
在Kafka的内部,其实关于队列这个名词,大家应该都不陌生。当消息被存储到不同的Partition文件中,Kafka集群架构中,Partition文件会被分散到各个Broker节点进行存储。每个Partition文件其实底层是多个Segment文件的组合构成的。具体的存储结构如下图所示:
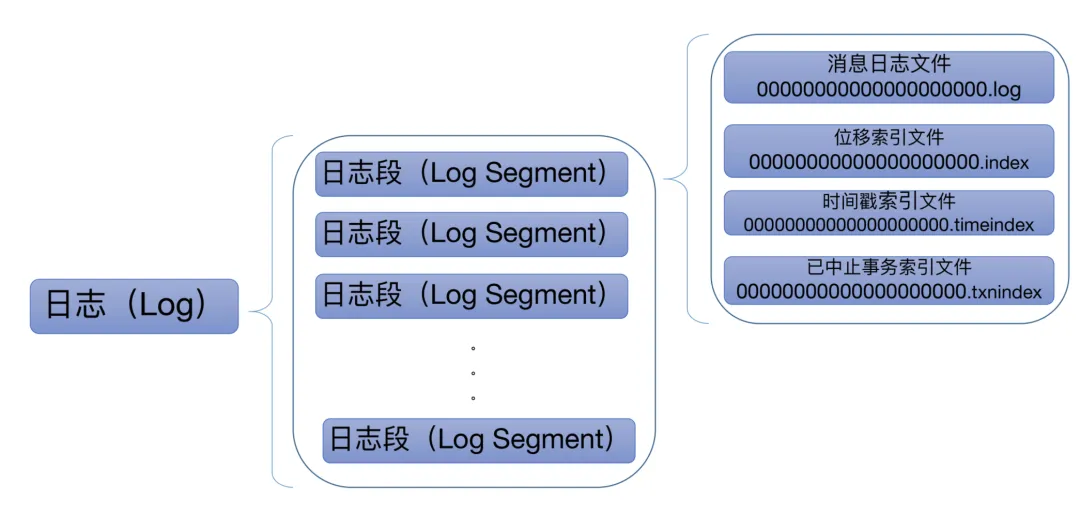
可以看到,同一个topic下的数据都会被存储到公共的文件块中。那么如果我们希望实现推送的数据只往一条队列存储,消费的时候固定只拉该队列的数据,这类效果可以如何实现呢?
Kafka的队列选择推送
为了方便代码统一,这里我使用的是Spring-Kafka-2.3.2版本这个依赖包的代码进行案例讲解:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.2.RELEASE</version>
</dependency>
其实在Kafka-Client Java版本实现的源码里面,会有一个叫做org.apache.kafka.clients.producer.Partitioner的接口定义,该接口可以用于设置生产者推送消息时候指定对应的队列序号。
为什么该类可以指定队列?其实要想真正理解它的作用,我们需要部署一个Kafka的Producer案例,然后根据源代码Debug查阅其中的链路,下边是我自己Debug时候看到的链路图:
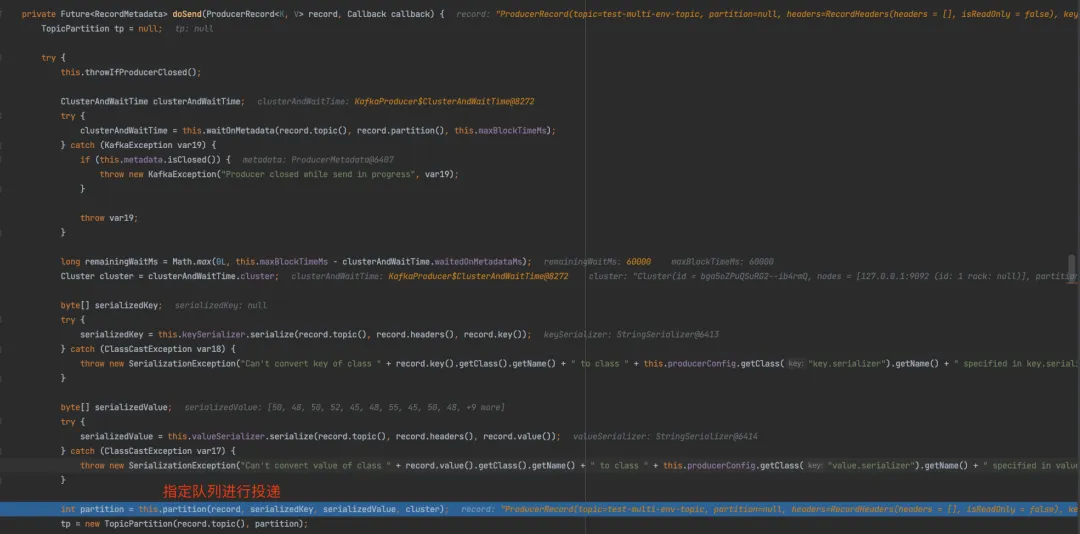
这里可以推断出,Kafka的客户端会把队列id塞入到一个对象中,最后通过Netty发送给到Broker的服务端,再在Broker的服务端进行落库存储。
到这里,整体的链路相信大家应该理解了。因此如果你需要自定义投递队列,只需要自己造一个实现Partitioner接口的类,然后将它放入到Producer的配置中即可。
下边是我实现的自定义队列路由类,这里我自定义了下不同队列的含义,例如队列0专门用于存储灰度环境的数据。(基于队列实现灰度隔离的思路,可以参考以下Demo)
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
import java.util.concurrent.ThreadLocalRandom;
/**
* @author idea
* @create 2024/7/19
* @description 自定义分区策略
*/
public class CustomPartitioner implements Partitioner {
private boolean isGrey = true;
private Integer defaultGreyQueueNum = 0;
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
int greyPartition = defaultGreyQueueNum;
//默认分区是0号队列或者以5为结尾的队列
if (isGrey) {
return greyPartition;
}
Integer totalPartitionCount = cluster.partitionCountForTopic(topic);
//非灰度的流量走随机
int partitionNumber = ThreadLocalRandom.current().nextInt(1,totalPartitionCount);
return partitionNumber;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
记得要配置相关策略到Config对象中,参考代码如下:
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
/**
* @author idea
* @create 2024/7/20
* @description
*/
@Configuration
public class KafkaProducerConfig {
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
}
@Bean
public ProducerFactory<String, String> producerFactory() {
ProducerFactory producerFactory = new DefaultKafkaProducerFactory(producerConfigs());
return producerFactory;
}
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//自定义分区策略,灰度环境投递到0号队列中
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
return props;
}
}
如何实现指定队列的数据拉取?
其实如果是指定队列的数据消费,这块并不是很复杂。可以简单实用Consumer的poll方法去指定拉哪些队列以及拉取的数据条数,例如下边这种方式:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class SpecificPartitionConsumer {
public static void main(String[] args) {
// Kafka broker地址
String bootstrapServers = "localhost:9092";
// 要消费的主题
String topic = "your-topic-name";
// 指定分区号
int partitionNumber = 0;// 根据需要更改
// 消费者组ID
String groupId = "your-group-id";
// 配置消费者属性
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServers);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
// 实例化消费者
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
// 创建分区列表
TopicPartition partition = new TopicPartition(topic,partitionNumber);
consumer.assign(Collections.singletonList(partition));
// 消费指定分区的消息
try {
while (true) {
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> record :records) {
System.out.printf("Consumed message from partition %d:offset = %d,key = %s,value = %s%n",
record.partition(),record.offset(),record.key(),record.value());
}
}
} finally {
consumer.close();
}
}
}这种方式虽然很简单实现,灵活度也很高,但是会需要修改原先的消费端代码,所以如果你不希望修改原先的消费逻辑,可以尝试去造一个继承了AbstractPartitionAssignor父类的对象。
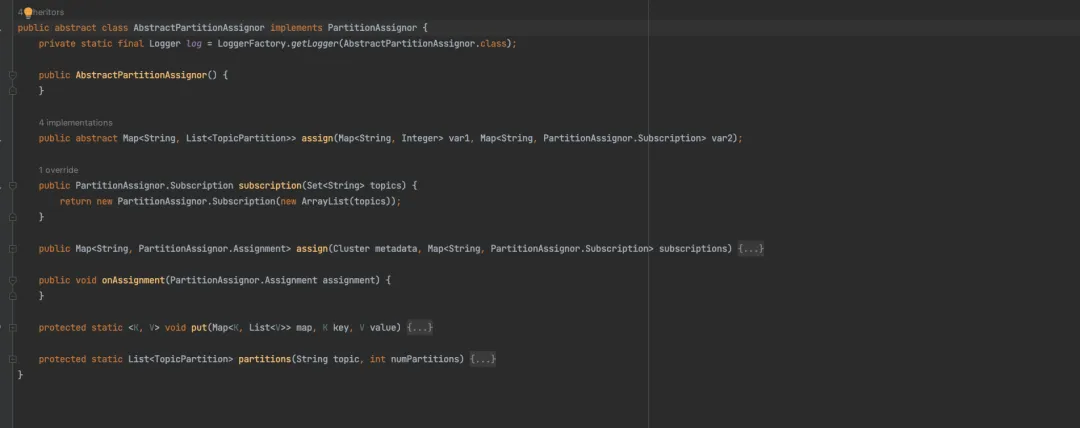
其实通过查阅源代码可以看到AbstractPartitionAssignor这个类是实现了Kafka的PartitionAssignor接口,这个接口是用于指定消费者在拉数据的时候选择哪条队列。
这里我稍微解释下AbstractPartitionAssignor这个父类对象的各个函数的作用:
- assign()是子类实现的完成Partition分配的抽象方法。
- onAssignment()方法时在每个消费者受到Leader分配结果时的回调函数。
源代码分析:
public abstract class AbstractPartitionAssignor implements PartitionAssignor {
public Map<String, Assignment> assign(Cluster metadata, Map<String, Subscription> subscriptions) {
Set<String> allSubscribedTopics = new HashSet<>();
Map<String, List<String>> topicSubscriptions = new HashMap<>();
//解析subscriptions集合,去除userData信息
for (Map.Entry<String, Subscription> subscriptionEntry : subscriptions.entrySet()) {
List<String> topics = subscriptionEntry.getValue().topics();
allSubscribedTopics.addAll(topics);
topicSubscriptions.put(subscriptionEntry.getKey(), topics);
}
//统计每个Topic分区个数
Map<String, Integer> partitionsPerTopic = new HashMap<>();
for (String topic : allSubscribedTopics) {
Integer numPartitions = metadata.partitionCountForTopic(topic);
if (numPartitions != null && numPartitions > 0)
partitionsPerTopic.put(topic, numPartitions);
else
log.debug("Skipping assignment for topic {} since no metadata is available", topic);
}
//把分配分区具体逻辑委托给了assign()重载,由子类实现
Map<String, List<TopicPartition>> rawAssignments = assign(partitionsPerTopic, topicSubscriptions);
// 整理分区结果
Map<String, Assignment> assignments = new HashMap<>();
for (Map.Entry<String, List<TopicPartition>> assignmentEntry : rawAssignments.entrySet())
assignments.put(assignmentEntry.getKey(), new Assignment(assignmentEntry.getValue()));
return assignments;
}
}如果你希望不对原来的消费逻辑代码做调整,也能实现统一的指定队列消费的效果,可以试试下边这段代码:
import org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor;
import org.apache.kafka.common.TopicPartition;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ThreadLocalRandom;
/**
* @author erichlin
* @create 2024/7/19 14:13
* @description
*/
public class GreyConsumerAssignment extends AbstractPartitionAssignor {
private String GREY = "grey";
private Integer defaultGreyQueueNum = 0;
public GreyConsumerAssignment() {
}
//注意这个assign方法的回调是在当有新的消费者加入到消费组的时候才会触发,因此在subscriptions里面获取的consumerId是包含了不同进程的consumer实例,需留意
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic, Map<String, Subscription> subscriptions) {
//灰度环境,只消费队列0的数据即可,因此部署多个消费者会有资源浪费
Map<String, List<TopicPartition>> assignment = new HashMap<>();
//解析出每个消费者
for (String consumerId : subscriptions.keySet()) {
assignment.put(consumerId, new ArrayList<>());
}
// 获取所有的消费者ID
List<String> consumers = new ArrayList<>(subscriptions.keySet());
System.out.println("consumers is :" + consumers);
for (Map.Entry<String, Integer> entry : partitionsPerTopic.entrySet()) {
String topic = entry.getKey();
//灰度队列是0
TopicPartition partition = new TopicPartition(topic, defaultGreyQueueNum);
// 随机选中一个消费者 占有灰度的专属队列即可
String consumer = consumers.get(ThreadLocalRandom.current().nextInt(0, consumers.size()));
assignment.get(consumer).add(partition);
}
return assignment;
}
@Override
public String name() {
return GREY;
}
}
这段代码内部我是模拟了下灰度环境的数据队列分配,例如说灰度环境中,kafka统一发送到各个topic的0号队列,消费也只消费0号队列。
最后不要忘记将该类加入到配置中去:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
/**
* @author idea
* @create 2024/7/20
* @description
*/
@Configuration
public class KafkaConsumerConfig {
@Value("${kafka.consumer.servers}")
private String servers;
@Value("${kafka.consumer.enable.auto.commit}")
private boolean enableAutoCommit;
@Value("${kafka.consumer.session.timeout}")
private String sessionTimeout;
@Value("${kafka.consumer.auto.commit.interval}")
private String autoCommitInterval;
@Value("${kafka.consumer.group.id}")
private String groupId;
@Value("${kafka.consumer.auto.offset.reset}")
private String autoOffsetReset;
@Value("${kafka.consumer.concurrency}")
private int concurrency;
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(concurrency);
factory.getContainerProperties().setPollTimeout(1500);
return factory;
}
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
propsMap.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, Arrays.asList(GreyConsumerAssignment.class));
return propsMap;
}
}作者:Danny idea
来源:Idea的技术分享
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
