
文章讨论了“视频编码的未来”这一话题,包括但不限于未来 5 年内的新兴领域、深度学习编码的趋势和作用、视觉质量评价的影响、学术界扮演的角色、对学生的建议等。
作者:Nam Ling, C.-C. Jay Kuo, Gary J. Sullivan, Dong Xu, Shan Liu, Hsueh-Ming Hang, Wen-Hsiao Peng, Jiaying Liu
来源:APSIPA TSIP 2022
论文题目:The Future of Video Coding
内容整理:朱辰
简介
[Nam] 近年来,视频编码技术和系统的研发取得了重大进展。随着 2020 年 7 月通用视频编码(Versatile Video Coding,VVC)标准的定稿,专家们开始遐想比 VVC/H.266 具有更高编码效率的下一个标准是什么样的。另一方面,近年来,深度学习工具受到了广泛关注,它们被应用于辅助传统视频编码,替代传统混合编码模型。然而,这些工具具有非常高的计算复杂度和功耗,使得它们在目前的设备条件下并不实用。因而,深度工具的轻量化是一个重要的研究方向。在视觉质量方面,已经有许多超出传统质量指标(如峰值信噪比 PSNR,多尺度结构相似性 MS-SSIM)的模型,那么,是否存在一个普遍接受的质量模型/指标?最后,许多人想知道学术界在视频编码领域中扮演什么样的角色,以及我们对有兴趣从事视频编码研究的学生有什么建议。
2021 年,APSIPA 召集了专家进行辩论并讨论“视频编码的未来”。我们认为这一主题可以引起广泛的兴趣,因此就讨论内容编写了这篇文章,总结了专家的意见。该讨论主要基于五个问题:(1)你认为未来 5 年视频编码领域的热门新兴领域是什么?(2)深度编码会成为视频编码的主要趋势吗?是或不是?为什么?(3)视觉质量评价是学术界的一个热门研究课题。这项工作会对视频编码标准化产生真正的影响吗?(4)学术界在开发新一代视频编码技术(或标准)方面是否有作用?(5)对于想从事视频编码研究的学生,有什么建议?
热门新兴的视频编码领域
向专家提出的第一个问题是“你认为的视频编码未来 5 年内的新兴热点是什么?”
新兴技术和应用
两路方案
[Gary] 除了研究传统编码架构,专家们正在研究使用神经网络的压缩方案。沉浸式视频比如三/六自由度视频压缩也是一个很大的领域。根据场景中的位置快速流式传输 “tile” 区域具有挑战性。不过即使是经典风格的普通编码技术也仍在进步。JVET 的当前方案比 2020 年 7 月的 VVC 标准性能提升了约 13-14%。然而,复杂度仍然是一个挑战。编码的应用空间也在增长,从广播到流媒体再到移动通信,8K 视频现在已经成为消费者应用,HDR 和高帧率视频也逐渐被应用。
新兴应用的动机
[Shan] 新技术的出现通常受到新兴应用的推动。例如,屏幕内容编码工具被用于涉及计算机生成内容的应用,如屏幕共享和视频会议。在新冠肺炎大流行期间,视频会议已成为我们日常生活中必不可少的一部分,并帮助许多人进行远程学习和工作。如今,几乎所有广泛使用的视频通信产品和应用都采用了屏幕内容工具。展望未来,我们预计体视频、虚拟现实、云游戏和低功耗边缘计算将有很高的需求。最近引起关注的另一个新兴领域是面向机器的视频编码。机器视觉任务(如目标检测、分割和跟踪)已被用于许多应用,包括智能交通和智能城市等。机器“观看”的视频量正在迅速增加,因此,压缩面向机器视觉任务的视频变得重要。
深度学习方法
[Wen-Hsiao] 目前有三个与深度学习方法相关的新兴领域:(1)深度学习(DL)辅助压缩——通过增强传统编解码器而不改变编解码器;(2)基于深度学习的压缩(端到端压缩)–使用神经网络作为压缩系统的主干;(3)混合系统——通过将基于 DL 的工具或增强层合并入传统编解码器。
DL 辅助压缩
[Wen-Hsiao] 在 DL 辅助方法中,神经网络可用于对输入视频进行预处理,以在不改变原有框架的情况下调整传统编解码器。例如,可以对输入视频进行预处理,使得解码视频有更好的 MS-SSIM 结果,而不是传统的面向 PSNR/MSE 的压缩(见图1a)。预处理也可以使解码视频适合于视觉任务,例如机器视频编码。另一种方法是在预处理和/或后处理中使用神经网络。在预处理步骤中,神经网络在输入图像中嵌入有用信息,这些信息可以在后处理步骤中从解码图像中提取,以更好地实现质量增强、码率节省或使解码视频适应视觉任务的目标(见图1b)。
我们还可以将强化学习应用于编码器控制任务。码率控制就是一个例子。我们有一个基于神经网络的代理,它与传统的编解码器交互,学习如何控制它(见图1c)。[1]提供了一个机器视频编码的示例,通过将相同的思想应用于训练优化机器视觉任务比特分配的代理。另一个领域是将轻量级神经网络应用于快速模式决策等任务。
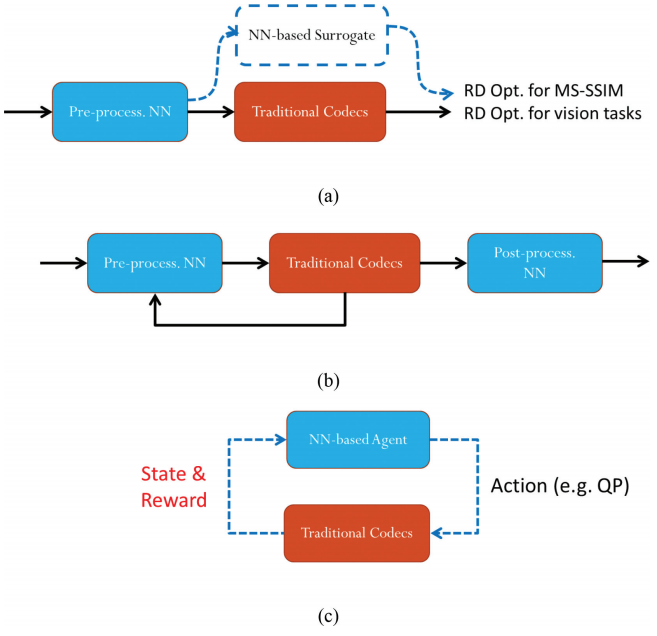
基于 DL 的端到端压缩
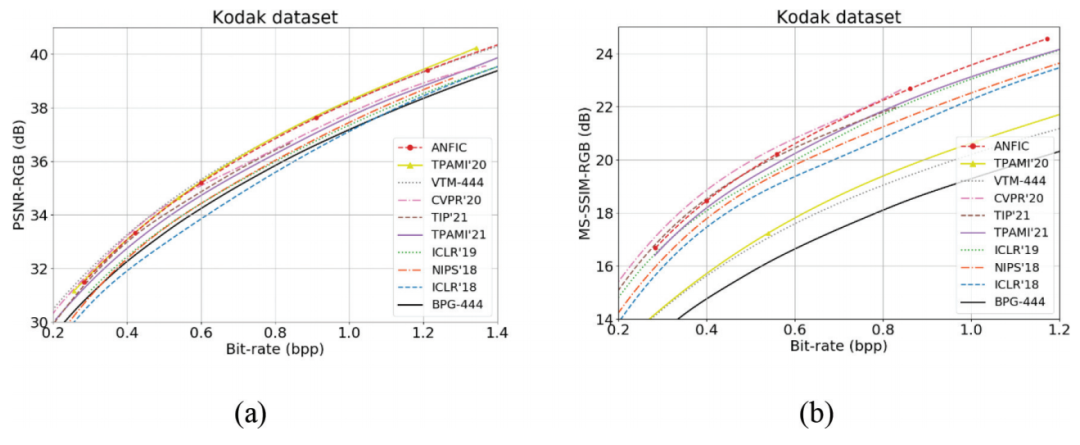
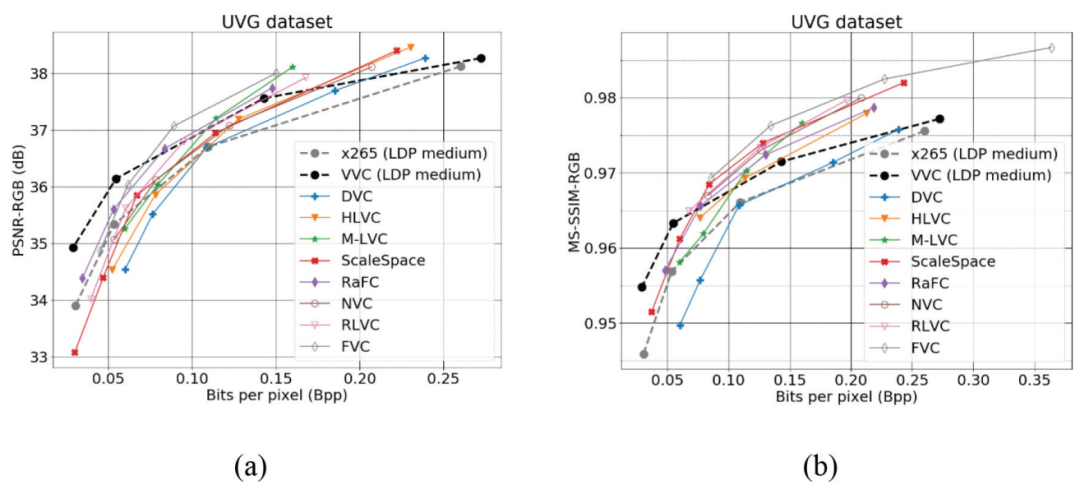
[Wen-Hsiao] 近年来,端到端学习的编解码器正在迅速发展。就 PSNR 而言,最先进的端到端图像编码器的性能与 VVC Intra 相当(见图2a);在图片组(GOP)大小为 12 的 Low-delay P 测试条件下,端到端视频编码器实现了比 HEVC 更好的 PSNR,并在高比特率下接近 VVC 的性能(见图3a)。就 MS-SSIM 而言,端到端图像编码器显示出比 VVC Intra 高得多的 MS-SSIM(见图3b);类似地,大多数端到端视频编码器在 Low-delay P 条件下(GOP=12)实现了比 HEVC 更好的 MS-SSIM,并且在高比特率下也比 VVC 更好。
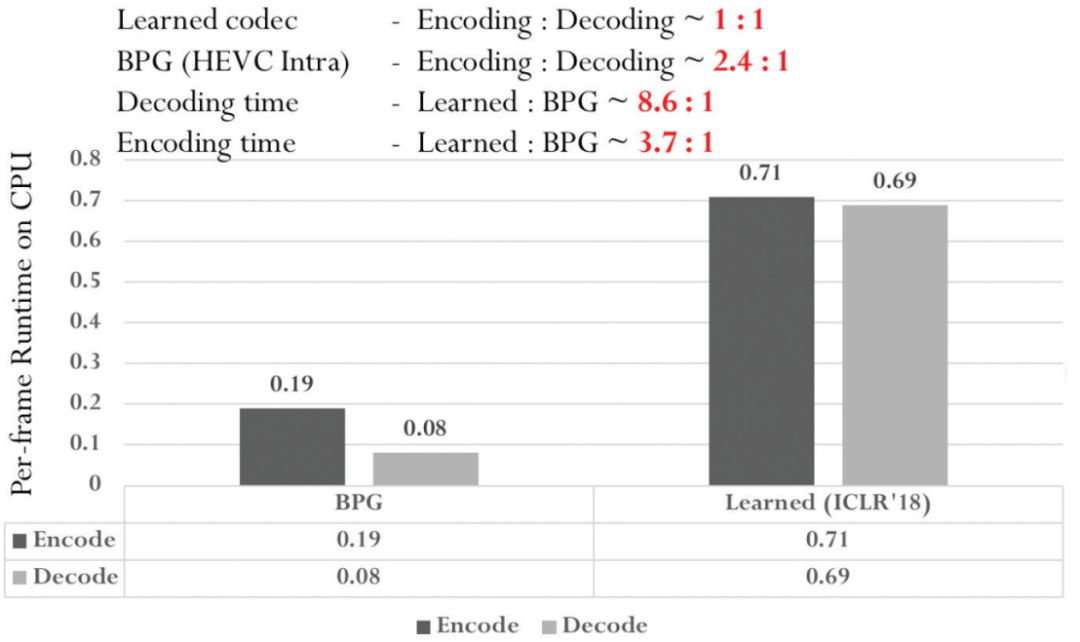
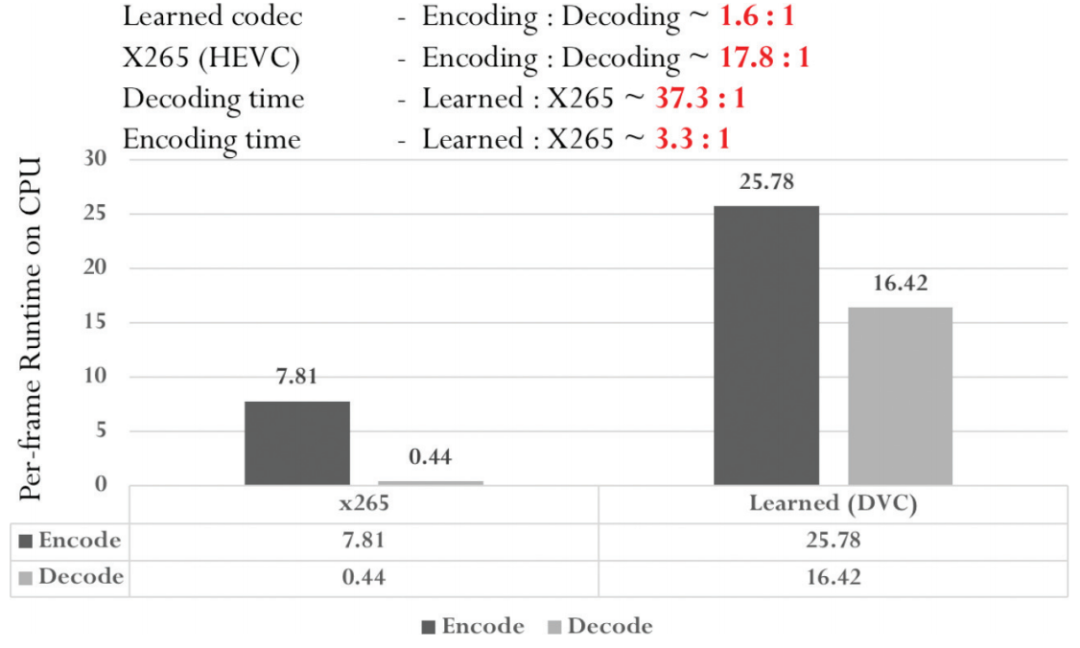
对于图像编码的运行时间,图 4 比较了基于 HEVC 的 BPG 编码器和端到端编码器[2]之间的编解码时间。对于端到端编解码器,编码和解码时间大致相同,这与编解码器的对称架构有关。对于 BPG,可以看到,传统编解码器需要更多时间进行编码,这源于编码器采用的率失真优化(RDO)过程。对于解码时间,端到端编解码器大约是传统 BPG 的 8.6 倍。对于视频编码,图 5 比较了 x265(HEVC编码器)和端到端编解码器 DVC[3]之间的编解码时间。对于端到端编解码器,由于光流估计网络,编码时间是解码时间的1.6倍。相比之下,x265 的编码时间显著高于解码时间(18×)。原因在于传统编码器的 RDO 过程根据每个视频帧的特性调整编码模式。显然,端到端编解码器没有达到与传统编解码器相同的编解码复杂度水平,尤其是解码,未来仍有进一步改进的空间。
未解决问题
[Wen-Hsiao] 对于学习类编码器,仍有几个有待解决的问题:(a) 复杂度太高。(b) 多码率编码。目前,大多数方案仍然使用分离的模型来实现不同的比特率。(c) 端到端的码率控制是一个探索不足的领域。关于研究很少。(d) 编码器优化:如何使编码过程适应每一个输入视频帧或图像需要更多的研究。(e) 泛化:特别是如何使端到端编解码器更少地依赖于训练数据。(f) 无损或几乎无损编码。大多数端到端编解码器无法实现该目标。
端到端编码器的视觉质量
[Hsueh-Ming] 近年来,深度神经网络(DNN)在模式提取、存储和检索方面表现出优异的性能,特别是当 DNN 模型用适当的训练数据集训练时。这些特性(模式提取和检索)对于端到端编解码器压缩和重建图像的成功至关重要。学习类编解码器通常具有良好的主观图像/视频质量。例如,在 2018 年的一篇论文[4]中可以看到(见图6),端到端编码器产生的重建图片显然具有更好的视觉质量;不过,端到端编码器的 PSNR 性能不高。
对于热点研究领域,我的观察如下。(1)在过去的 4-5 年中,有许多关于帧内图像编码的论文和工作。到目前为止,领先的帧内学习编解码器可以实现比具有可比 PSNR 值的最佳标准编解码器(VVC)更好的视觉质量(MS-SSIM)。(2)然而,帧间视频编码要复杂得多,端到端视频编解码器的开发仅在大约 3 年前才开始,并且在帧间编码方面仍有许多工作要做,特别是在视频预测器或内插器方面。因此,端到端视频编码系统有很大的改进空间。(3)需要一种广泛认可的用于端到端编解码器的视觉质量评价方法。

深度视频编码的发展趋势
第二个问题是“深度编码会成为视频编码的主要趋势吗?是或不是?为什么?”
总体趋势和问题
[Dong] 深度学习将在未来的视频编码标准中发挥重要作用,无论是 DL 辅助,基于 DL 的端到端,还是其他方式。谷歌和纽约大学发表了三篇关于基于深度学习的图像压缩的重要著作[5-7]。目前基于学习的编解码器在某些情况下已经取得了与 VVC 相当甚至更好的结果。
[Jiaying] 基于学习的编解码器面临的挑战之一是由于网络深度的复杂性。根据应用程序的不同,我们可能不需要很深的网络。基于在深度学习环路滤波器中的观察,我们实现了 10% 的 BD-rate 改进。我们还看到了比 VVC 更快的端到端编解码器,其编码器和解码器只需四个卷积层即可实现,这是轻量级的。我们还看到了一个从数据中学习但没有优化器的单层方法。我们应该考虑复杂性和实用性之间的权衡。
基于深度的视频编码的反观点
[Jay] 我对基于深度的视频编码有不同的看法。当前的视频编码框架已经微调了几十年。现在,人们愿意考虑一种非常不同的方法。如果没有好的替代方案,基于深度的编码是最受关注的。但是,如果有其他选择,情况可能会有所不同。如果我们不理解深度学习为什么有效,那么很难找到一个有竞争力的替代方案。我们尝试开发一种新的视频编码方法,它可以捕捉深度学习的本质,但它不是基于深度的。
重点之一是绿色视频编码,这意味着低功耗。深度学习显然不是绿色解决方案。
新的视频编码标准的目标是以 10 倍的复杂度压缩 50% 的带宽。随着光纤、5G 等宽带基础设施的到位,比特率的降低可能不那么关键。另一方面,随着越来越多的视频物联网(IoT)设备的部署,非常需要节省电力,而具有更低功耗的视频编码变得重要。例如,VVC 在优化率失真权衡方面非常出色。但是,我们可能需要进一步降低其复杂度。由于基于深度的编码技术偏离了这一绿色原则,我对此不太感兴趣。
视觉质量评估及其影响
第三个问题是“视觉质量评估是学术界的一个热门研究课题。已经发表了许多论文。这项工作会对视频编码标准化产生真正的影响吗?”
关注新媒体的视觉质量评估
[Jay] 压缩伪像不是常见的伪像,是来自图像/视频编码的特殊伪像。由于低码率视频的质量太差,无法吸引人们观看,对低码率伪像评价的研究较少。另一方面,当码率高时,不同质量指标之间的差异很小。我在使用 PSNR 作为高码率图像/视频质量指标没有疑问;开发新的质量指标的价值值得怀疑。主战场应该在中等码率的图像/视频中。
对于有监督质量评估,主要挑战是如何进行监督。进行大规模的主观测试是耗时耗力的。关于全参考或无参考质量指标,通常在编码器端具有全参考而在解码器端没有参考。由于解码器环境的多样性,很难校准解码器环境。由于这些变化,存在许多研究问题,对此我们已经看到许多关于视觉质量评估的论文发表。
2013 年至 2015 年,我与 Netflix 合作开发了 VMAF 全参考视频质量指标。由于 Netflix 有用户社区,因而可以在其视频传输系统中采用 VMAF,并使其成为一个开源平台。因此,VMAF 也成为了其他一些公司采用的视频质量指标。不过,这是一个罕见的用例。
尽管已经发表了许多图像/视频质量评价的论文,但很难产生实际影响。在我看来,我们应该更加重视立体视频、360 度视频和 AR/VR 等新媒体格式的质量评估。显然,PSNR 不适合它们。
[Shan] 除了提供用户视觉体验的客观测量,视觉指标还用于视频编码,如模式决策过程。几十年来,PSNR 或 MSE 已被用于视频编码器的调谐,并被证明是有效的。另一方面,PSNR 等传统视觉指标不适合评估某些新兴媒体格式的视觉质量,例如点云和光场等。开发新指标的需求正在上升。
标准委员会的经验
[Gary] 到目前为止,在国际标准委员会中,我们还没有看到使用 PSNR 会导致我们在视频格式设计中做出错误的决定。当我们试图使用其他指标时,有时会感到困惑,总体而言,它们通常都指向同一个方向。最近,我们看到 JPEG-XL 对于不同的指标得到了截然不同的结果,而这种设计还没有得到充分的研究。到目前为止,我们还没有看到改进的指标对标准化产生巨大影响,但这些指标有巨大的潜力。
端到端编解码器的主观质量
[Hsueh-Ming] 对于娱乐视频,压缩目标是主观质量。就 PSNR 而言,端到端编解码器可以产生与 VVC 相当的值。然而,就 MS-SSIM(可能是比 PSNR 更好的指标)而言,经过训练以优化 MS-SSIM 的端到端编解码器比 VVC 性能要好得多。另一方面,与许多其他基于 DNN 的方案类似,在某些情况下,端到端编解码器可能无法产生对原始图像的良好近似。因此,这可能成为诸如医学成像的某些应用中的关注点。
学术界的作用
提出的第四个问题是“学术界在开发新一代视频编码技术(或标准)方面是否有作用?”
学术界可能的研究领域
[Wen-Hsiao] 学术界在探索新的和创新的想法方面更为灵活,从工业界角度来看,这些想法似乎更为长期,还不太成熟。浏览 2018 至 2021 CVPR 基于学习的图像压缩挑战(CLIC)的方案贡献者(见图7),大多数贡献者最初来自学术界。随后,更多的工业界贡献者加入进来。最近,我们看到了工业界和学术界之间的合作。因此,学术界有足够的空间与工业界合作,为视频编码的未来做出贡献。图7
[Hsueh-Ming] JPEG-AI 成立了一个特别小组,重点关注端到端编码方法标准化的可能性。它的范围和框架不限于面向人类的视频观看,还面向图像处理和机器视觉任务。换言之,压缩后的图像可以通过诸如超分辨率或去噪之类的图像处理方法来处理,进而用于诸如分类、对象检测/识别、语义分割等计算机视觉任务。因此,目标不仅限于为观众提供良好的主观质量,还包括为图像处理和计算机视觉产生良好的结果。这项标准活动目前正在进行。
[Gary] JPEG-AI 不仅在寻求压缩效率,还在寻找基于神经网络的编码方法可以实现的其他功能。
理解事物本质
[Shan] 深度学习已证明其在解决各种计算机视觉和图像处理问题方面的有效性,因此近期将深度学习应用于视频编码的热情越来越高。一个观察结果是,有些学者把神经网络当作一个黑匣子,似乎认为通过调整参数可以很容易地获得好的结果。值得提醒的是,任何研究如果要取得成功,都需要深入了解基本原理。技术发展需要健康的生态系统来培育和滋养。学术界和工业界的合作发挥着重要作用。
与工业界合作
[Jay] 我想强调工业界和学术界合作的重要性。学术界人士只要有新想法就可以写论文。如果其中一个成果最终被工业界采用,那就是一个巨大的成就。
给学生的建议
最后一个问题是“你对那些想从事视频编码研究的学生有什么建议?”
领域和新框架
[Dong] 第一点,我们鼓励学生对深度学习和视频压缩都进行充分的了解,因为许多领域都是跨学科的。第二点,我们鼓励学生学习新的框架。例如,端到端编码器最初是在像素域上进行运动估计并提取光流信息,但现在可以通过可变形卷积在特征空间上完成类似的处理。第三点,我们鼓励学术解决黑匣子之外的基本问题。因为目前很难解释神经网络为什么适用于图像/视频压缩,但这一问题十分重要。第四点,随着人工智能和深度视频压缩的快速发展,未来我们终将拥有一些可用于视频压缩、人脸识别和许多其他应用的人工智能芯片。我们鼓励学生对视频编码相关的硬件展开研究。
学习门槛——深度学习vs视频编码
[Jay] Python 和 TensorFlow 等机器学习工具的入门门槛较低。学生们很可能在三个月内就能很好地了解深度学习。相比之下,视频编码具有较高的入门门槛。新人可能需要花费 1 到 2 年的时间才能熟悉编码器的参考代码(c / c++)。高门槛是一种保护,因为其他人无法在短时间内获取相同的技能,专家也很难被取代。相比而言,深度学习从业者更易被替换,因为低门槛不仅对他们有好处,而且对其他人也有好处。
许多公司都在寻找机器学习方面的人才,但求职人数很多。尽管视频编码的工作机会较少,但求职者的数量也较少。从需求方面来看,多媒体行业需要编码工程师,目前看来供不应求。
信号处理和深度学习知识
[Shan] 传统或非基于学习的视频编码仍然是当今视频通信的主干。例如,在实时视频会议中,视频编码提供了核心功能,而深度学习可以用于一些附加功能,例如虚拟背景和脸部滤镜。在过去的 3-4 年里,我没有遇到过深度学习背景的求职者短缺的情况,但拥有视频编码专业知识的求职者并不多。与高市场需求相比,视频编码工程师的人员供应量似乎极少。一个好的视频编码工程师可以收到许多顶级公司的报价供选择。视频编码建立在信号处理理论的基础上。具有扎实的信号处理和深度学习基础的学生是公司的理想选择。
基础知识的重要性
[Jiaying] 在我 2010 年博士毕业后,我的研究方向从视频压缩转向计算机视觉任务。不过在2018年,我们的团队再次回到了视频编码领域,因为我们发现计算机视觉中的一些关键技术,可以自然地用于视频压缩方案。它有助于我们获得准确的预测或拟合更复杂的关系。
我们团队还对机器视频编码非常感兴趣,这一方向将信号处理和计算机视觉结合在一起,并使用神经网络作二者间的桥梁。
其他的很多新方向都扩展了视频编码的研究范围。不过我认为基础知识非常重要,尽管我的学生都非常熟悉网络调参,但信号处理方法的知识可以给我们很大的启发。
引用
- J. Shi and Z. B. Chen, “Reinforced Bit Allocation Under Task-driven Semantic Distortion Metrics,” in Proc. IEEE International Symposium on Circuits and Systems (ISCAS), Oct 2020.
- J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational Image Compression with a Scale Hyperprior,” in Proc. Int. Conf. Learning Representations (ICLR), 2018.
- G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An End-to-end Deep Video Compression Framework,” in Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019, 11006–15.
- E. Agustsson, M. Tschannen, F. Mentzer, R. Timofte, and L. Van Gool, “Generative Adversarial Networks for Extreme Learned Image Compression,” arXiv:1804.02958, 2018, 4.
- J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end Optimized Image Compression,” in Proc. Int. Conf. Learning Representations (ICLR), 2017.
- J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational Image Compression with a Scale Hyperprior,” in Proc. Int. Conf. Learning Representations (ICLR), 2018.
- D. Minnen, J. Ballé, and G. Toderici, “Joint Autoregressive and Hierarchical Priors for Learned Image Compression,” in Advances in Neural Information Processing Systems (NIPS), 2018, 10794–803.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
