
训练具有数十亿参数的视频基础模型是一个具有挑战性的任务。视频掩蔽自编码器(VideoMAE)是一种可扩展的通用自监督预训练模型,用于建立视频基础模型。这篇文章在模型和数据方面对VideoMAE进行了扩展。具体而言,提出了一种用于有效预训练的双重掩蔽策略,其中编码器对视频token的子集进行操作,解码器处理视频token的另一个子集。尽管VideoMAE由于编码器中的高掩蔽比而非常高效,但掩蔽解码器仍然可以进一步降低总体计算成本。此外还使用了一种渐进式训练范式,该范式包括在不同的多源未标记数据集上进行初始预训练,然后在混合标记数据集中进行后预训练。最后,成功地训练了一个具有十亿个参数的视频ViT模型,该模型在Kinetics和SomethingSomething数据集上实现了最先进的性能。此外,文章还在各种下游任务上广泛验证了预训练的视频ViT模型,证明了其作为通用视频表示学习器的有效性。
题目:VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
作者:Limin Wang,Bingkun Huang,Zhiyu Zhao,Zhan Tong,Yinan He,Yi Wang,Yali Wang,Yu Qiao.
来源:CVPR 2023
文章链接:https://arxiv.org/abs/2303.16727
整理:李江川
引言
在大量数据上有效地预训练大型基础模型正在成为学习多种数据模式(例如,语言、音频、图像、视频)的通用表示的成功范例。通过零样本识别、线性探测、即时调整或微调,这些基础模型可以很容易地适应广泛的下游任务。与针对单个任务的专用模型相比,它们表现出优异的泛化能力,已成为推动人工智能许多领域发展的主要动力。
对于视觉任务,许多研究者都致力于开发有效的预训练模型。其中,Transformer正在成为一种概念上简单但有效的自监督视觉学习器(例如,用于图像的BEiT、SimMIM、MAE,以及用于视频的MaskFeat、VideoMAE、MAEST)。同时,基于语言模型的研究结果,模型容量和数据大小是其性能改进的重要因素。然而,对于预训练的视觉模型,很少有工作试图将这种掩蔽自编码器预训练扩展到图像域中的十亿级参数模型,部分原因是高计算开销。
根据在语言和图像方面的发现,本文旨在研究视频掩蔽自编码器(VideoMAE)的缩放特性,并在各种视频下游任务中突破其性能极限。在模型大小和数据规模上对VideoMAE进行了缩放。对于模型缩放,试图用具有十亿级参数的ViT实例化VideoMAE,对于数据缩放,希望将预训练数据集大小增加到百万级,以充分释放十亿级ViT模型的威力。然而,要成功地在如此大量的数据上训练巨型VideoMAE,并在所有的下游任务上实现令人印象深刻的改进,仍然需要仔细解决一些问题。
首先,计算成本和内存消耗是在当前内存有限的GPU上扩展VideoMAE的瓶颈。尽管VideoMAE通过采用高效的非对称编码器-解码器架构(即在编码器中丢弃大量token)提高了其预训练效率并降低了内存消耗,但它仍然无法很好地支持十亿级视频转换器预训练。在64个A100 GPU上使用VideoMAE预训练ViT-g模型需要两周多的时间。为了进一步提高其预训练效率,发现视频数据冗余不仅可以用于掩蔽编码器中的大部分token,还可以用于丢弃解码器中的一些token。这种解决方案导致了更高的预训练效率,并创建了一个同样具有挑战性和意义的自监督任务。在实践中,它将增加预训练的batch size,并将预训练时间减少三分之一,而几乎没有性能下降。
其次,MAE仍然需要大数据,十亿级ViT往往对相对较小的数据进行过拟合。与图像不同,现有的公共视频数据集要小得多。例如,Kinetics400数据集中只有0.24M个视频,而ImageNet-22k数据集有142M个图像,更不用说那些无法访问的图像数据集,如JFT-3B了。因此,需要想出新的方法来构建更大的视频预训练数据集,以很好地支持十亿级的视频转换器预训练。实验结果表明,简单地混合来自多个资源的视频数据集可以为VideoMAE生成有效且多样化的预训练数据集,并提高其预训练模型的下游性能。
最后,掩蔽自编码有望学习不变特征,为ViT微调提供有利的初始化。然而,在相对较小的视频数据集(例如,0.24M个视频)上直接微调十亿级预训练模型可能是次优的,因为有限的标记样本可能导致微调中的过拟合问题。事实上,在图像域中,中间微调技术已被用于提高预训练模型的性能。实验表明,收集多个标记的视频数据集并构建有监督的混合数据集可以作为大规模无监督数据集和小规模下游目标数据集之间的桥梁。通过这个标记的混合数据集对预先训练的模型进行逐步微调,可以提高下游任务的性能。
基于上述分析,本文提出了一种简单有效的方法,在包含百万级视频的数据集上将VideoMAE扩展到十亿级参数量的ViT模型。技术改进是为掩蔽自编码器引入了双重屏蔽策略。除了编码器中的掩蔽操作外,还提出了基于视频中数据冗余先验的掩蔽解码器。使用这种双重掩蔽的VideoMAE,遵循图像中的中间微调技术,并使用渐进训练在百万级未标记的视频数据集上执行视频掩蔽预训练,然后在标记的混合数据集上进行后预训练。这些核心设计有助于一个高效的十亿级视频自编码框架,称为VideoMAE V2。在这个框架内,成功地训练了第一个具有10亿个参数的ViT模型,该模型在各种下游任务上获得了最先进的性能,包括动作识别、空间动作检测和时间动作检测。
提出的方法
高效率是掩蔽自编码器的一个重要特性。VideoMAE采用非对称编码器-解码器架构,其中编码器的token序列长度仅为解码器的十分之一。这种较小的编码器输入有助于提高预训练的效率。然而,当将VideoMAE的深度和宽度(通道)扩展到十亿级模型时,总体计算和内存消耗仍然是当前可用的内存有限的GPU的瓶颈。因此,当前的非对称编码器-解码器架构需要进一步改进以缩放VideoMAE。
为了在有限的计算预算下更好地实现大规模的VideoMAE预训练,提出了一种双重掩蔽方案,以进一步提高其预训练效率。
VideoMAE的双重掩蔽
如图1所示,双重掩蔽方案使用两种不同的掩蔽生成策略和掩蔽比率生成两个掩蔽映射。这两个掩蔽映射分别用于编码器和解码器。与VideoMAE一样,编码器在编码器掩码下对部分可见token进行操作,并将观察到的token映射为潜在特征表示。但与VideoMAE不同的是,解码器从编码器的可见token和解码器掩码下可见的部分剩余token中获取输入。从这个意义上讲,使用解码器掩码来减少解码器输入长度,以实现更高的效率,同时获得与完全重建类似的效果。解码器将潜在特征和剩余的不完整token映射到相应位置的像素中。仅监督编码器不可见的解码器输出结果。
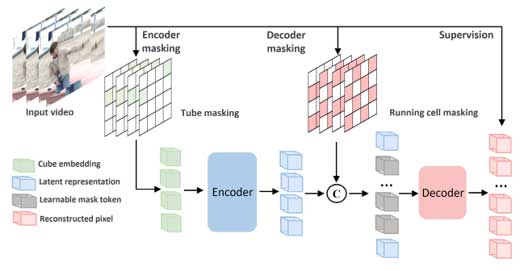
编码器掩蔽是具有极高比率的随机管道掩蔽,与原始VideoMAE相同。对于解码器掩蔽,想要达到的效果与编码器掩蔽相反。编码器中的管道掩蔽试图缓解由时间相关性引起的“信息泄漏”问题。在解码器掩蔽中,反而需要鼓励“信息互补”,以确保在这种部分重建中信息损失最小。从这个意义上说,需要选择尽可能多样化的立方体来覆盖整个视频。在实现中,比较了不同的掩蔽策略,并最终选择了运行单元掩蔽(如图1所示)。使用此解码器掩蔽,可以减少解码器的输入长度以提高计算效率。
对VideoMAE进行缩放
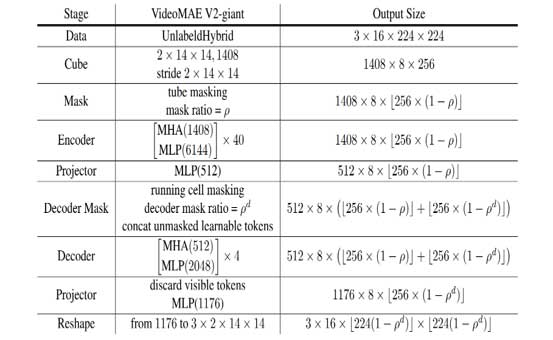
模型规模是获得卓越性能的主要影响因素。和最初的VideoMAE一样,由于其结构的简单性,使用ViT作为主干网络。根据ViT的缩放定律,构建了具有从ViT-B、ViT-L、ViT-H到ViT-g的不同容量主干网络的VideoMAE编码器。注意,ViT-g是一个具有十亿级参数的大型模型,从未在视频领域进行过探索。它在视频表示学习中的自监督学习性能仍然为社区所未知。对于解码器设计,使用相对较浅和较轻的主干,具有较少的层和通道。此外,应用双重掩蔽策略来进一步降低计算成本和内存消耗。关于解码器设计的更多细节可以在图2中看到。
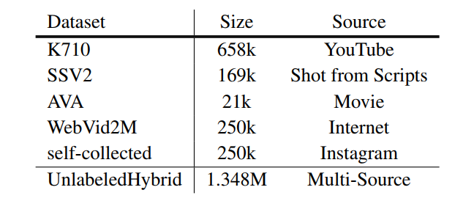
数据规模是影响VideoMAE预训练性能的另一个重要因素。最初的VideoMAE只是强调其数据使用效率,在相对较小的数据集上对ViT模型进行预训练。此外,需要对每个数据集使用单个模型进行预训练(即SomethingSomething和Kinetics数据集具有不同的预训练模型)。相比之下,现在的目标是学习一个通用的预训练模型,该模型可以转移到不同的下游任务。为此,需要将预训练视频样本增加到百万级大小,这一行为旨在了解VideoMAE预训练的数据缩放特性。数据多样性对于学习一般的视频表示非常重要。因此,构建了一个未标记的混合视频数据集,从Kinetics、SomethingSomething、AVA、WebVid等公共数据集收集视频,以及从Instagram上抓取视频。在未标记的混合数据集中,总共有135万个视屏片段。请注意,在这样大规模和多样化的数据集上对ViT进行预训练在以前的工作中是罕见的,并且数据规模和多样性对VideoMAE预训练的影响是未知的。关于混合数据集的构成,可以参见图3。
渐进式训练
模型迁移是使预训练的大型ViT适应下游任务的重要步骤。掩蔽自编码器预训练有望学习一些一般特征,并为ViT微调提供有利的初始化模型。原始VideoMAE仅在相应的监督下,直接在目标数据集上对预训练模型进行微调。由于监督的有限性,这种直接微调策略可能无法充分释放经过预训练的大型ViT的力量。相反,为了缓解过拟合风险,应该在多个阶段对来自多个来源的语义监督信号进行平衡化,以使预先训练的ViT逐渐适应下游任务。因此,在图像的中间微调技术提出之后,为十亿级ViT的整个训练过程设计了一个渐进式训练流程。首先,对未标记的混合视频数据集进行无监督的预训练和掩蔽自编码。然后,通过收集多个现有的监督数据集并将其标签对齐,构建一个有标记的混合数据集。在这个有标记的混合数据集上执行监督后预训练阶段,以将来自多个不同源的语义监督信号合并到先前预训练的ViT中。最后,针对目标数据集进行特定的微调,将一般的语义信息转移到以任务为中心的下游数据集中去。
实验结果
消融实验
首先对解码器掩蔽策略进行消融研究。使用ViT-B作为主干,并在SomethingSomething-V2数据集上进行预训练。以SomethingSomething-V2的微调结果进行评估,具体可见图4。首先在没有解码器屏蔽的情况下实现了原始的VideoMAE。然后,在解码器中尝试了两种掩蔽方案:帧掩蔽和随机掩蔽。对于帧掩蔽,只在解码器中重建一半的帧,而对于随机掩蔽,随机丢弃解码器中的一半token进行重建。这两种替代方案的性能比最初的VideoMAE差。最后,使用运行单元掩蔽来选择有代表性的token的子集进行重建。运行单元掩蔽方案与原始结果相当(70.28%和70.15%的准确率)。还消融了解码器的掩蔽比,50%的掩蔽比在准确性和效率之间保持了良好的平衡。
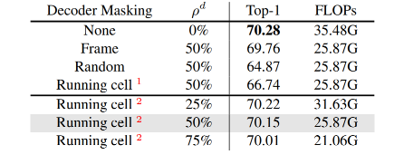
图5展示了双重掩码的计算成本、内存消耗和训练时间,并与原始的VideoMAE进行了比较。双重掩蔽可以进一步提高VideoMAE的计算效率,可以减少几乎一半的特征图内存,这对于在有限内存的GPU下预训练十亿级参数的ViT尤为重要。

模型和数据规模的影响
图6和图7展示了不同规模数据集和不同大小模型的性能表现。在这个实验中,在构建的约135万个视频的UnlabeledHybrid数据集上,用ViT-B、ViT-L、ViT-H到ViT-g的主干网络预训练视频模型。
结果表明,对于所有主干网络,在大规模数据集上预训练比在小规模数据集上预训练的原始VideoMAE获得更好的性能。同时,随着模型容量的增加,两个预训练数据集之间的性能差距变得更加明显。这意味着数据规模对于视频掩蔽自编码也很重要。随着模型容量的增加,获得了持续的性能改进。在所有比较的预训练方法中,从ViT-B到ViT-L的性能改进更明显,而从ViT-L到ViT-H的性能改进要小得多。进一步将模型容量扩展到ViT-g,仍然可以进一步提高微调性能。与图像中的结果一致,巨大模型和巨型模型(H与g)之间的性能差距非常小(0.1%-0.2%)。在不使用任何额外标记数据的情况下,K400和SS-V2的性能似乎分别在87.0和77.0左右饱和。


渐进式训练的结果
进一步比较了后预训练步骤对渐进训练方案的影响。为了减轻过拟合的风险,并将更多的人工监督标签集成到预先训练的视频模型中,合并了不同版本的Kinetics数据集进行后预训练(中间微调),并在Kinetics-400数据集上进行评估,结果如图8所示。观察到,后预训练提高了大规模预训练模型ViT-H和ViT-g的性能,这一结果与图像领域的研究结果一致。这种优越的性能可能归因于更大的无监督预训练数据集和更大的中间微调数据集。但在SS-V2数据集上尝试了这种后预训练方法,但模型的性能反而下降了。
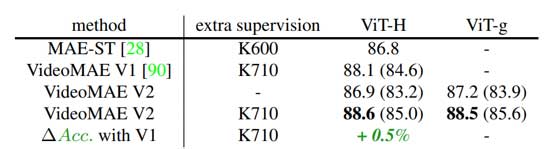
下游任务的表现
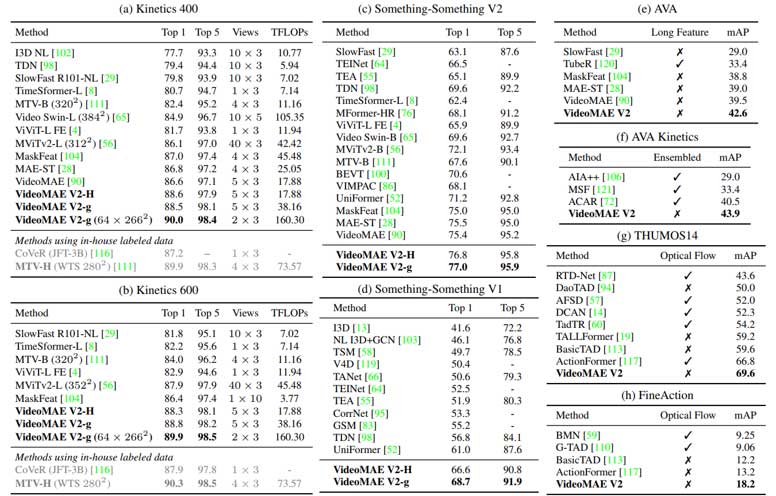
图9给出了模型迁移到不同下游任务后的性能表现。
总结
构建通用基础模型已被证明是提高人工智能任务性能的有效范例。简单和可扩展的算法是构建强大基础模型的核心。本文提出了一种在百万级数据集集上将VideoMAE扩展到十亿级模型的简单有效的预训练方法。得益于双重掩蔽的设计,成功地实现了第一个十亿级参数量的ViT,并在各种视频下游任务中展示了这种预训练方法的有效性。本文的结果表明,视频掩蔽自编码器是用于视频动作理解的通用且可扩展的表示学习器。希望预先训练的模型能够为未来更多的视频理解任务提供有效的视频表征。当前,预训练模型的挑战依然存在。观察到,当将VideoMAE从ViT-H扩展到ViT-g时,性能改进较小,部分原因是这些视频基准测试数据集的性能达到了饱和。然而,VideoMAE训练的数据规模仍然比图像和NLP小几个数量级。对于当前的软件和硬件来说,如何在数十亿视频数据上训练VideoMAE仍然极具挑战性,这需要制定更有效的视频预训练框架。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
