
本文将介绍并解释图像变形的两种算法:前向映射和反向映射。除了在理论层面上介绍这些算法之外,还将它们应用于实际图像,以查看每种算法的结果和能力。
为了完全理解本文中的所有内容,有必要熟悉2D变换矩阵,这在先前的文章中已经介绍和解释过。
https://medium.com/@JavierMtz5/2d-matrix-transformations-for-computer-vision-80b4a4f2120f
引言
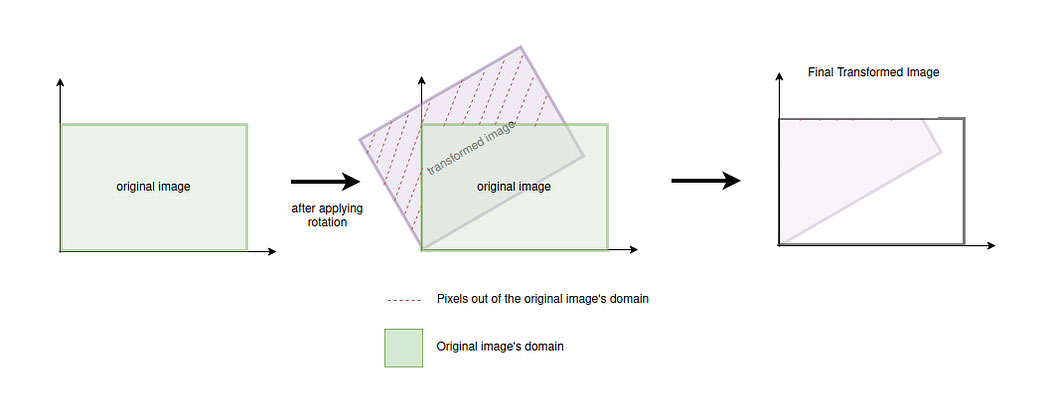
正如在先前的文章中所看到的,对图像应用变换的方法是迭代遍历图像的每个像素,并对每个像素进行单独的变换。然而,存在一些特定的用例,无法直接应用变换,因为例如,一些像素的新位置可能在图像域之外。另一个可能的问题是,新图像可能具有空白像素(白色条纹),因为在变换后很难将原始图像的所有像素映射到新图像的所有像素。
为了避免一些问题,本文将介绍的两种算法——前向映射和反向映射采用了不同的技术来正确地变换图像。
前向映射
前向映射过程包括在介绍和先前文章中讨论过的简单图像变换过程:迭代遍历图像的所有像素,并对每个像素单独应用相应的变换。然而,在转换后,转换像素的新位置超出图像域的情况(如下所示)必须予以考虑。
执行前向映射过程时,首先定义一个接受像素的原始坐标作为参数的函数。该函数将对原始像素坐标应用变换,并返回变换后像素的新坐标。以下代码示例显示了旋转变换的函数。
def apply_transformation(original_x: int, original_y: int) -> Tuple[int, int]:
# Define the rotation matrix
rotate_transformation = np.array([[np.cos(np.pi/4), -np.sin(np.pi/4), 0],
[np.sin(np.pi/4), np.cos(np.pi/4), 0],
[0, 0, 1]])
# Apply transformation after setting homogenous coordinate to 1 for the original vector.
new_coordinates = rotate_transformation @ np.array([original_x, original_y, 1]).T
# Round the new coordinates to the nearest pixel
return int(np.rint(new_coordinates[0])), int(np.rint(new_coordinates[1]))有了这个函数之后,只需迭代遍历图像的每个像素,应用变换并检查新像素坐标是否在原始图像的域内。如果新坐标在域内,则新图像的新坐标处的像素将采用原始图像中原始像素的值。如果坐标超出图像,则省略该像素。
def forward_mapping(original_image: np.ndarray) -> np.ndarray:
# Create the new image with same shape as the original one
new_image = np.zeros_like(original_image)
for original_y in range(original_image.shape[1]):
for original_x in range(original_image.shape[0]):
# Apply rotation on the original pixel's coordinates
new_x, new_y = apply_transformation(original_x, original_y)
# Check if new coordinates fall inside the image's domain
if 0 <= new_y < new_image.shape[1] and 0 <= new_x < new_image.shape[0]:
new_image[new_x, new_y, :] = original_image[original_x, original_y, :]
return new_image使用前向映射应用旋转变换的结果如下图所示,左侧为原始图像,右侧为变换后的图像。需要注意的是,对于此图像,坐标原点位于左上角,因此图像是绕该点逆时针旋转的。
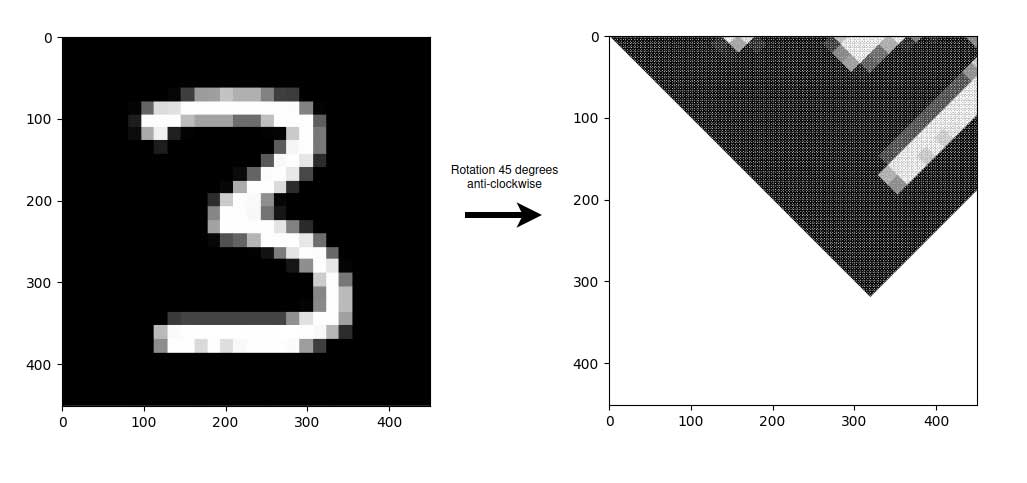
关于变换的结果,可以看到变换后的图像没有原始图像的全黑背景,而是有许多白色条纹。正如在引言中提到的那样,这是因为原始图像的像素并不总是映射到新图像的所有像素。由于新坐标是通过四舍五入到最近的像素来计算的,这导致许多中间像素永远不会接收值。在这种情况下,由于新图像的所有像素都初始化为空白,因此在变换期间未给定值的像素将保持为空白,导致变换后图像中的这些白色条纹。
此外,还应注意到另一个显着的问题:重叠。当原始图像的两个像素变换到新图像的同一像素时,就会出现此问题。对于本文中使用的代码,如果原始图像的两个像素映射到新图像的同一像素,则新像素将取得已经变换的最后一个原始像素的值,覆盖已经设置的第一个像素的值。
反向映射
反向映射算法的提出是为了消除由于变换而在图像中生成的白色条纹以及可能的重叠。正如前面所述,这些条纹出现的原因是在前向映射过程中计算新坐标时,由于四舍五入,变换后的图像的不是所有像素都获得了值,而重叠发生在原始图像的两个或更多像素映射到新图像的同一像素的情况下。
这个算法的逻辑很简单:与其将原始图像的每个像素转换为新图像中的新坐标(前向映射),这次是将新图像的所有像素反向转换为原始图像中的像素(反向映射)。这样,新图像中就不会有任何一个像素没有值,因为它们都将获得原始图像中单个像素的值,从而解决了这两个问题。
幸运的是,使用变换矩阵对像素坐标应用的变换可以通过使用逆变换矩阵进行相同的过程来撤销。变换矩阵的这一属性及其证明可见于下图。
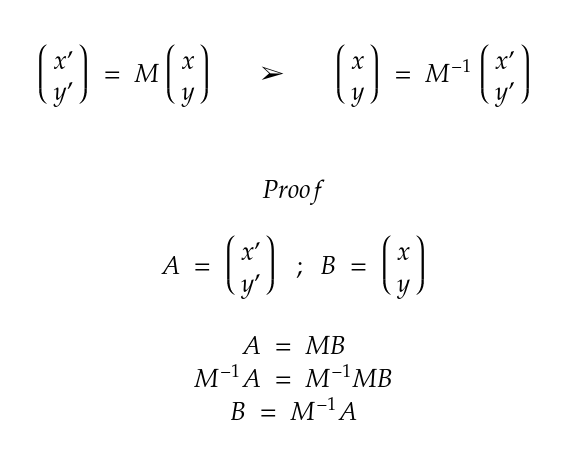
考虑到这一属性,算法的实现包括迭代遍历新图像的每个像素,并对每个像素的坐标应用逆变换,以确定它们必须取值的原始图像中的像素。
def apply_inverse_transformation(new_x: int, new_y: int) -> Tuple[int, int]:
# Define the inverse rotation matrix
rotate_transformation = np.array([[np.cos(np.pi/4), -np.sin(np.pi/4), 0],
[np.sin(np.pi/4), np.cos(np.pi/4), 0],
[0, 0, 1]])
inverse_rotate_transformation = np.linalg.inv(rotate_transformation)
# Apply transformation after setting homogenous coordinate to 1 for the position vector.
original_coordinates = inverse_rotate_transformation @ np.array([new_x, new_y, 1]).T
# Round the original coordinates to the nearest pixel
return int(np.rint(original_coordinates[0])), int(np.rint(original_coordinates[1]))注意,apply_inverse_transformation() 函数的输入是新图像中的坐标,并返回原始图像中的坐标,与前向映射的情况不同,前者的输入是原始坐标,返回的是新坐标。
def backward_mapping(original_image: np.ndarray) -> np.ndarray:
# Create the new image with same shape as the original one
new_image = np.zeros_like(original_image)
for new_y in range(new_image.shape[1]):
for new_x in range(new_image.shape[0]):
# Apply inverse rotation on the new pixel's coordinates
original_x, original_y = apply_inverse_transformation(new_x, new_y)
# Check if original coordinates fall inside the image's domain
if 0 <= original_y < original_image.shape[1] and 0 <= original_x < original_image.shape[0]:
new_image[new_x, new_y, :] = original_image[original_x, original_y, :]
return new_image使用反向映射应用旋转变换的结果如下图所示,左侧为原始图像,右侧为变换后的图像。如前所述,图像围绕坐标原点(位于左上角)逆时针旋转。
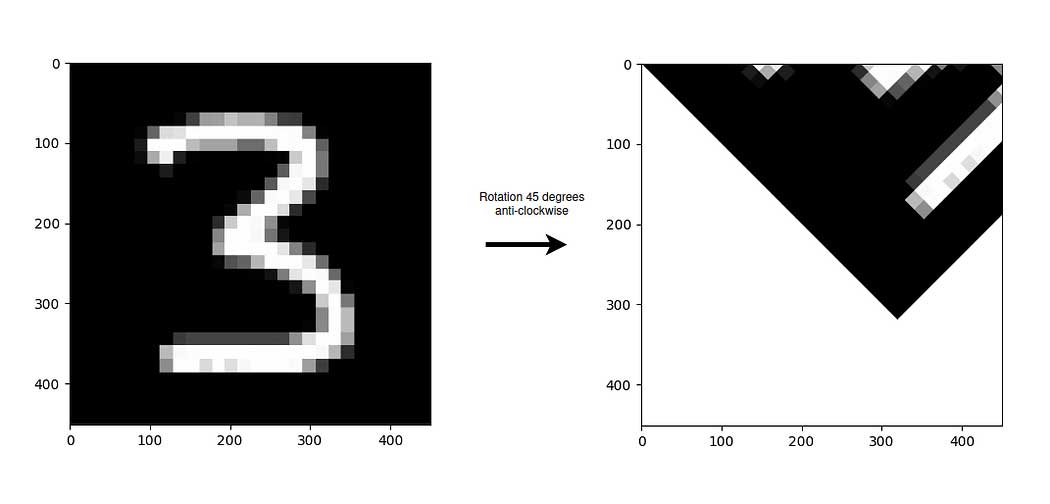
在图像中,可以看到在应用反向映射时,所有那些在应用前向映射时出现的白色条纹都消失了。事实上,可以看到变换后图像的质量相当不错(必须考虑到原始图像的质量不是很好),因此我们可以认为反向映射算法在变换期间出现白色条纹的情况下比前向映射算法要好得多。
结论
前向映射是一种易于实现且易于理解的算法,因为它涉及将原始图像的每个像素直接变换到新图像。然而,该算法存在重叠问题和许多像素缺少值的问题,这显著降低了变换图像的质量。反向映射算法的实现与前向映射一样直观,但结果更好,解决了这两个问题,因为它为新图像的所有像素提供了单一值。
至于算法的执行时间,两者的复杂性相同,因此通常使用反向映射算法总是一个更好的选择,因为它的结果更好。在理想情况下,负责在每个像素上应用单独变换的函数(在本文中称为apply_transformation()和apply_inverse_transformation())将不构建变换矩阵,而是将其作为参数接收。这将节省前向映射算法构建变换矩阵所需的执行时间,以及反向映射算法构建矩阵并将其反转的时间。
总之,与前向映射相比,反向映射算法取得了非常好的结果,两者几乎具有相同的执行时间。然而,需要注意的是,对于高分辨率图像,这两种算法都需要很长时间来进行变换,尽管它们仍然非常有用,可以为构建其他更强大的变换算法奠定基础。
数据
文章中使用的图像来自MNIST数据集[1]。该数据集在Creative Commons Attribution-Share Alike 3.0许可下提供。
参考文献
[1] http://yann.lecun.com/exdb/mnist/
作者:磐怼怼,微信「 woshicver」
来源:深度学习与计算机视觉
原文:https://mp.weixin.qq.com/s/_Y0pPpgmmeFTYzxCYAieIQ
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
