
新冠疫情波及全球,迫使很多人在家进行工作和学习,视频会议的流量也因此急剧增加。如果有高效且准确的视频会议内容质量评价工具,就能够很好的监控和感知并协助视频会议的优化。然而现有模型在多模态实时远程呈现内容上的预测能力有限,亟需兼顾在实时性和多模态预测上都做的很好的评价方法或模型。
远程呈现内容(telepresence content)的质量评价的主要挑战包括:成功地集成多模态信号,解决主观标记数据的缺乏,以及有效地建模直播内容质量的预测。
本文构建并使用了远程呈现内容的视听质量主观数据库,通过学习方法有效地建模多模型特征,并以在线提供各种类型的质量反馈。本文的主要贡献如下:
第一个专门用于远程呈现视听质量的主观数据库。从 YouTube 和互联网档案馆收集了 2320 个远程呈现内容视频,并从 500 多名受试者中收集了大约 79K 的人类主观质量评分。
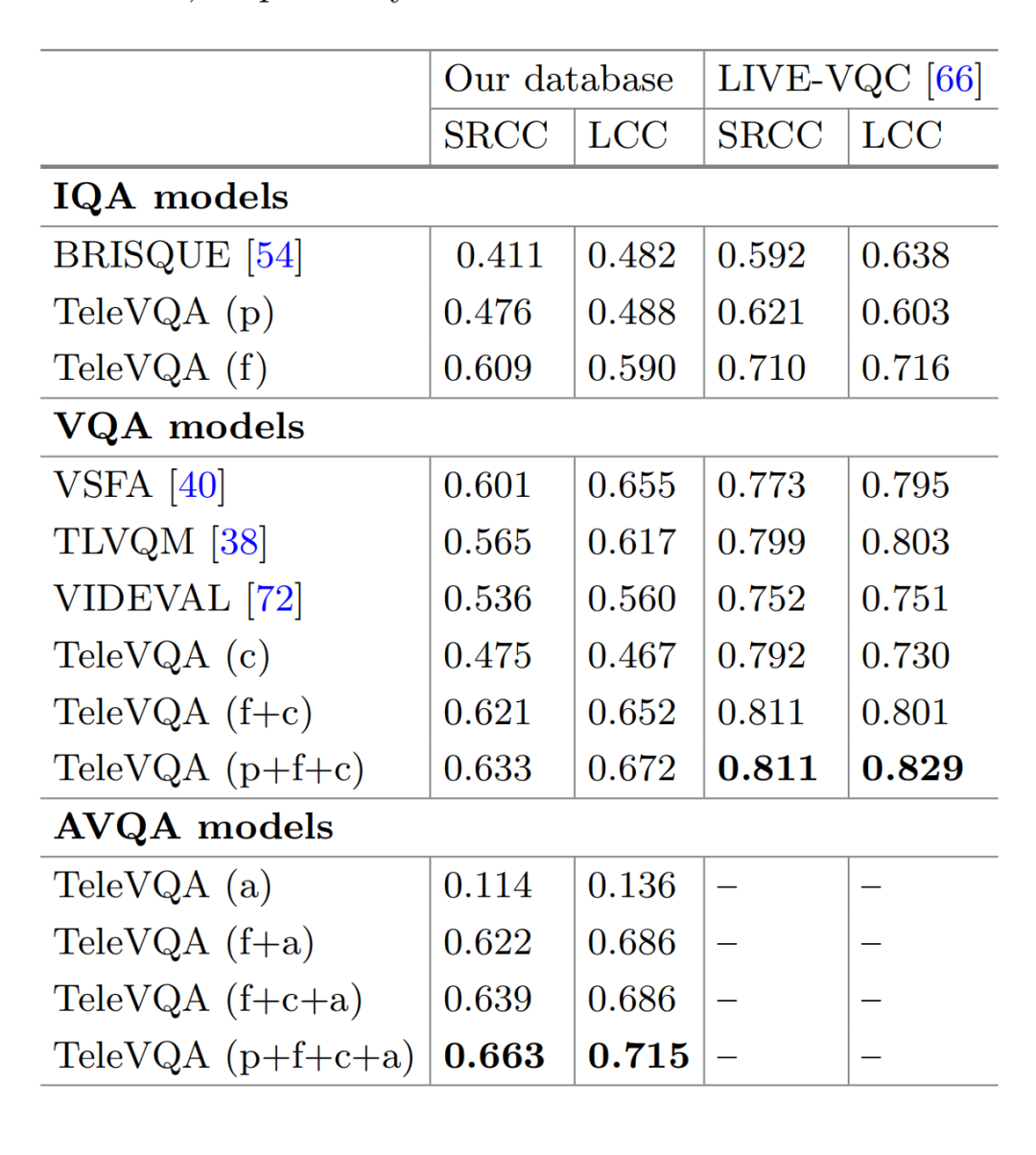
第一个在线远程呈现视频质量预测模型,称之为 Tele-VQA。这种新模型通过使用高效的 backbone 来提取多模态特征并将其集成到音频和视觉回归器中,可以在视频流到达时提供快速的高质量反馈。
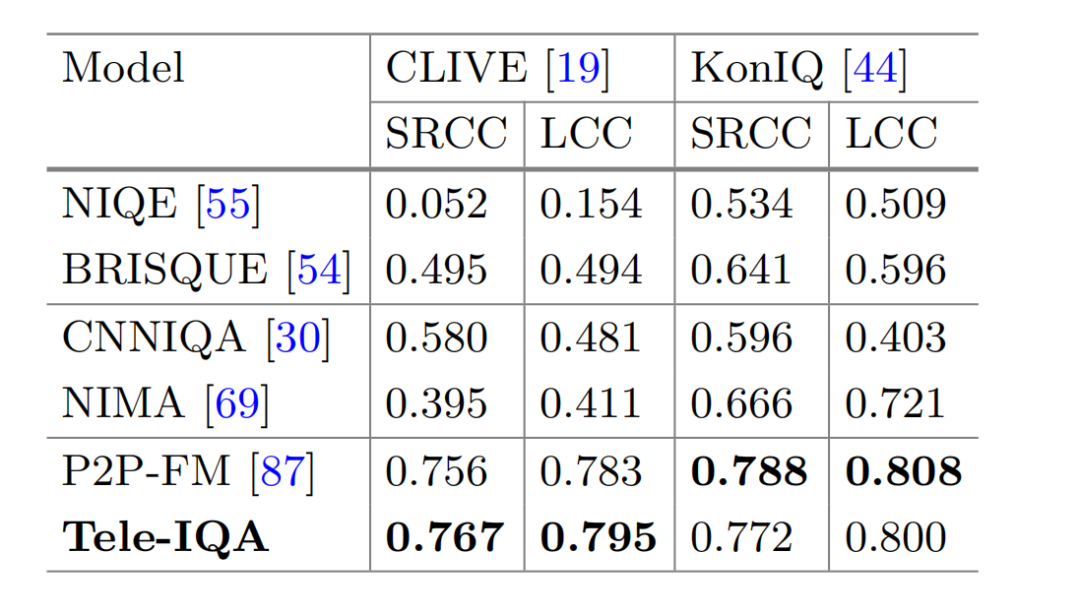
一个一体化的视听质量框架,可以处理视频和音频,在补丁、帧、视频块和视听水平上提供质量预测。Tele-VQA 的图像版本,称之为 Tele-IQA,显示了比以前最先进的模型更好的性能,而只需要 35% 的参数。
下文主要介绍TVQA的模型方法。
TVQA模型方法
TVQA算法应该包括两种主要的模式。如图所示,应用层中的一个质量测量模块接收已呈现的多媒体源,并向优化传输层的控制输入提供反馈。这意味着设计成功的TVQA模型有三个要求。
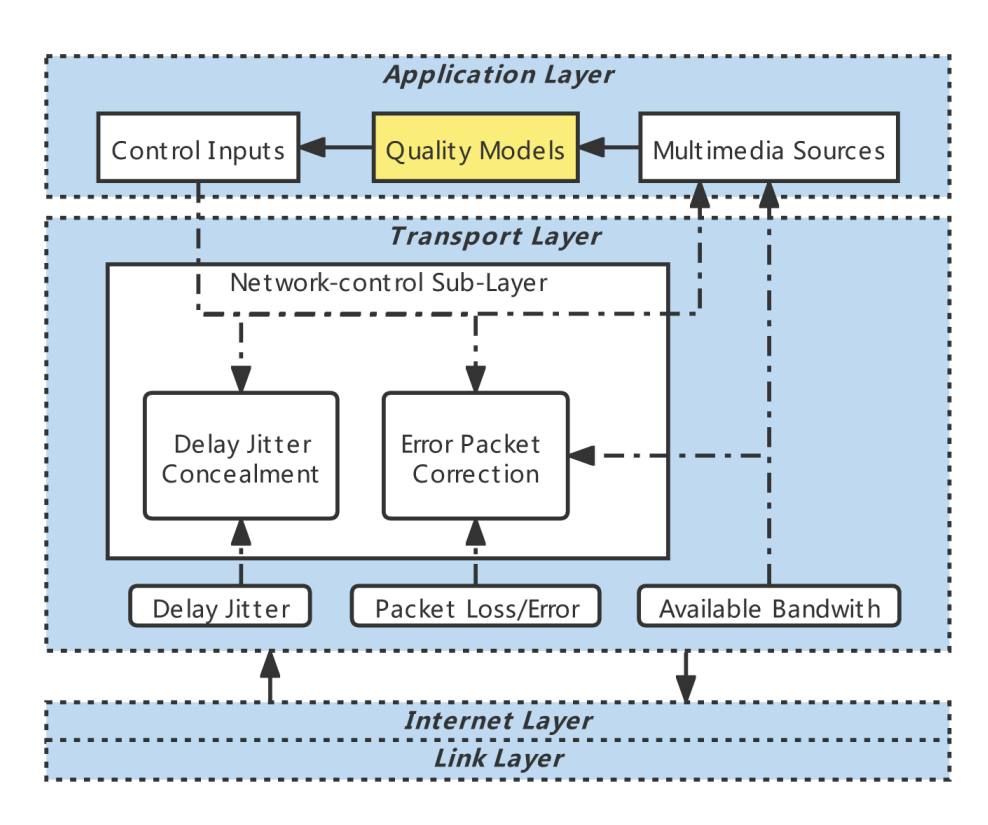
首先,视频和音频的质量都需要被准确地建模。虽然主观实验表明,视觉成分通常主导整体视听感知的质量,但音频质量并不是微不足道的(在远程呈现中,更重要),某些类型的音频失真(如背景噪声)会导致音频成分显著地影响人们对远程呈现体验质量的整体感受。其次,TVQA 算法应该能够处理“缺失模态”的问题,即如果在视频通话过程中视频或音频信号不存在,那么剩余信号的质量仍然可以被准确地预测。第三,TVQA 算法应该能够对每个模态提供单独的质量测量以及整体质量预测。这些可用于调整每个模态的网络流量优先级。
基于这些考虑,首先设计了一个名为 Tele-IQA 的图像模型,以有效地预测全局和局部的图像质量。然后,将 Tele-IQA 集成到一个名为 Tele-VQA 的视频模型中,进行远程呈现视频质量评估。
Tele-IQA
IQA模型可以看作是从图像域到真实分数集的映射函数。我们的Tele-IQA模型由三个函数组成:特征提取f 、池化 p 和回归 r。为了有效地提取 补丁(patch)的 质量预测,我们使用 RoIPool 对提取的特征图进行局部预测估计。RoIPool操作符(proI)用于从全局特征图中提取局部特征图:

Tele-VQA

Tele-VQA 包括四个连续的步骤:特征提取、特征融合、质量回归和质量融合。首先,从视频流中的补丁、帧、视频块和音频块中提取特征,捕获丰富的多模态信息。融合上述特征后,分别输入视觉特征回归模块和音频特征回归模块。每个回归模块都包含一个内部状态,以允许信息从一个 time step 传递到下一个 time step。最后,将预测的视觉和音频质量分数进行融合,形成最终的视听质量预测分数。
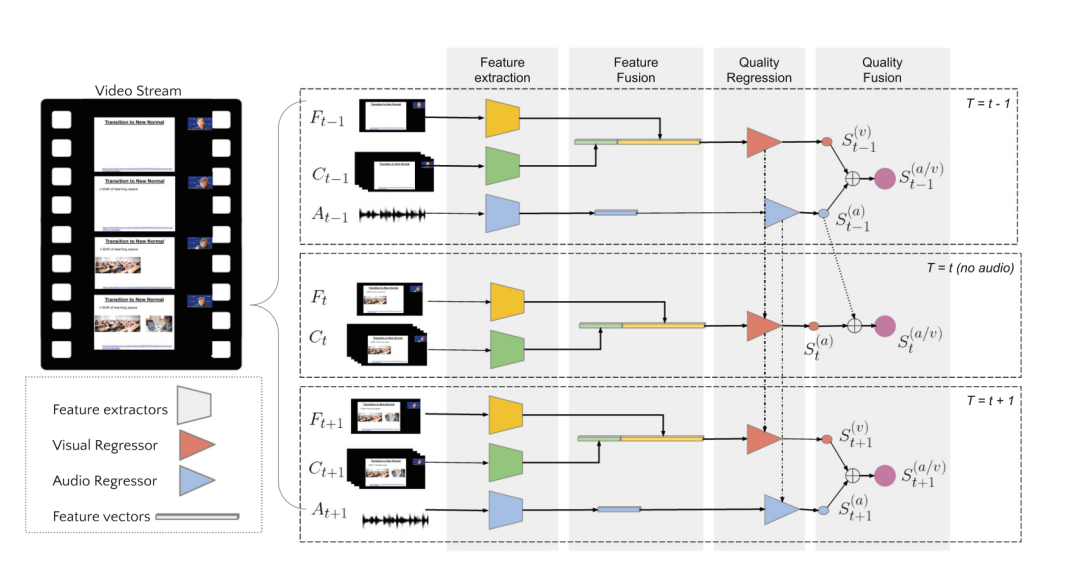
特征提取
- Frame-level 特征提取

每一帧图像可以得到 960 个特征图,使用尺寸为 1×3 的自适应平均池化,然后flatten降维,最终产生 2880 维的特征向量。
- Patch-level 特征提取
补丁级特征主要为了提取空间域的扭曲失真。为了提取补丁质量特征,我们将帧划分为一个2d×2d网格(d = 1,2,3,4),并在每个 RoI 区域上应用 RoI 池化:
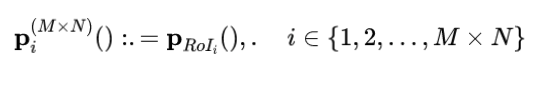
然后,将不同尺度的质量图的预测质量分数连接成一个向量:

- Clip-level 特征

我们修改了在 Kinetics 数据集上预训练的R(2+1)D 模型,去除最后一个池化层,作为提取时空特征的骨干。框架与补丁级特征一样,沿着空间维度应用1×3的自适应平均池化。flatten后产生 1536 维的特征向量。
- Audio-level特征

特征融合
我们使用不同的路径来处理视觉和音频信息。对于视觉分支,我们将帧级、补丁级和视频块级的特性连接起来。最终得到4757维的视觉特征向量和1536维的音频特征向量。
质量回归
所得到的视觉和音频特征被输入两个不同的GRU-FCN模块以进行质量回归。从整个视频中提取的特征可以被视为一个多变量的时间序列。在线预测模型在每个时间步长上都接受一个单个样本点。在这里,把质量分数回归视为一个时间序列回归(TSR)问题,使用GRU-FCN来解决它,GRU-FCN包括两个主要的模块。门控循环单元(GRU)用于一步步地学习时间依赖关系,而全卷积网络(FCN)接受整个时间序列作为输入来进行特征提取。
质量融合
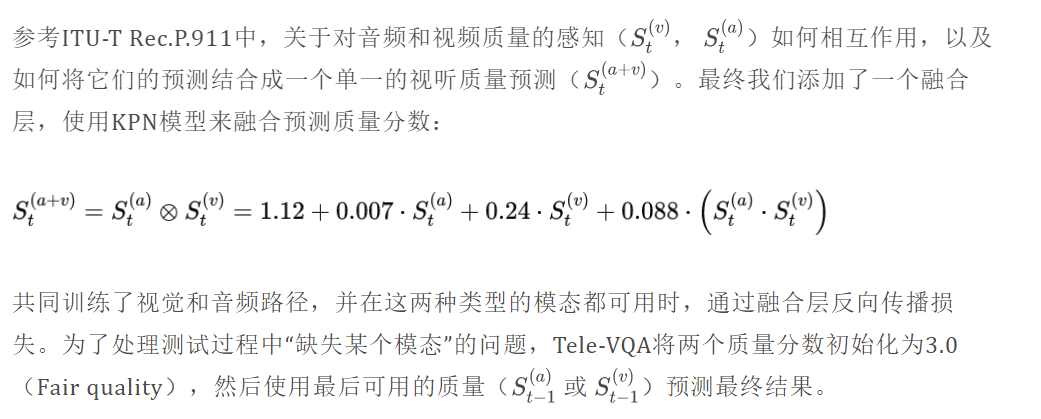
结果
作者:Zhenqiang Ying 等
来源:ECCV 2022
论文题目:Telepresence Video Quality Assessment
论文链接:https://arxiv.org/pdf/2207.09956.pdf
内容整理:贾荣立
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
