
从多视图视频重建动态场景的逼真自由视点视频 (FVV) 是一项具有挑战性的工作。尽管当前的神经渲染技术取得了显着的进步,但这些方法通常需要完整的视频序列进行离线训练,并且不能进行实时渲染。为了解决这些问题,作者引入了一种为真实动态场景的高效 FVV 流式传输而设计的方法 3DGStream 。该方法实现了每帧 12 秒的快速重建和 200 FPS 的实时渲染。具体来说,作者利用 3D 高斯 (3DG) 来构建三维场景。作者没有采用直接优化每帧 3DG 的简单方法,而是采用紧凑的神经变换缓存(NTC)来建模 3DG 的平移和旋转,显着减少了每帧所需的训练时间和存储空间。此外,作者提出了一种自适应 3DG 添加策略来处理动态场景中的新对象。实验表明,与当前方法相比,3DGStream 在渲染速度、图像质量、训练时间和模型存储方面实现了优越的性能。
作者:Jiakai Sun, Han Jiao, Guangyuan Li, Zhanjie Zhang, Lei Zhao, Wei Xing
来源:CVPR 2024 Highlight
论文题目:3DGStream: On-the-fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos
论文链接:https://arxiv.org/abs/2403.01444
内容整理:梁焕雄
引言

从多个视角捕获的视频构建自由视点视频(FVV)是计算机视觉和图形领域的前沿挑战。近年来,神经辐射场(NeRFs)由于其三维体积表征的强大能力而引起了广泛关注。一系列基于 NeRF 的方法进一步推动了在动态场景上构建 FVV 的发展。尽管如此,绝大多数基于 NeRF 的 FVV 构建方法都遇到了两个主要限制:(1)它们通常需要完整的视频序列来进行耗时的离线训练,这意味着它们可以无法进行流式传输, (2)它们普遍无法实现实时渲染,从而阻碍了实际应用。
最近,Kerbl 等人使用 3D 高斯 (3DG) 实现了实时辐射场渲染,只需几分钟的训练即可在静态场景中即时合成新颖的视图。受其启发,作者提出了一种利用 3DG 构建动态场景的自由视点视频(FVV)的方法 3DGStream。具体来说,首先在第 0 帧的多视图帧上训练得到初始 3DG。然后,对于每一帧 i,使用前一帧 i-1 的 3DG 作为初始化,并将其进行两阶段的训练。(1) 在第 1 阶段,训练神经变换缓存 (NTC) 来建模 3DG 的变换。(2) 在第 2 阶段,使用自适应 3DG 添加策略来处理新对象,即在新对象附近生成特定于帧的附加 3DG,并通过定期分割和修剪对其进行优化。训练结束后,使用 NTC 转换的 3DG 和附加 3DG 在当前帧 i 进行渲染,只有前者用于后续帧的初始化。这种设计显着降低了 FVV 的存储要求。
方法
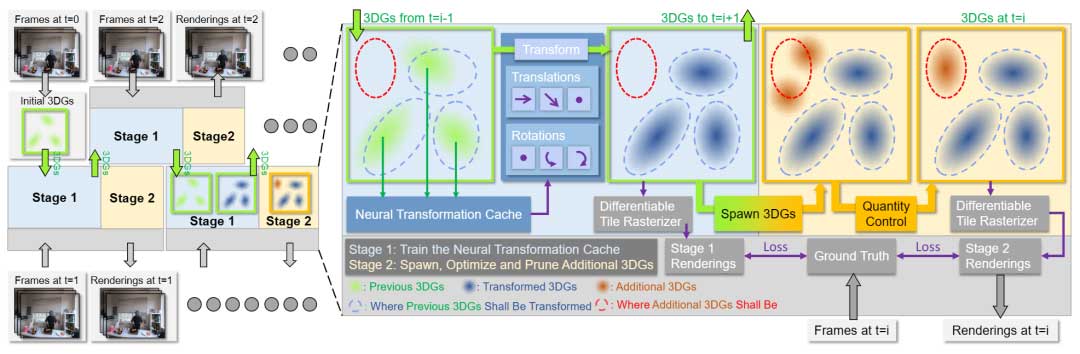
3DGStream 通过逐帧训练从动态多视图视频流构建 FVV 流。作者通过训练 3DG 来重建帧为 0 的场景。对于后续帧,采用前一帧的 3DG 作为初始化,并将它们进行两阶段的训练。首先训练神经变换缓存(NTC)来对每个 3DG 的变换进行建模。然后,将转换后的 3DG 带到下一帧。其次采用自适应 3DG 添加策略来处理新兴对象。对于每个 FVV 帧,使用变换后的 3DG 和附加 3DG 在当前帧渲染视图,而后者不会传递到下一个帧。
神经变换缓存(NTC)

此外,为了以最小的开销增强 NTC 的性能,作者利用高度优化的浅层 MLP,将哈希编码映射到 7 维输出:前三个维度表示 3DG 的平移;其余维度表示使用四元数的 3DG 旋转。考虑到多分辨率哈希编码与 MLP 相结合,我们的 NTC 被形式化为:
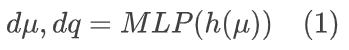
其中 μ 表示输入 3DG 的位置均值。根据 dμ 和 dp 变换 3DG,变换后的 3DG 可以表示为:
- 位置均值:μ‘ = μ +dμ,其中 μ‘ 表示 3DG 新的位置。
- 旋转:q’ = norm(q) x norm(dq),其中 q’ 表示新的旋转四元数,x 表示四元数乘法,norm 表示归一化。
- SH 系数:旋转 3DG 时,还应调整 SH 系数与 3DG 的旋转保持一致。利用SH的旋转不变性,直接使用SH旋转来更新SH。
在第 1 阶段,通过 NTC 转换前一帧的 3DG,然后使用它们进行渲染。NTC 的参数通过渲染图像和真实图像之间的损失进行优化。根据 3DG-S,损失函数是 L1 与 D-SSIM 项的组合:
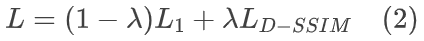
其中,在所有实验中 λ = 0.2。应该注意的是,在训练过程中,前一帧的 3DG 保持不变,不会进行任何更新,这意味着 NTC 的输入保持一致。
此外,为了确保训练稳定性,使用预热参数初始化 NTC。预热期间使用的损耗定义为:
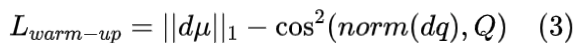
其中,Q 是单位四元数。第一项使用 L1 范数确保估计的平移接近0,而第二项利用余弦相似性确保估计的旋转近似于无旋转。然而,考虑到单位四元数的双重覆盖特性,对于每个场景,仅在帧为 0 的训练之后执行预热,使用初始 3DG 的噪声增强方法作为输入。经过 3000 次训练迭代(大约 20 秒)后,参数被存储并用于初始化所有以下帧的 NTC。
自适应 3DG 添加策略
仅依靠 3DG 变换就足以重建真实动态场景的很大一部分,并且平移可以有效地重建后续帧中物体的遮挡和消失。然而,当面对初始帧中不存在的对象时,例如火焰或烟雾等瞬态对象,以及从瓶子中倒出的液体等新对象,这种变换方法就会失效。由于 3DG 是一种非结构化的显式表示,因此必须添加新的 3DG 来对这些新兴对象进行建模。
首先,需要确定新物体的位置。受 3DG-S 的启发,3DG 的视空间位置梯度是一个关键指标。对于新物体,邻近的 3DG 表现出较大的视图空间位置梯度。因此在这些高梯度区域周围引入额外的 3DG 是适当的。此外,为了彻底捕获新对象可能出现的每个潜在位置,作者采用了自适应 3DG 生成策略。具体来说,在第 1 阶段的最后一个训练时期跟踪视图空间位置梯度。此阶段结束后,选择视图空间位置梯度的平均大小超过相对较低阈值 τgrad = 0.00015 的 3DG。对于每个选定的 3DG,新 3DG 的位置从 X ~ N(μ,2Σ) 中采样,其中 μ 和 Σ 是选定 3DG 的平均值和协方差矩阵。新 3DG 的 SH 系数和缩放向量的不正确初始化往往会导致优化偏向降低不透明度而不是调整这些参数,这会导致新 3DG 快速变得透明,从而无法重建新对象。为了解决这些问题,这些新 3DG 的 SH 系数和缩放向量将继承原始的 3DG,旋转参数则设置为恒等四元数 q =[1,0,0,0] ,不透明度初始化为0.1,生成后,3DG 使用与阶段 1 相同的损失函数进行优化。
为了防止局部最小值并控制新 3DG 的数量,作者实施了自适应 3DG 数量控制策略。具体来说,在第 2 阶段,为不透明度值设置了一个相对较高的阈值 τα = 0.01。在每个训练周期结束时,对于视空间位置梯度超过 τgrad 的 3DG,在附近生成新的 3DG 以解决重建不足的区域。这些新的 3DG 继承了原始 3DG 的旋转和 SH 系数,它们的缩放比例调整为原始的 80%,随后丢弃任何不透明度值低于 τα 的附加 3DG,以抑制 3DG 数量的增长。
实验结果
数据集
作者对两个真实世界的动态场景数据集进行了实验:N3DV 数据集和 Meet Room 数据集。N3DV 数据集是使用21个摄像机的多视图系统捕获的,视频为 2704 x 2028 的分辨率和 30 FPS的帧率。Meet Room 数据集是使用13摄像头多视图系统捕获的,视频为 1280 x 720 的分辨率和30 FPS的帧率。
对比实验
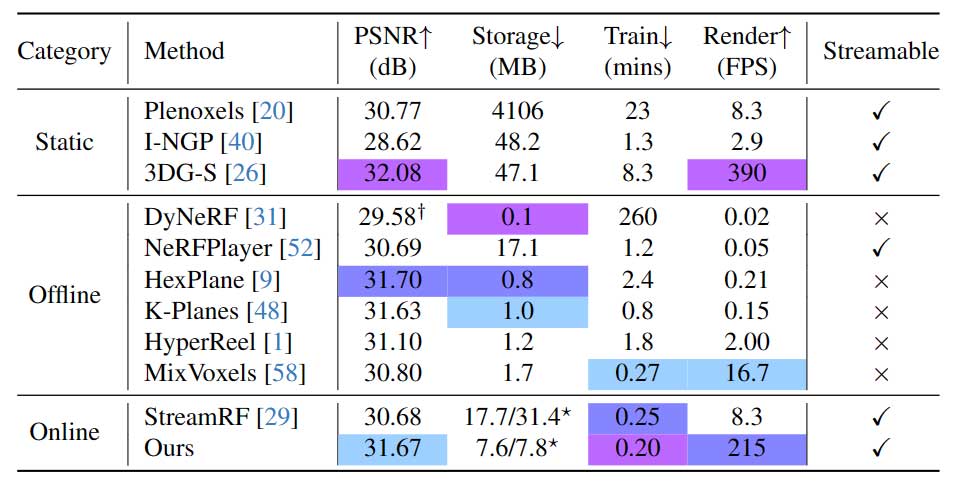
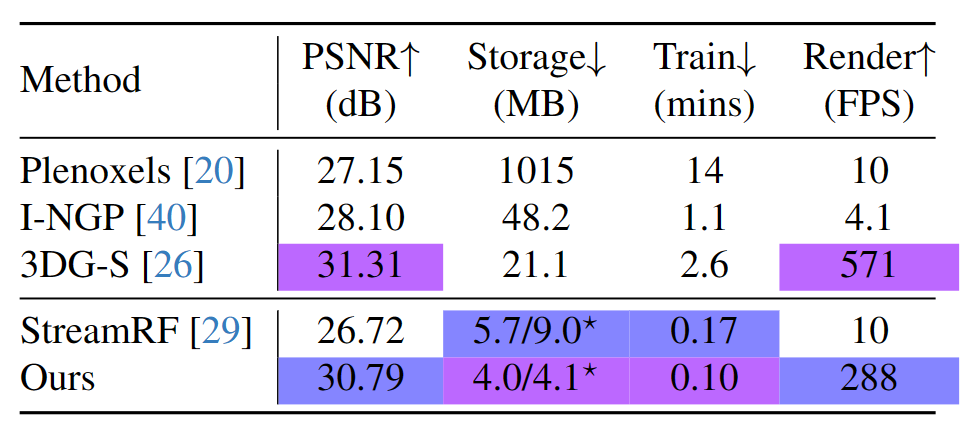
定量比较:以Plenoxels、I-NGP 和 3DG-S 作为快速静态场景重建方法的代表,对每一帧从头开始训练它们。StreamRF 、Dynamic3DG 和 ReRF 用于动态场景的在线训练。作者选择 StreamRF 作为在线训练方法的代表。表 1 展示了 N3DV 数据集所有场景的平均渲染速度、训练时间、存储空间和 PSNR。对于每个场景,后三个指标计算 300 帧的平均值。为了证明方法的通用性,与 StreamRF、Plenoxels、I-NGP、3DG-S 和 StreamRF 进行了定量比较。结果如表 2 所示。如表 1 和表 2 所示,3DGStream在训练和实时渲染上展示了优越的性能。

定性比较:在图 4 中,对 N3DV 数据集 和 Meet Room 数据集上的场景与 I-NGP、HyperReel 和 StreamRF 进行了定性比较,其中特别强调动态物体,如脸部、手和钳子,以及复杂的物体,如标签和雕像。显然,3DGStream 捕捉到了场景的动态,且没有牺牲重建复杂对象的能力。
消融实验
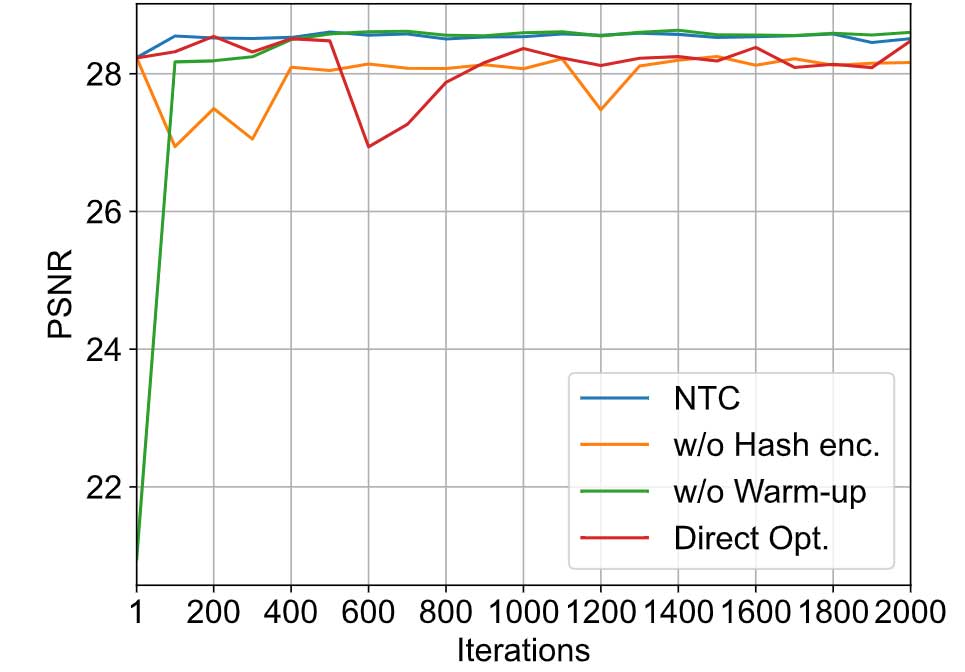
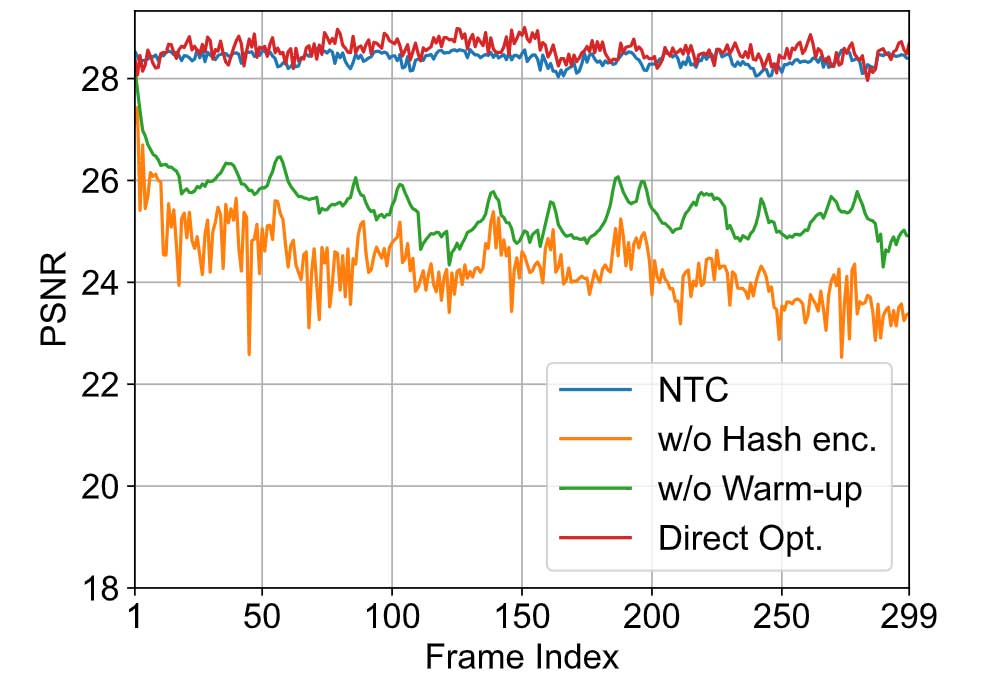
神经变换缓存:利用不同的方法对 N3DV 数据集的 flame steak 视频中从第一帧到第二帧的 3DG 转换进行建模,以显示 NTC 的有效性。如图 4 显示,如果没有多分辨率哈希编码(w/o Hash enc.),MLP 在有效建模转换方面面临挑战。此外,如果没有预热(w/o Warm-up),则需要更多迭代才能收敛。同时,即使与前一帧的 3DG(Direct Opt.)的直接优化相比,NTC 也表现出了同等的性能。图 6 展示了在 flame steak 视频中应用不同方法的结果.相比之下,利用 NTC 无需保存所有 3DG,并且可以渲染得到较高质量的新颖视图,同时显着降低存储开销。
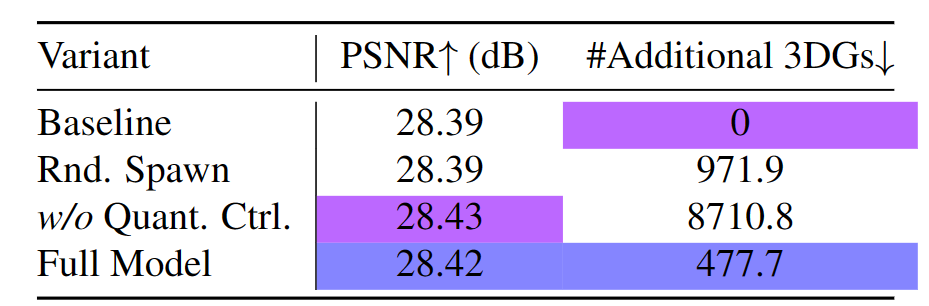
自适应 3DG 添加策略:表3 呈现了在 flame steak 场景上进行的消融研究的定量结果。相比之下,完整模型使用最少的 3DG 添加来重建新兴对象。
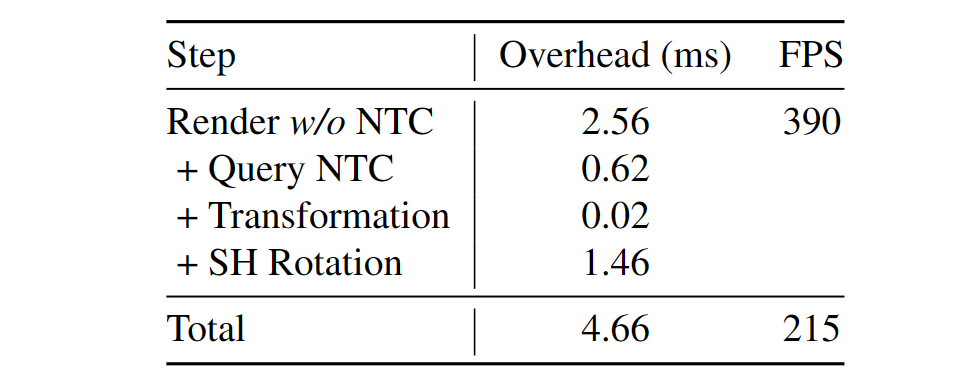
实时渲染:按照 3DG-S ,采用用 SIBR 框架测量渲染速度。该方法的额外开销主要是查询 NTC 和转换 3DG 所花费的时间。如表 4 所示,3DGStream 受益于多分辨率哈希编码的效率和全融合MLP,这有助于快速NTC查询。值得注意的是,最耗时的步骤是 SH 旋转。然而,实验表明 SH 旋转对重建质量的影响最小,这可能是归因于 3DG 通过替代机制(例如,围绕对象的不同颜色的小型 3DG)而不是 SH 系数来建模依赖于视图的颜色。
总结
作者提出了 3DGStream,一种新颖的方法用于高效的自由视角视频流。基于 3DG-S ,作者利用有效的神经变换缓存来捕获对象的运动。此外,作者提出了一种自适应 3DG 加法策略,可以准确地对动态场景中的新兴对象进行建模。3DGStream 的双阶段训练支持视频流中动态场景的动态重建。在确保照片级真实感图像质量的同时,3DGStream 还可以通过适度的必要存储实现百万像素分辨率的即时训练(每帧约 10 秒)和实时渲染(约 200FPS)。大量实验证明了 3DGStream 的效率和有效性。但是 3DG-S 初始帧的质量对于 3DGStream 至关重要。因此,该方法继承了 3DGS-S 的局限性,例如对初始点云的高度依赖。因此,该方法将直接受益于未来 3DG-S 的增强改进。此外,为了高效的即时训练,作者限制了训练迭代的次数,这限制了阶段 1 中剧烈运动和阶段 2 中复杂新对象的建模。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
