
在当今数字化时代,大模型以其强大的数据处理和复杂问题解析能力,正深刻改变着我们的现实生活。以GPT4o等为例,大模型已经具备了令人惊叹的全双工语音交互能力,其中实时交互是语音对话的关键。因此,如何在保持大模型强大能力的同时,提升其实时性能,成为了当前技术发展的一个重要方向。
同样在语音交互的场景下,统一的语音-文本模型,如SpeechGPT[1],VioLA[2]和AudioPaLM[3],在各种与语音相关的任务中都表现出令人印象深刻的性能,特别是在自动语音识别( Automatic Speech Recognition,ASR )中。这些模型通常采用统一的方法对离散的语音和文本令牌进行建模,然后训练一个“decoder-only”的模型。然而,它们在解码过程中需要整条语音,在实际场景中难以满足客户的需求。因此,我们设计了一个专门为流式语音识别的“decoder-only”模型。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和度小满合作论文“Streaming Decoder-Only Automatic Speech Recognition with Discrete Speech Units: A Pilot Study”被语音领域旗舰会议Interspeecch 2024接收。该论文提出了流式识别的“decoder only”模型,引入了特定语言的适配器专用的边界令牌,以方便流式识别,并在训练阶段使用因果注意力掩蔽。进一步地,引入右块注意力和各种数据增强技术来改进模型的上下文建模能力。本文将对该文章进行简要的解读。
论文标题:Streaming Decoder-Only Automatic Speech Recognition with Discrete Speech Units: A Pilot Study
作者列表:陈培坤,孙思宁,单长浩,杨青,谢磊
合作单位:度小满
论文链接:https://arxiv.org/pdf/2406.18862

背景动机
目前,在基于LLM的ASR中,语音模态与LLM的集成主要有两种方法。一种方法是通过可训练的适配器将连续特征与文本嵌入直接集成。这类方法引入了额外的声学编码器,分别对语音和文本进行建模。相反,另一种方法是将语音表示视为文本标记,并使用“decoder-only”模型来有效地优化多模态任务。例如,VioLA 通过EnCodec[4]将连续的语音信号转换为离散的编解码器代码,并将多个与语音相关的任务统一为一个条件语言建模任务。SpeechGPT 以LLaMA[5] 为基本框架,利用Hubert[6]对语音信号进行k-means聚类。类似地,AudioPaLM使用PaLM-2[7]作为其底层架构,并从通用语音模型的编码器中提取离散令牌。这种统一的建模方法已经被证明可以有效地提高ASR的性能。具有统一离散输入的“decoder-only”的Transformer模型为各种语音相关任务提供了一种新的范式,包括但不限于语音识别和语音合成。
先前关于“decoder-only”的ASR任务的工作主要集中在非流式场景。然而,在实际应用中,实时流式识别可以给出更快的识别结果和更好的用户体验,针对流式“decoder only”的语音识别的探索非常有限。随着“decoder-only”的ASR模型性能的提高和模型参数数量的增加,流式低延迟推理成为一项具有挑战性的任务。
提出的方案
模型结构如图1所示,三种不同的方案分别代表(a)过去的非流式speechLLM;(b)文本插入的流式speechLLM;(c)边界插入的流式speechLLM。
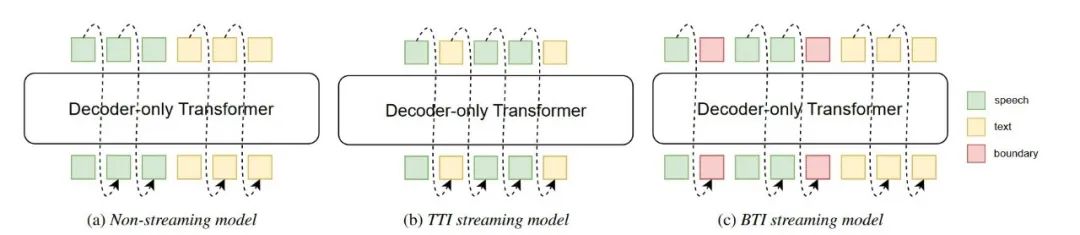
文本插入和边界插入
如式下列公式所示,给定离散语音标记序列 x = (x1,…,xt,…,xT) 和对应的文本标记序列 y = (y1,…,yl,…,yL) ,流式ASR模型通过最大化条件概率来优化,其中 tyi + Δ 是发出文本标记 yi 的时间,Δ 是一个常数,这意味着可以使用多少个正确的上下文标记。
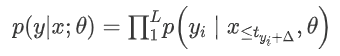
在图 1 (b) 中,文本插入 (TTI) 方法展示了离散语音和文本标记的交错,其中文本标记插入到相应语音段末尾的语音标记中。数学上,相当于直接优化式(1)。然而,文本和语音标记的混合使解码期间波束搜索的使用变得复杂。在推理过程中,语音标记可以被视为条件。
图 1 (c) 说明了边界插入 (BTI) 方法,其中将特殊令牌而不是文本令牌插入到语音令牌序列中,从而有效地解耦文本和语音令牌序列。与图 1 (b) 相比,该过程可以被视为包括两个阶段:第一阶段涉及确定边界位置,而第二阶段需要根据语音标记的历史来预测相应的特定文本标记。下列方程提供了正式的定义。这里引入一个隐藏变量b,其中 b =(b1,…,bT) ϵ 0,1T,表示可能的边界路径之一,β表示所有可能路径的集合。然而,在实践中,通过对所有可能的路径求和来进行优化在计算上具有挑战性。因此,我们选择通过选择最可能的路径 b_p 来近似这个优化问题。
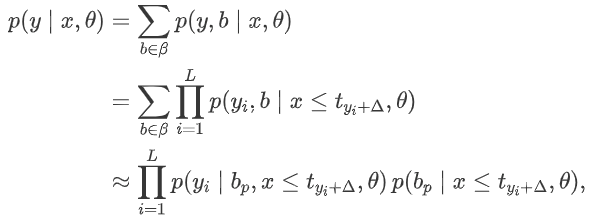
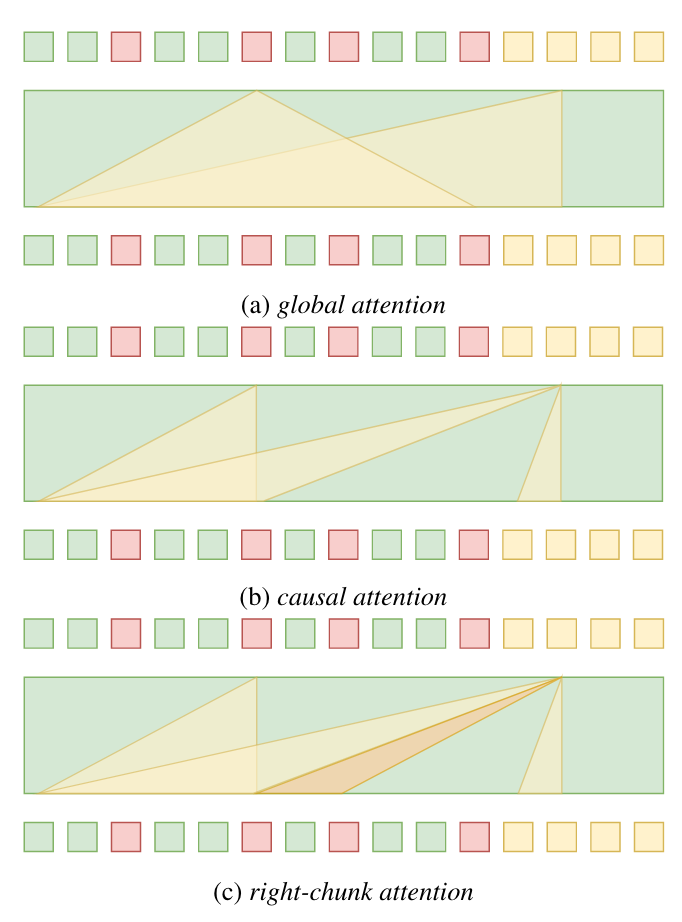
Right-chunk attention
与非流式 ASR 模型不同,流式 ASR 模型在考虑全局信息方面面临局限性,导致上下文建模能力减弱。为了解决这个问题,我们集成了右块注意力机制,如图 2 (c) 所示。与因果注意力不同,文本部分的右块注意力能够捕获更多的语音信息。
实验
实验设置
- 数据 使用中文开源数据aishell1[8]和aishell2[9],包含了178h和1000h的中文音频和500h的中文音频
- 离散单元 使用中文开源预训练模型Hubert[10],使用K-Means聚类
- 初始化模型 Qwen2[11]
- 评估指标 中文采用字错误率CER(Char Error Rate)
实验结果
表 1 列出了 AISHELL-1 上的 CER。表 1 中的第一组展示了之前研究的结果,包括半监督学习 (SSL)、基于 E-Branchformer 的 ASR 模型,以连续 Fbank 特征或离散语音标记作为输入。第二组显示使用我们提出的两种使用随机初始化的流式方法训练的小模型的结果。与S3相比,由于TTI的文本标记插入设计,S2的替换错误显着增加,这削弱了其上下文建模能力。很明显,通过 BTI 解耦边界预测和文本预测,S3 实现了更好的模型性能。第三组展示了使用Qwen-0.5B LLM初始化大型模型的结果。通过 LLM 初始化,我们首先训练一个非流式解码器模型,即模型 L1。然后,使用我们提出的流方法 TTI 和 BTI 微调模型 L1,从而产生两个版本:L2 和 L3。我们观察到,采用 LLM 初始化的大型模型在 AISHELL-1 测试集上实现了 5.9% 的 CER。将 L2 与 S2 进行比较后,我们注意到 LLM 初始化为 TTI 方法带来了相对较小的 CER 降低。这是由于与LLM相比,交错语音和文本的性质不同,导致相对 CER 收益仅为 3.1%(9.8%→9.5%)。相反,与模型 S3 相比,使用 BTI 会导致测试集上的相对 CER 降低 9.2%(6.5%→5.9%)。值得注意的是,BTI不仅表现出优越的CER性能,而且还表现出更好的LLM适应性。因此在后续的实验中,我们采用了BTI方法。

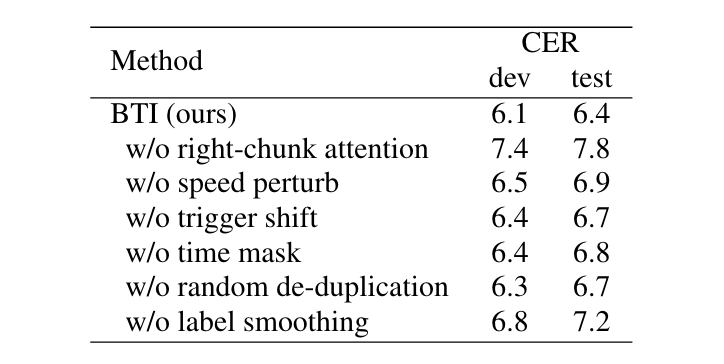
表 2 显示了基于模型 S3 的右块注意力和各种数据增强的影响。值得注意的是,右组注意力对整体 CER 的影响最为显着。如果没有右组注意力,AISHELL-1 测试集上的 CER 从 6.5% 增加到 7.8%。由于可用的上下文信息有限,缺乏右组注意力会导致更多的替换错误。我们观察到,当以统一的方式对语音和文本标记进行建模时,预测下一个语音标记比预测下一个文本标记要容易得多。因此,模型在语音标记预测期间往往会过度拟合。标签平滑有效地缓解了这种过度拟合问题。此外,其他方法也有助于降低 CER,范围为 4.4% 至 7.2%。
在表 3 中,我们展示了在没有速度扰动的情况下 AISHELL-2 语料库上的性能。最上面几行列出了基于 FBank 的传统 ASR 系统和基于 Hubert-Large 离散代币的 ASR 模型。很明显,与编码器-解码器模型相比,使用离散令牌输入和仅解码器模型产生的性能稍差(6.6% 与 6.9%)。同时,与非流式结果相比,流式模型的识别准确率下降了4.1%(6.9%→7.2%)。我们发现在大规模数据上使用离散单元训练 ASR 模型可以非常有效。我们相信,随着数据量和模型参数的增加,仅解码器模型可以完全超越传统的编码器-解码器模型。

参考文献
[1] D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y. Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,” in EMNLP 2023. ACL, 2023, pp. 15 757–15 773.
[2] T. Wang, L. Zhou, Z. Zhang, Y. Wu, S. Liu, Y. Gaur, Z. Chen, J. Li, and F. Wei, “Viola: Unified codec language models for speech recognition, synthesis, and translation,” CoRR, vol. abs/2305.16107, 2023.
[3] P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, F. de Chaumont Quitry, P. Chen, D. E. Badawy, W. Han, E. Kharitonov, H. Muckenhirn, D. Padfield, and et al., “Audiopalm: A large language model that can speak and listen,” CoRR, vol. abs/2306.12925, 2023.
[4] A. D ́ efossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” CoRR, vol. abs/2210.13438, 2022.
[5] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M. Lachaux, T. Lacroix, B. Rozi` ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,” CoRR, vol. abs/2302.13971, 2023.
[6] W. Hsu, B. Bolte, Y. H. Tsai, and et al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 3451–3460, 2021.
[7] R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen, E. Chu, J. H. Clark, L. E. Shafey, Y. Huang, K. Meier-Hellstern, G. Mishra, E. Moreira, M. Omernick, K. Robinson, S. Ruder, Y. Tay, K. Xiao, Y. Cheng, C. Cherry, L. Gonzalez, and et al., “Palm 2 technical report,” CoRR, vol. abs/2305.10403, 2023.
[8] H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “AISHELL-1: an open-source mandarin speech corpus and a speech recognition baseline,” in O-COCOSDA 2017. IEEE, 2017, pp. 1–5.
[9] J. Du, X. Na, X. Liu, and H. Bu, “AISHELL-2: transforming mandarin ASR research into industrial scale,” CoRR, vol. abs/1808.10583, 2018.
[10] https://huggingface.co/TencentGameMate/ chinese-hubert-large
[11] https://huggingface.co/Qwen/Qwen1.5-0.5B
[12] K. Kim, F. Wu, Y. Peng, J. Pan, P. Sridhar, K. J. Han, and S. Watanabe, “E-branchformer: Branchformer with enhanced merging for speech recognition,” in IEEE Spoken Language Technology Workshop,SLT 2022. IEEE, 2022, pp. 84–91.
[13] X. Chang, B. Yan, K. Choi, J. Jung, Y. Lu, S. Maiti, R. S. Sharma, J. Shi, J. Tian, S. Watanabe, Y. Fujita, T. Maekaku, P. Guo, Y. Cheng, P. Denisov, K. Saijo, and H. Wang, “Exploring speech recognition, translation, and understanding with discrete speech units: A comparative study,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024. IEEE, pp. 11 481–11 485.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
