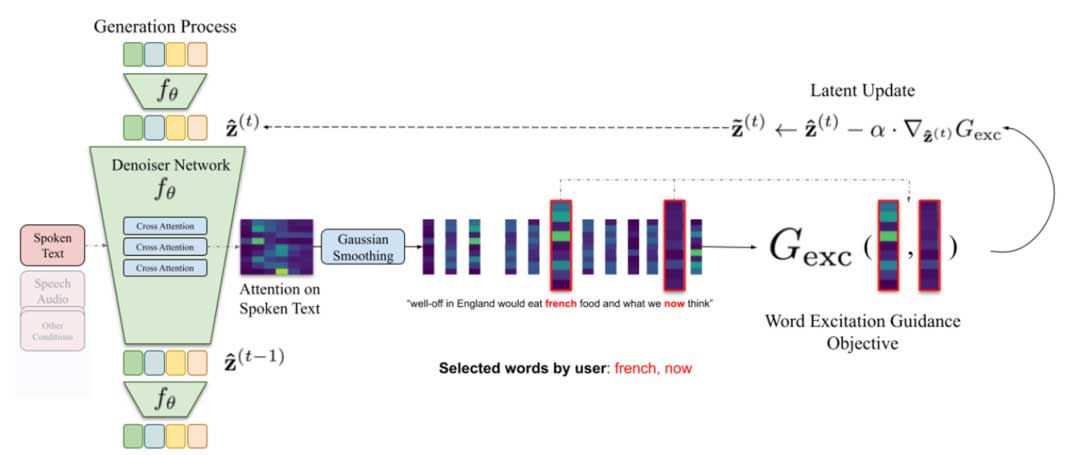
受图像生成方法的启发,我们提出了一种词级引导机制,允许我们在采样过程中基于用户定义的词集合精细控制手势生成。

其中,α 是词激发引导的引导比例,同时也作为潜在变量更新的步长。
实验
单人
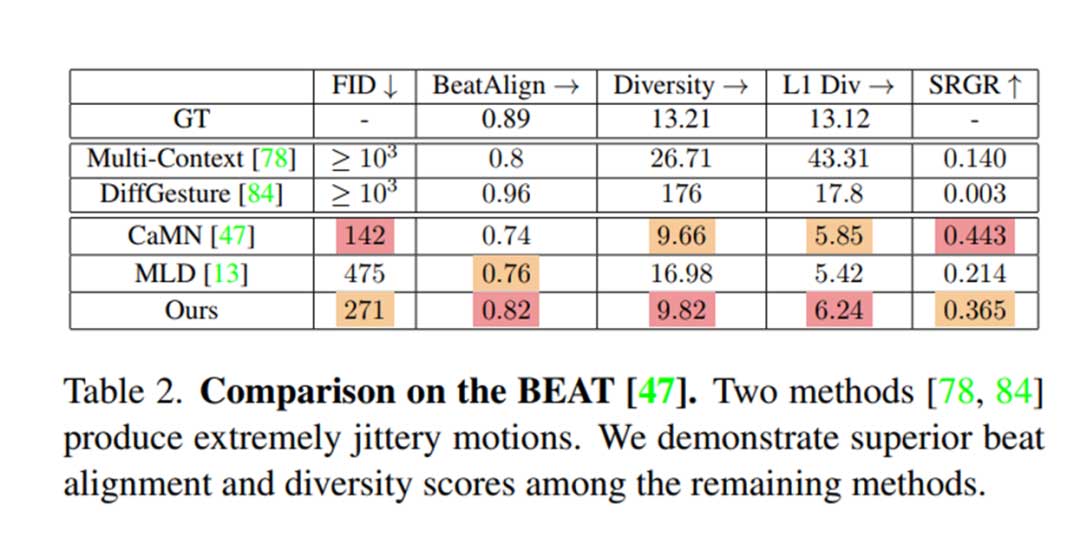
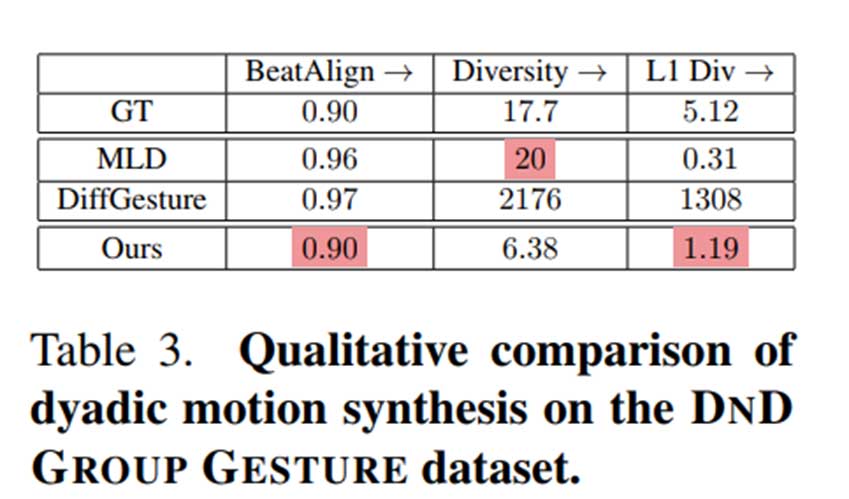
双人
消融实验
在VAE上的实验:
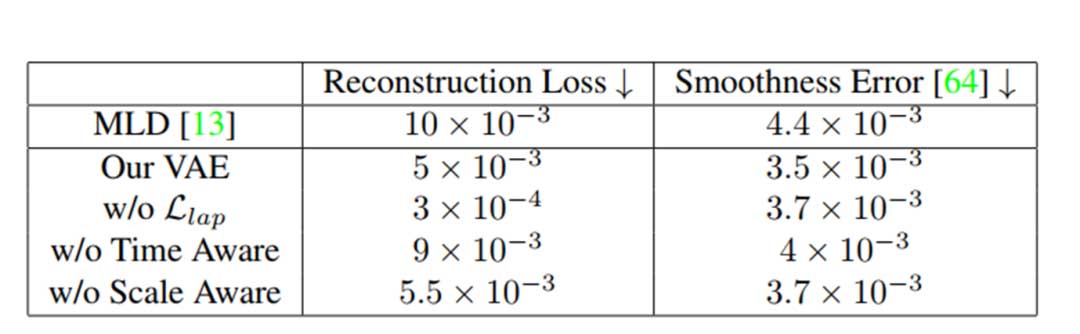
Laplace 正则化帮助模型维持在真实世界观测到的动作的自然速度变化,防止生成的动作看起来过于机械或不自然。
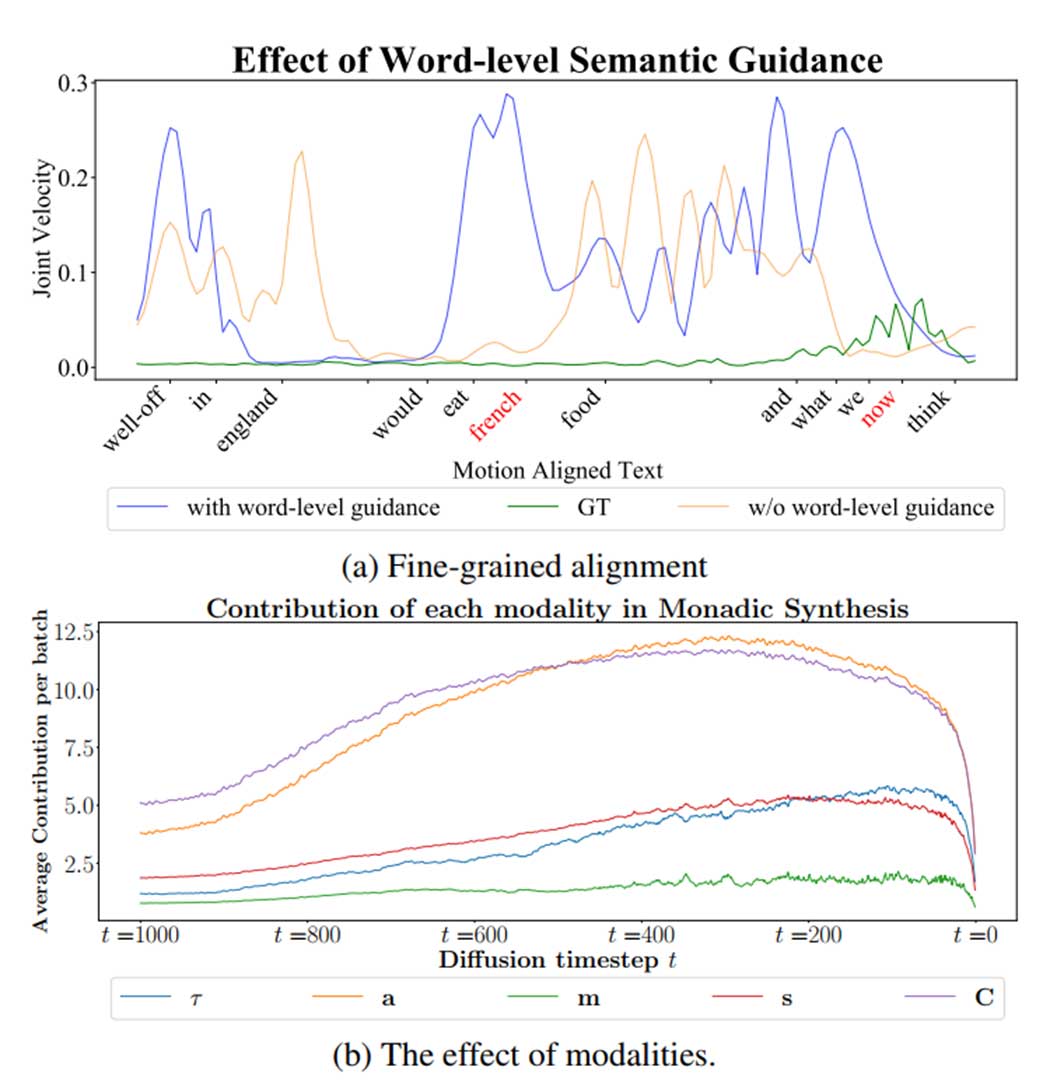
- 音频模态对最终生成有更大影响
- 在激发词出现时关节速度的显著增加(表现出更活跃的行为)
- 训练了一个手势类型分类器来识别节拍和语义手势。对于未使用WEG 的合成手势,我们观察到语义标签的召回率为0.34。然而,当使用WEG时,这个召回率增加到0.40,表明使用 WEG 增强了生成手势的语义一致性
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
