
图像压缩与视觉分析通常作为独立领域研究,很少结合讨论。本论文提出了一种分层端到端人脸图像编码模型,该模型在高压缩比下提供高质量的人脸图像重建,同时支持多种视觉分析任务。通过联合优化和基于压缩域的多任务分析,模型能够在大幅降低比特率的同时,保持与 RGB 图像相当的分析效果和重建质量,其实用性在参数量和信息保真度上得到了验证。
论文标题:Machine Perception-Driven Facial Image Compression: A Layered Generative Approach
作者:Yuefeng Zhang, Chuanmin Jia, Jianhui Chang, Siwei Ma
来源:TCSVT 2024
论文链接:https://ieeexplore.ieee.org/abstract/document/10570244
内容整理:陈晓
引言
通常图像压缩与图像视觉分析这两个课题遵循各自独立的研究路径,较少被共同讨论。由于端到端图像压缩方法提供了紧凑的压缩特征表示方法,那么可以认为存在着某种高效数据表达,即有效支持压缩要求又满足视觉分析需求。本论文提出了分层端到端式人脸图像编码模型,压缩所得压缩域数据在高压缩比条件下,能够既保证面向人类视觉的高重建图像质量,又有效支持多种下游视觉分析任务。本论文采用了联合优化方法和基于压缩域的多任务分析模型以获取更紧凑且更适用于下游分析任务的压缩域特征。实验结果证明,本论文提出的基于压缩域数据的多任务分析方法可以取得与基于 RGB 图像的方法相当的视觉分析效果,在节99.6%的比特率(与将原始 RGB 图像作为输入相比)的同时能够保证重建图像感知质量。本论文模型的实用性从基于压缩数据的分析模型参数量与和重建图像结构保信息真度两方面得到了进一步证明。
方法
本文方法分为分层式端到端图像压缩模型与基于图像压缩域的视觉分析两大部分。
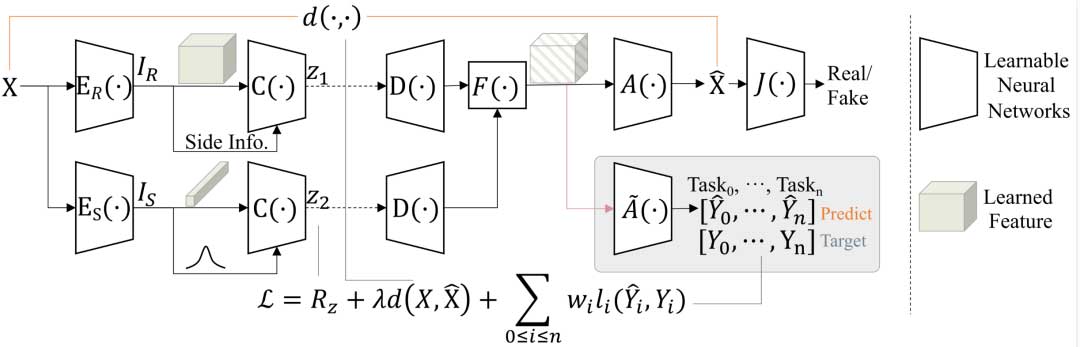
分层式端到端图像压缩模型
本论文所提出的分层式端到端人脸图像压缩模型有三个主要部分:编码器、解码器和概率估计模型。
分层编码器
通过预先定义的信息可对图像进行分层压缩,即为根据图像所分不同层特性分别进行数据压缩。本论文采用不同的编码器将输入图像信号 X 编码为特征 IR 和 IS,分别支持重建和语义分析目的。这里相应的编码器被记作 ER 和 ES,重建特征和语义分析特征可以表示为 IR = ER(X) 和 IS = ES(X)。
融合模块与解码器

优化目标定义
训练设置在将数据压缩与视觉分析相互融合方面非常重要。就任务目标而言,本论文归纳两种类型的训练策略:a) 面向人类视觉任务;b) 面向机器感知任务。
除保持图像信号层面的保真度外,压缩重建图像应适应人眼主管感知。因此,为了满足人类视觉多方位需求,本论文所采用的失真度量包括三个部分:像素级的平均绝对误差(Mean Average Error,MAE)损失,基于SSIM的整体结构级损失dMAE(即

基于图像压缩域的视觉分析
基于学习的图像压缩模型有潜力去用更紧凑的压缩数据获得机器视觉分析任务性能。本论文设计基于压缩域的多视觉分析任务网络并采取联合训练与独立训练两种模式。接下来将介绍基于压缩数据多任务分析网络和优化目标设置。
多任务分析网络

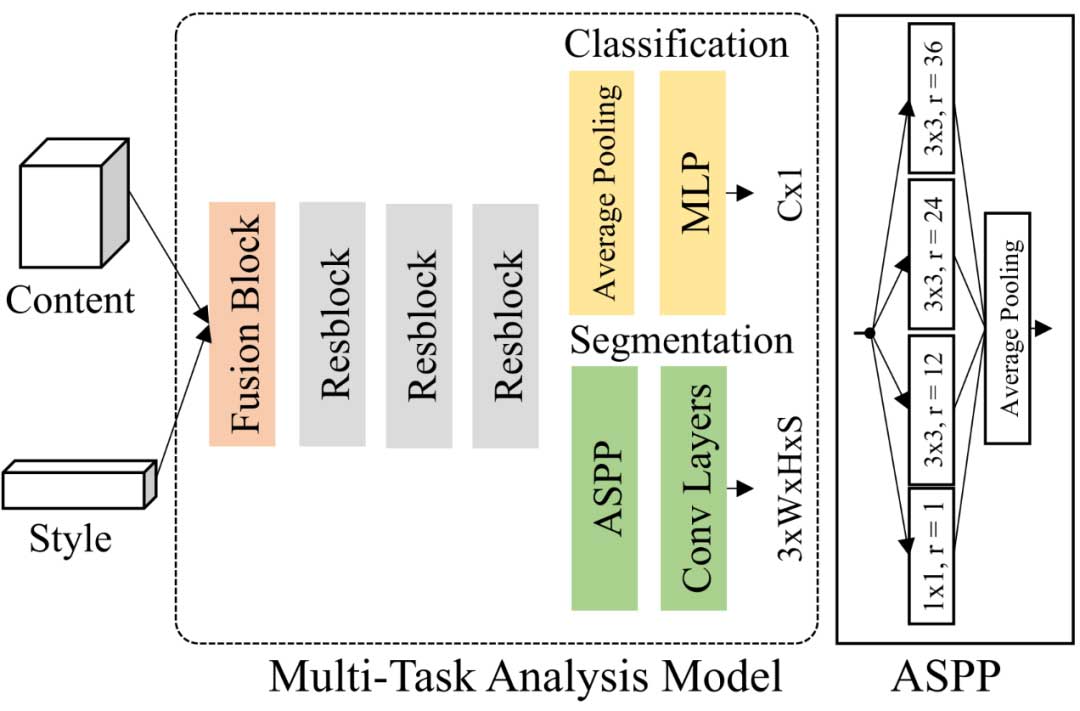
优化目标定义
本论文研究两种类型的训练方式(即单独训练和联合训练),以进一步探索压缩和基于压缩域机器视觉感知之间的关系,实现既满足人眼视觉需求又高效适用于机器分析任务为目标的图像压缩模型。两种训练方式之间最主要且直观的区别为优化参数设定的不同,下文将逐一进行介绍。

实验
重建图主客观质量评价

图中展示了本论文方法与对比方法所得重建图像,主观上本论文所提人眼导向图像压缩方法在极低码率下仍能保持高感知保真度的重建图像质量。
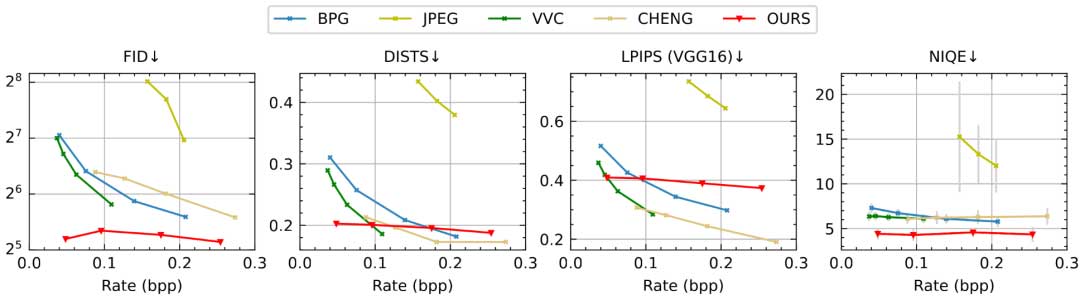
图中展示以人眼视觉感知为导向的客观图像质量评价准则,包含 FID、DISTS、LPIPS和NIQE。结果显示,尤其是在 FID 和 NIQE 准则上,本论文模型在极低码率约束下(即bpp<=0.1)大幅度优于对比方法。
视觉分析性能对比
单任务与多任务对比
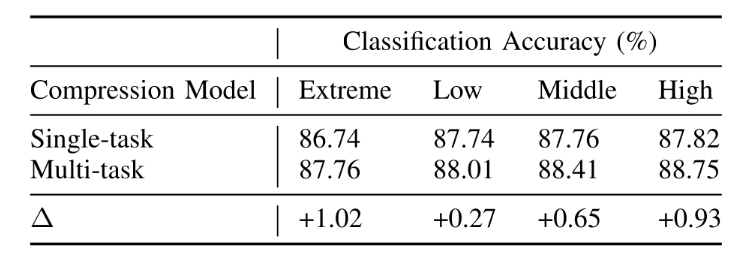
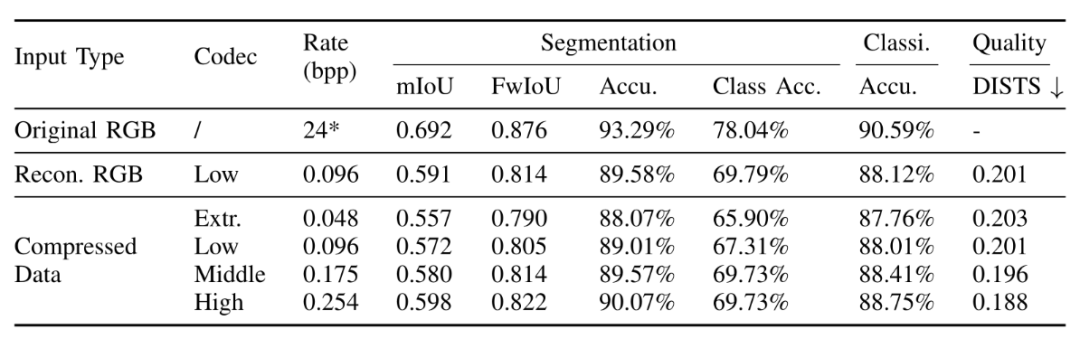
在表中,本论文探索图多任务网络对分析感知任务性能的影响。以分类任务为例,多任务分析网络与单任务分析网络相比带来准确度的提升0.7%,说明多任务学习对基于压缩域的分析问题有正向作用。
基于压缩域与原始RGB图片分析性能对比
为验证基于压缩域特征的分析性能,本论文对基于压缩域特征和原始 RGB 图片的视觉分析性能相比较。需注意,基于原图的分析性能一定优于基于重建图或压缩域的分析性能。表中展示相关对比结果。以本论文所提出低码率模型为例,以压缩域特征为输入的多任务分析网络与原始 RGB 图片相比在 mIoU 指标上损失0.8%准确度而节省99.6%码率(即(24-0.096)/24 x 100%)。
独立训练与联合训练对比
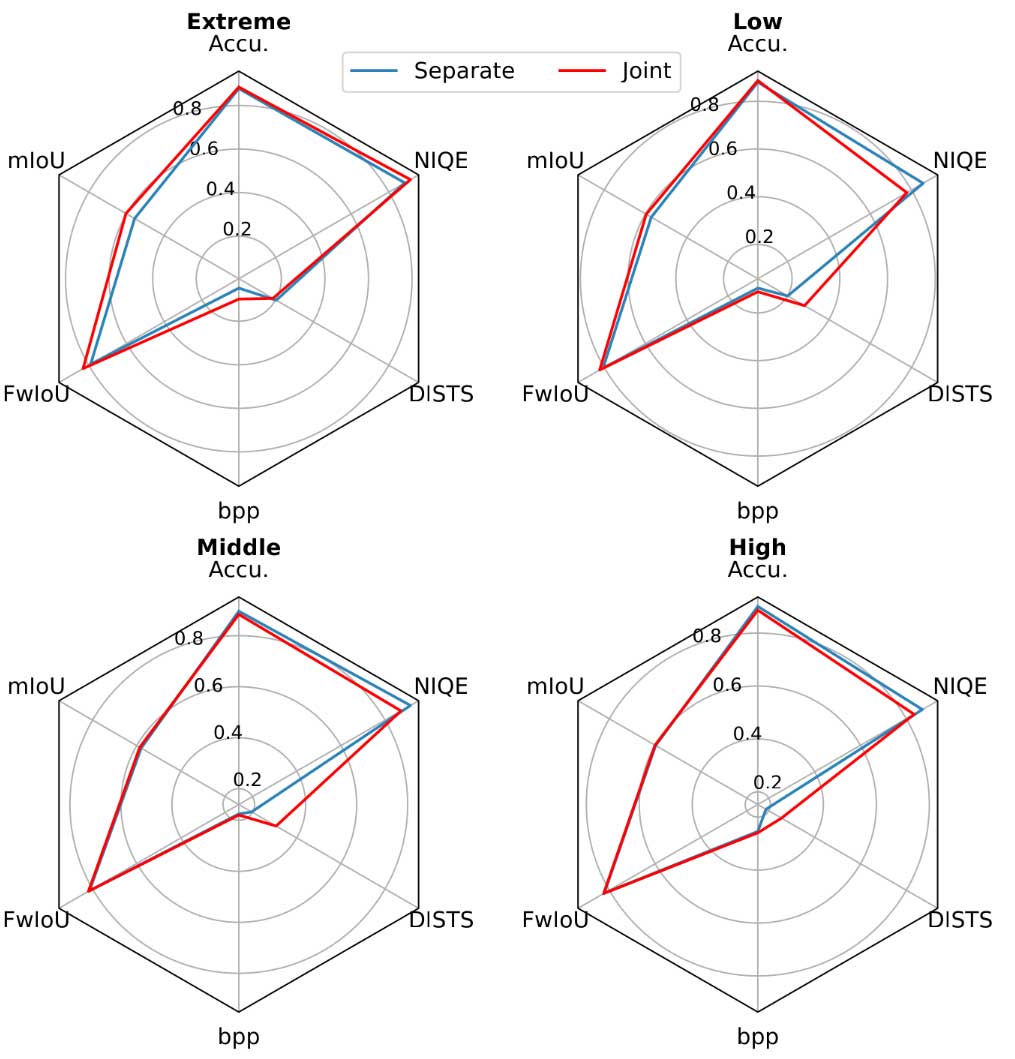
本论文从三个方面评估联合训练模式效果,即:压缩率、重建图像质量和视觉分析性能,并将独立训练与联合训练模式做对比。如图中雷达图所示,在极端的压缩条件下(高压缩率情况下),视觉分析性能的提升是以其他两个评估维度上的有限成本为代价的;重建图像质量在高压缩率下显示出在不同图像质量评价指标之间存在取舍或权衡关系。可以推断,存在着视觉分析-失真-人眼感知三者的权衡,而这可以被看作是分类-失真-感知理论在现实世界压缩问题中的应用延伸。
总结
本论文提出了一个分层式端到端图像压缩模型,取得高效重建图像人眼视觉保证度(通过四个感知质量指标上的实验证明)的同时,本论文实现以压缩域数据作为下游视觉分析任务输入,达到与原始 RGB 图片为输入网络可比的分析效果。为了实现分析效率和灵活性,本论文提出一个以压缩域数据为输入的多任务分析模型,可有效地支持多种下游视觉分析任务。本论文在人脸图像数据上进行了全面的实验,实验结果验证多个独立的视觉分析任务可直接从压缩域表征中推理得到高效分析性能,并同时在接收端节省解码时间与减少解码器空间占用,证明了所提出的模型具有一定实用价值。
本论文实验与分析为在压缩域表征上进行视觉分析任务推理提供了可行性参考,特别是针对基于学习方法所得的压缩域表征。尽管基于生成方法的图像压缩模型对于强调像素保真度的评价指标(如 PSNR 和 MSE )存在其局限性,但本论文强调其主要优势在于对人眼感知导向信息的保留和对机器感知分析的灵活支持,而不是图像像素级信号保真度,这为未来的编解码器提供研究参考。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
