
因为最近做了一段时间的语音生成方向,期间也整理了一些开源项目和相关论文,每个或多或少都有可借鉴的地方,对于了解现阶段语音生成的相关技术还是比较有帮助的,后续也会根据自己的节奏来分享几篇论文或者开源项目。今天主要分享一下LauraGPT这篇文章。
作者:ctwgL
来源:音频探险记
原文:https://mp.weixin.qq.com/s/pwuR8cPdp4_K1Pvcrn_ZAw
语音生成整理
| model name | code | demo | |
| LauraGPT | https://arxiv.org/abs/2310.04673 | https://github.com/modelscope/FunCodec/tree/master/egs/LibriTTS | https://lauragpt.github.io/ |
| ChatTTS | – | https://github.com/2noise/ChatTTS | https://www.bilibili.com/video/BV1zn4y1o7iV/ |
| fishspeech | – | https://github.com/fishaudio/fish-speech | https://www.bilibili.com/video/BV1wz421B71D/ |
| vall-e系列 | https://www.microsoft.com/en-us/research/project/vall-e-x/ | https://github.com/lifeiteng/vall-e | https://www.microsoft.com/en-us/research/project/vall-e-x/vall-e/ |
| CosyVoice | https://fun-audio-llm.github.io/pdf/CosyVoice_v1.pdf | https://github.com/FunAudioLLM/CosyVoice | https://fun-audio-llm.github.io/ |
| Tortoise-TTS | https://arxiv.org/pdf/2305.07243 | https://github.com/neonbjb/tortoise-tts | https://nonint.com/static/tortoise_v2_examples.html |
| OpenVoice | https://arxiv.org/pdf/2312.01479 | https://github.com/myshell-ai/OpenVoice | https://research.myshell.ai/open-voice |
| Matcha-TTS | https://arxiv.org/pdf/2309.03199 | https://github.com/shivammehta25/Matcha-TTS | https://shivammehta25.github.io/Matcha-TTS/ |
| Mars5-TTS | https://github.com/Camb-ai/MARS5-TTS/blob/master/docs/architecture.md | https://github.com/Camb-ai/MARS5-TTS | https://6b1a3a8e53ae.ngrok.app/ |
| SeedTTS | https://arxiv.org/pdf/2406.02430 | – | https://bytedancespeech.github.io/seedtts_tech_report/ |
| Naturalspeech系列 | https://arxiv.org/pdf/2403.03100 | https://github.com/Plachtaa/FAcodec | https://speechresearch.github.io/naturalspeech3/ |
| fast-speech系列 | https://arxiv.org/abs/1905.09263 | https://github.com/xcmyz/FastSpeech | https://speechresearch.github.io/fastspeech/ |
| flashSpeech | https://arxiv.org/pdf/2404.14700 | – | https://flashspeech.github.io/ |
| baseTTS | https://arxiv.org/pdf/2402.08093 | – | https://www.amazon.science/base-tts-samples/ |
| MegaTTS2 | https://arxiv.org/pdf/2307.07218 | https://github.com/LSimon95/megatts2 | https://mega-tts.github.io/mega2_demo/ |
| PromptTTS2 | https://arxiv.org/pdf/2309.02285 | https://github.com/microsoft/NeuralSpeech/tree/master/PromptTTS2 | https://speechresearch.github.io/prompttts2/ |
| StyleTTS2 | https://arxiv.org/pdf/2306.07691 | https://github.com/yl4579/StyleTTS2 | https://styletts2.github.io/ |
| XTTS | https://arxiv.org/pdf/2406.04904 | https://github.com/coqui-ai/TTS/tree/main | https://edresson.github.io/XTTS/ |
| YourTTS | https://arxiv.org/pdf/2112.02418 | https://github.com/Edresson/YourTTS?tab=readme-ov-file | https://edresson.github.io/YourTTS/ |
| ControlSpeech | https://arxiv.org/pdf/2406.01205 | https://github.com/jishengpeng/ControlSpeech | https://controlspeech.github.io/ |
| DCTTS | https://arxiv.org/pdf/2309.06787 | – | https://github.com/lawtherWu/DCTTS/tree/main/samples |
| HamTTS | https://arxiv.org/pdf/2403.05989 | – | https://anonymous.4open.science/w/ham-tts/ |
| TextrolSpeech | https://arxiv.org/pdf/2308.14430 | https://github.com/jishengpeng/TextrolSpeech?tab=readme-ov-file | https://sall-e.github.io/ |
| MetaVoice-1B | – | https://github.com/metavoiceio/metavoice-src | https://colab.research.google.com/github/metavoiceio/metavoice-src/blob/main/colab_demo.ipynb |
| Parler-TTS | https://github.com/huggingface/parler-tts/blob/main/training/README.md#1-architecture | https://github.com/huggingface/parler-tts | https://www.text-description-to-speech.com/ |
LauraGPT
LauraGPT是阿里发表的一篇能够同时进行语音理解任务和语音生成任务的语音大模型,当时主要是对该论文进行了复现并进行了一些改进,然后完成了我们的第一版语音大模型,能够同时进行语音识别和语音生成,在语音识别和语音生成上的效果大致符合预期。LauraGpt的整体结构图如下:
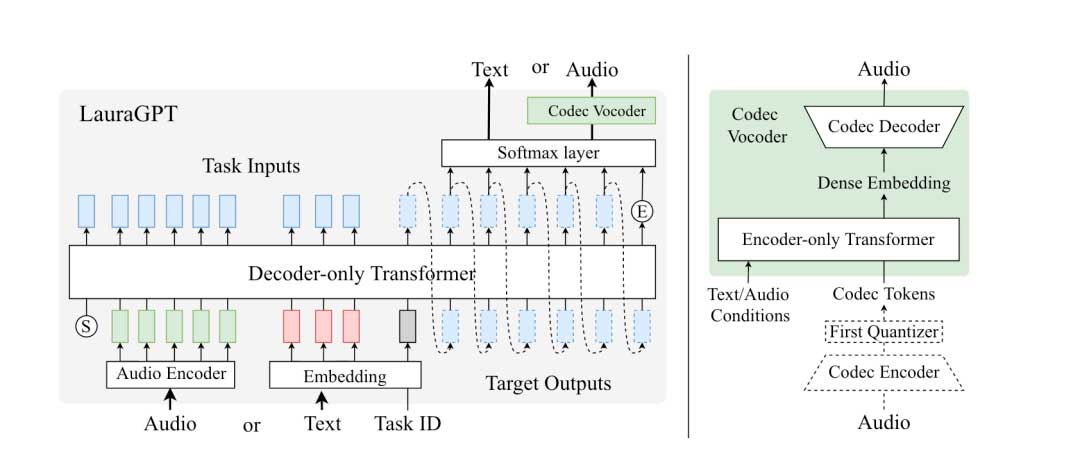

lauraGPT的输入格式需要满足如下的形式[input, task_id, output]。对于语音理解任务而言,它的形式是[audio_feature, task_id, text],其中task_id根据任务类型决定,比如语音识别,那么task_id就是ASR, 声音事件检测的话就是SED等等,根据自己实际情况指定。对于语音生成而言,它的形式就是[text, task_id, audio_token],其中audio token根据audio codec模型计算得到。语音理解任务整体相对较为简单,对此不再详细赘述,接下来重点说明语音生成任务。LauraGPT的语音生成部分分为两个:codec vocoder以及LLM部分,两个模块是单独训练的。而LauraTTS中是两个模块联合训练的,这里存在一定的区别。
codec vocoder
LauraGPT所使用的audio codec包含32个quantizer, 即32个码表,每个码表包含1024个audio token, 每个audio token对应的维度是128(类似于LLM中的token embedding 矩阵)。即一帧音频会离散化为32个token,第一个quantizer的token包含的信息最多,然后依次减少。考虑到LLM的自回归特性以及和语音理解任务形式上的统一,LLM只会生成第一个quantizer的audio token, 如果拿着该token输入到codec decoder中,那么恢复的语音就会有严重的信息丢失。与vall-e逐个预测剩余quantizer的token不同的是,lauraGPT引入了一个Encoder-Only Transformer模块去补偿这部分丢失的信息。
具体的方式是将audio codec第一个quantizer的audio token和text feature(text token对应的词向量)一起送入到Encoder-Only Transformers中,该模块会输出一个dense embedding, 其学习目标就是32个quantizer的audio token对应的token embedding进行求和得到的向量(该向量完整的表示了原音频信息)。两个dense embedding在训练中使用MSE loss进行约束。
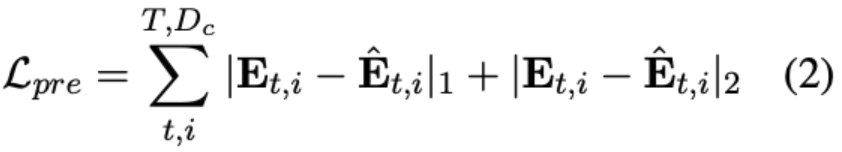
该模块单独训练完成后,然后就可以和LLM进行串联进行语音生成。
LLM模块
在该模块中主要建立文本和audio token之间的关系,对于一个文本-音频数据对,会先使用audio codec对其进行离散化,取第一个quantizer的输出作为音频的表征,建立<text token , audio token>的数据对。然后构造成上文所描述的输入形式送入到LLM中进行训练。训练过程与一般的LLM训练无异,采用交叉熵loss进行约束优化,至此模型的训练就全部完成了。
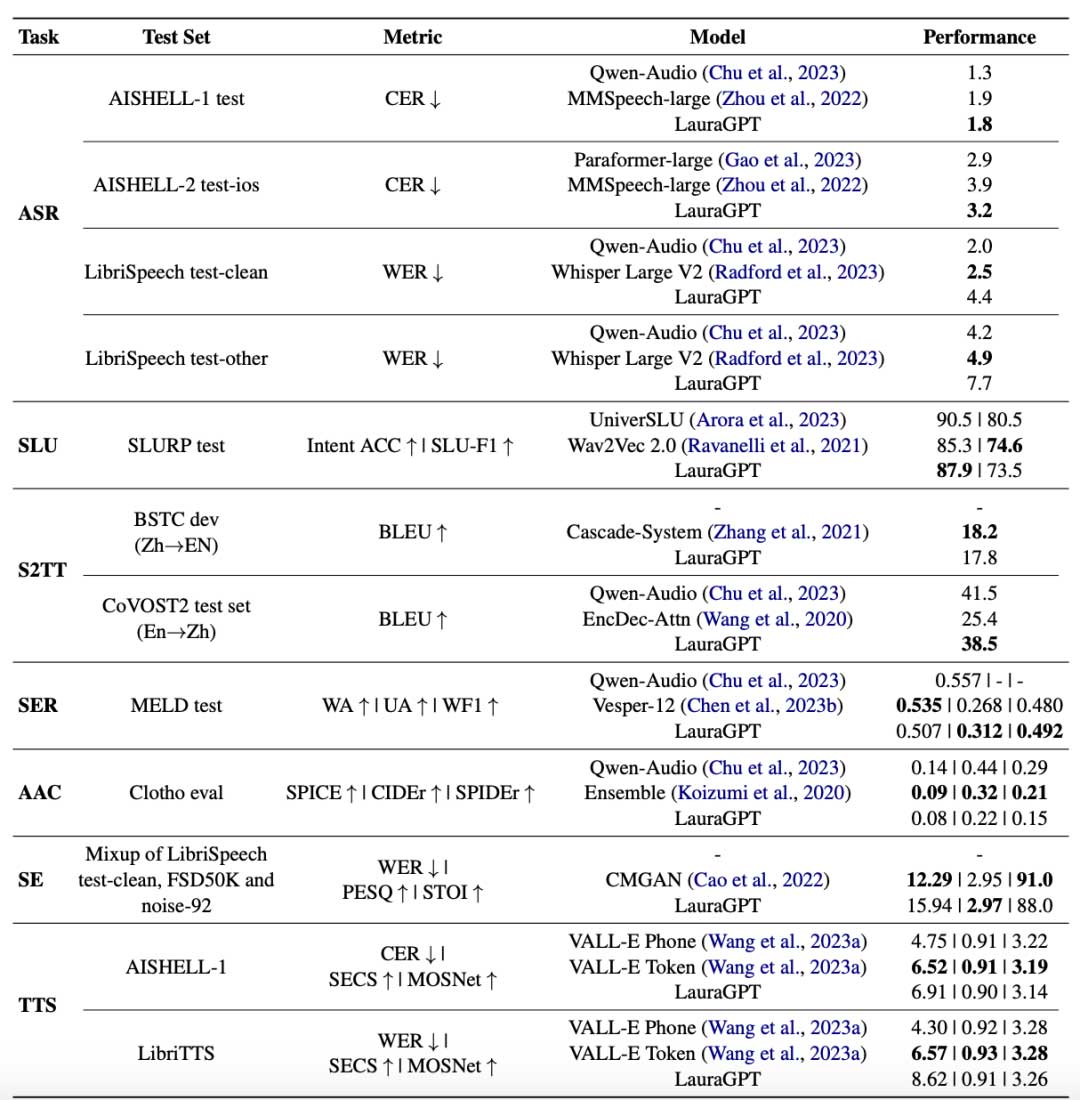
另外文章还论证了连续的特征输入相对于离散的特征输入而言,连续的特征的性能更好,因为连续特征所保留的信息多,这点主要是针对语音理解任务而言。这篇文章整体的结构还是比较清晰的,另外也在许多测试集上进行了指标的评测,某些数据集上的表现也展现了它的潜力。该文章对于想做语音理解和生成统一的大模型,有一定的借鉴意义。对于单纯的TTS而言,效果还是不太符合预期,从复现的结果来看,有时会出现不稳定的现象(掉字较为常见,可能是自回归模型的通病),导致计算得到的wer偏高,另外说话人相似程度大概六分像(主观感受上)。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。