
FunCodec是一个基础的神经语音编解码器工具包。FunCodec为最新的神经语音编解码器模型(如SoundStream和Encodec)提供可复制的训练配方和推理脚本。
题目:FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec
来源:Arxiv
论文:https://arxiv.org/abs/2309.07405
代码:https://github.com/modelscope/FunCodec
团队:阿里达摩院
内容整理:胡玥麟
动机与贡献
背景
- 语音编解码器的设计是为了有效地传输和存储语音信号。它们由一个编码器和一个解码器组成,编码器将语音编码成紧凑的表示,解码器重建信号。传统的语音编解码器依赖于精心设计的管道。funcodec该管道结合了语音合成的知识来实现高效的编码。
- 神经语音编解码器已经被引入,与传统的语音编解码器相比,表现出更好的性能。在神经编解码器模型中,原始波形被馈送到基于深度神经网络的编码器中以提取紧凑的表示。然后是残差矢量量化器(RVQ),以获得并行token流。同时,基于神经网络的解码器也与编码器和RVQ一起训练以重建信号。基于文本到语音合成的进展,采用对抗性训练损失来提高重建质量。
提出方法
整体架构
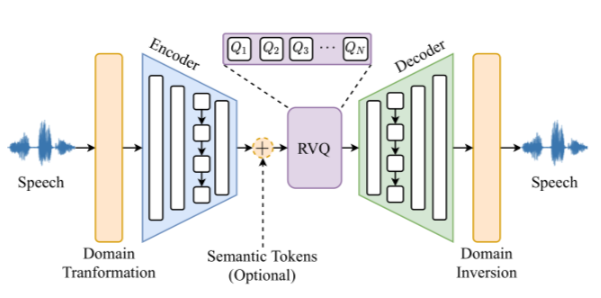
FunCodec模型的体系结构如图所示。给定一个语音信号,它通过域变换模块。对于像SoundStream和Encodec这样的时域模型,该模块的功能是标识映射。
编码器网络架构
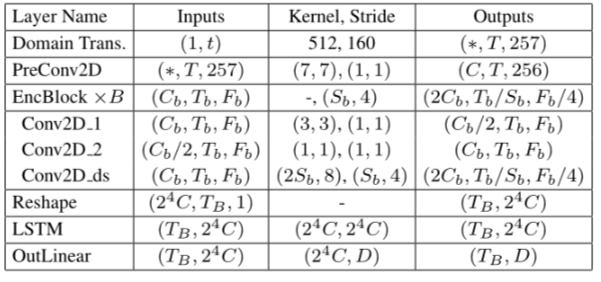
FreqCodec的编码器架构细节如图所示。Sb和Cb表示EncBlock的步幅和过滤器。
RVQ架构
为了获得离散的语音标记,项目使用了一个残差矢量量化(RVQ)模块,该模块由几个量化器组成:
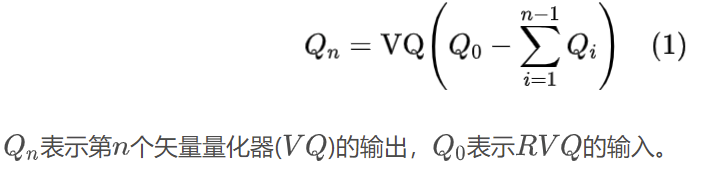
Adversarial training objective with multiple discriminators(具有多鉴别器的对抗性训练目标)
训练目标由三个部分组成:重建损失项、对抗损失项和RVQ的损失。
重建损失
在时域上最小化原始x与重构语音之间的L1距离(recon_loss):
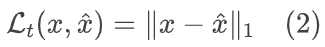
频域loss(multi_spectral_recon_loss)
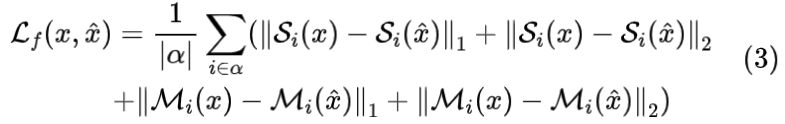
Si和Mi分别表示对数压缩功率和STFT的Mel频谱,α被设置为[5,6,…11]。
RVQ loss
Commit loss
commit loss考虑了整个RVQ模块和子量化器的量化误差。V表示RVQ的输入。
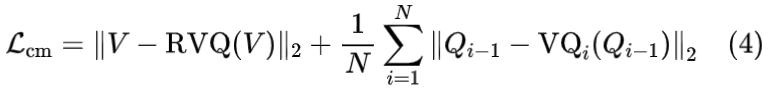
Discriminator loss
对抗性损失(adversarial_loss和feat_match_loss)Dk,t表示鉴别器k在时间步长t处的输出,D(l)表示第1层的输出。
总损失
将所有单个损失项相加得到总的训练目标:
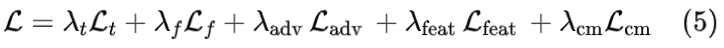
训练
数据集用LibriTTS数据集进行训练。 评分使用虚拟语音质量客观听者评分(Virtual Speech Quality Objective Listener score, ViSQOL)作为主要评价指标,评分范围从1到5,分数越高质量越好。
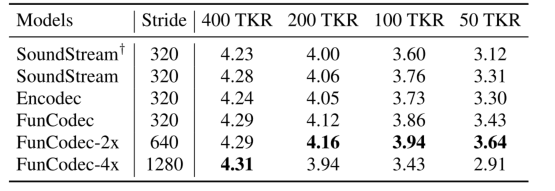
实验结果见下表。从表中可以观察到,复制的SoundStream和Encodec模型在不同的token速率下实现了最先进的性能,证实了我们实现的准确性。包含对数压缩的功率谱损失可以持续改善语音质量,特别是在较低的token速率下。在FunCodec的基础上,我们提出了两倍和四倍长的低帧率模型,分别产生了FunCodec-2x和FunCodec-4x。我们发现FunCodec-2x实现了更高的ViSQOL分数,而FunCodec-4x在较低的token速率下表现出性能下降。这表明将帧率降低两倍在时间和量化分辨率之间取得了良好的平衡。
实验
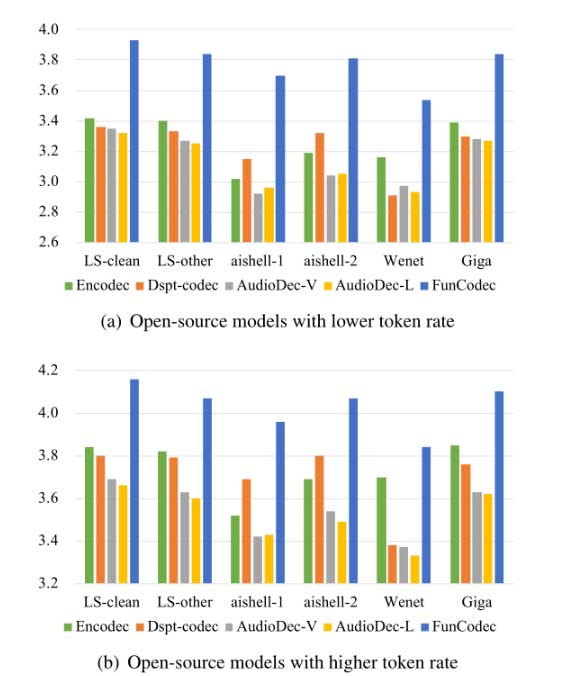
为了确保与其他开源模型的兼容性,测试文件被重新采样以匹配所需的采样率。此外,为了进行公平的比较,还根据工作采样率对token率进行了规范化。下图显示了开源模型在不同token速率下的结果,其中较低和较高的token速率分别对应于每16k波形样本生成100和200个token。据观察,较高的token率始终能提高压缩质量。与其他开源模型相比,模型在相同的token速率下对英语和汉语语音都表现出更好的质量。然而,令我们惊讶的是,所有模型在Wenet测试集上的表现都很差。这可以归因于Wenet语料库是在复杂的声学环境中记录的,并且包含更高程度的非语音噪声。
下图是(a)较低和(b)较高token率下开源广义模型的比较。LS表示librisspeech测试集。librisspeech和gigasspeech是英语语料库,aishell和Wenet是汉语语料库。
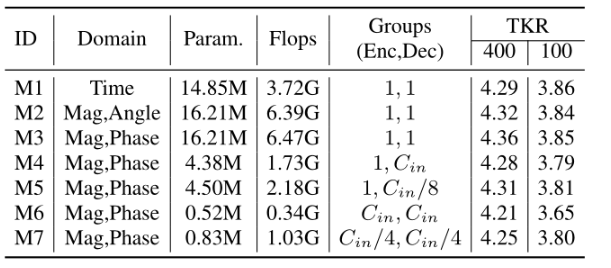
下表是FreqCodec与其他时域模型在LibriTTS上的ViSQOL评分比较。Mag表示幅度谱图。Cin表示输入的通道数。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
