
本文是由上海交通大学宋利教授带领的 MediaLab 实验室最新发表在 IBC 2022 的工作,该工作提出了一种具有灵活虚拟访问模式的超低比特率视频会议系统,实验证明了所提出系统的良好率失真性能和实时性。
来源:IBC2022
论文标题:AN ULTRA-LOW BITRATE VIDEO CONFERENCING SYSTEM WITH FLEXIBLE VIRTUAL ACCESS PATTERNS
论文作者:Jun Xu, Zhiyu Zhang, Jun Ling, Haoyong Li, Bingcong Lu, Li Song
论文链接:https://www.ibc.org/technical-papers/ibc2022-tech-papers-an-ultra-low-bitrate-video-conferencing-system-with-flexible-virtual-access-patterns/9237.article
对远程工作和在线娱乐的需求每年都在激增,这对视频会议等应用程序的带宽使用和体验质量提出了更高的挑战。传统视频会议系统中的视频编解码器通常使用基于块的混合编码架构,在这些场景中,这种架构通常没有最优的率失真性能和计算资源消耗。此外,在低带宽网络的低比特率场景下,传统编解码器可能会导致不好的体验。在本文中,我们提出了一种具有灵活虚拟访问模式的超低比特率视频会议系统。传统的视频编解码器被部分或全部替换,以获得超低比特率,同时确保流畅的通信体验。此外,人脸编码、现实和虚拟化身这三种访问模式,可以通过视频或音频模式驱动,生成不同种类的视频,提供未来可能的视频会议范式。摄像头拍摄的视频不一定会传输,以保护用户隐私。实验证明了所提出系统的良好率失真性能和实时性。
介绍
自 2020 年新冠疫情出现以来,从远程协作到在线娱乐,行业和学术界在消费增加和创新加速方面都出现了大幅增长。虽然对视频会议和现场娱乐的需求激增带来了巨大的机会,但它也对带宽提出了巨大的需求。传统视频系统通常使用基于块的混合编码方案对捕获的视频进行编码,该方案通用且稳定。然而,对于某些特定场景,例如视频会议或直播中的虚拟化身,基于块的编码方案不足以减少语义冗余。我们有以下发现和分析:
(1)在视频会议场景中,要编码的视频主要是固定背景下的说话人脸。通用视频编码方案,如高效视频编码 (HEVC/H.265)、多功能视频编码 (VVC/H.266) 和 AV1,为任何视频设计,并专注于恢复像素级保真度。然而,我们认为通用编解码器在视频场景中是次优的,原因如下:首先,视频会议中的人脸背景图像往往是静态的,保持不变,而观众在会议期间将注意力集中在人脸区域。其次,人脸通常具有相似的结构和语义含义(例如,眼睛、嘴巴和鼻子等),这提供了通过从人脸数据集中学习先验,然后从较少语义信息中恢复人脸细节的机会。最近,深度学习方法具有基于少量信息的生成能力,在人脸视频压缩方面很有潜力。这些方法通常使用一些稀疏表示(如关键点)代替部分或全部视频帧,并使用深度学习技术在渲染前恢复这些帧。在工业领域,NVIDIA 还发布了用于与人工智能进行音频和视频通信的平台和套件,例如 NVIDIA Maxine,其中的 AI 视频压缩解决方案可以在发送端传输面部的关键点,并在接收端使用 AI 方法生成重建。
(2)随着动漫产业在市场上的大幅增长,虚拟 YouTuber(VTuber)也迅速增长。许多 VTuber 在直播市场上展现了自己的商业价值,在 YouTube、Niconico、Bilibili 等众多社交平台上拥有大量粉丝。除了直播之外,使用虚拟化身参加视频会议正在成为一种新趋势。标准化组织也注意到了这种趋势。MPAI 发布了第二版多模态对话 (MPAI-MMC) 标准,其中一个用例是基于化身的视频会议 (ABV)。虚拟视频会议和直播中要编码的视频只是一个虚拟化身在固定的场景中做轻微的动作,这与视频会议场景类似。此外,虚拟化身本身是由从人类演员中提取的一些关键点驱动的,与编码视频帧相比,这可能只需更少的数据量。因此,在客户端传输关键点并实时渲染它们可能是减少带宽消耗的一种有吸引力的解决方案。
(3)随着元宇宙等新概念的兴起,除了人脸编码、虚拟化身,逼真的化身也是未来视频会议中用户真实面孔的可能替代品。在这种情况下,会议系统允许用户通过他的实时面部动态和音频来驱动任何预定义的化身或他自己的面部图像。为了实现各种访问模式,我们提出了一种在视频会议系统中进行逼真面部渲染的有效方法。提出的方法是利用摄像机捕获的视频或麦克风的音频信号来合成逼真的通话人脸视频。值得一提的是,视觉信号或音频信号的两种形式都是可以接受的。通过提出的工作流,人们可以用声音加入会议并传输合成的视频,这消除了实时摄像机录制的必要性,并确保用户隐私不受侵犯。
为了克服上述场景下传统编码方案的次优性,探索新的娱乐形式,本文提出了一种具有多种虚拟访问模式的超低码率视频会议系统。本文结合人脸视频压缩、虚拟化身和逼真人脸生成方法与实时通信(Real Time Communication, RTC)的最新进展,提供了一种实用的视频会议系统。本文的主要贡献如下:
- 本文将人脸视频压缩、虚拟化身和逼真的人脸渲染与 RTC 相结合。我们进行了新颖的尝试,以探索视频会议系统的新范式。
- 在超低码率约束下,所提出的视频会议系统比传统视频编解码方案提供了可接受的更好结果,满足了带宽受限的网络环境下实时通信的需求。
- 我们开发的原型系统已准备好进行实际部署,并将很快在https://github.com/sjtu-medialab/virtualConference 开源。
相关工作
视频会议与协议
自新冠疫情以来,RTC 的需求应用程序迅速增加。特别是,在线视频会议成为最多的人们交流、工作和学习的重要方式。用户可以访问视频会议系统有多种方式,如移动设备、个人电脑、房间等系统。而随着应用规模的扩大和计算压力的产生通过先进的功能,大多数系统提供基于云的服务,而不是传统的有线电视系统。从多媒体技术的角度来看,视频会议系统通过视频实现了音频、视频和内容的无缝交换音视频编码、质量优化、加密、传输等诸多方面模块。为了在复杂网络环境中实现良好的体验质量 QoE,视频会议系统对时延和带宽利用率有严格的要求。因此,传输方案,特别是协议的选择至关重要。
TCP 和 UDP 是应用最广泛的两种传输层协议。而对于视频会议系统来说,及时性比可靠性更重要。因此,虽然 TCP 可以保证有序、可靠的传输,但其由开始前的握手引起的高延迟和简单的重传方案使 TCP 被 RTC 应用程序淘汰。大多数现代视频会议系统,如基于 WebRTC 的,通常应用基于 UDP 的协议:RTP 及其变体 SRTP。据报道,作为视频会议行业的代表企业,Zoom 提出了 RTP 的自定义扩展[1]。
最近,另一种基于 UDP 的协议 QUIC 因其优异的性能和高灵活性引起了广泛关注。QUIC 只需要一个 RTT 就可以建立可靠安全的连接,这比 TCP 的三次握手要高效得多。而且,QUIC 具有处理流复用和连接迁移的能力,这进一步提高了不稳定环境下的传输性能。此外,QUIC 具有可插拔的拥塞控制模块,这使得拥塞控制算法的升级非常方便。QUIC 很有前景,将其应用于实时视频流媒体的研究很多,如 RTP over QUIC [2] 及 QUIC 不可靠传输的扩展[3]。
人脸编码
传统的视频编码技术利用一些人工设计的方案来消除冗余信息。基于混合视频压缩框架,许多传统的视频编码方法被提出,如 HEVC 和 VVC。而且,VVC 代表了最先进的常规方法。
随着深度学习技术的发展,许多生成方法实现了在谈话人脸生成方面取得了相当大的进步,可应用于谈话人脸视频压缩。Feng [4] 等提出了一种基于 FSGAN[5] 实现了大约 1 KB/s 的低比特率。FOMM [6] 使用关键点和 Jacobian 行列式表示稀疏运动,然后用于驱动谈话人脸。省略雅可比行列式,Tang [7] 等仅依靠关键点来表征运动并提出一种用于人脸视频的混合压缩方案,可实现更好的质量和更低的比特率。Oquab [8] 等设计了一种基于 FOMM 的可移动架构,同时质量可能并不令人满意。结合 3D 信息,Wang [9] 等提出了一个框架可以生成自由视图的说话人脸视频,而训练过程比较困难,消耗大量时间和计算资源。基于 FOMM,Konuko [10] 等利用一个原始帧作为参考帧并将生成的帧添加到参考帧池,这可能会导致错误累积。
逼真的谈话人脸生成
逼真的谈话人脸生成旨在生成与输入条件匹配的谈话人脸,包括音频、面部标志、分割图或文本。在过去的几年里,已经提出了很多方法来实现逼真的谈话人脸生成。一种方法使用音频作为输入来合成面部视频。Guo [11] 等提出了一种基于 NeRF 的方法,该方法采用音频语音和面部参数作为输入来生成说话的面部。然而,NeRF 适用于静态场景建模,但无法处理谈话视频中的动态运动。因此,其合成的视频存在抖动问题。Thies [12] 等提出从音频特征中估计表达,并使用简单的 U-Net 从神经纹理中渲染照片般逼真的特征。Wav2Lip [13] 从音频和背景图像合成嘴唇。在使用文本、面部标志或分割图作为输入来生成目标面部图像的方法的另一个分支上。Chen [14] 回归面部地标以渲染面部图像。Xue [15] 等提出采用人脸分割图来驱动人脸图像。然而,这种方法的重建质量在很大程度上取决于分割的准确性,对于真实的谈话人脸生成并不实用。基于文本的方法 [16] 生成带有文本输入的谈话视频。然而,为了弥合文本和图像之间的差距,需要在数十小时的单人训练视频中优化渲染器。
音频编码
传统的音频编解码器结合了线性预测技术和改进的离散余弦变换等传统编码工具,在不同的内容类型、比特率和采样率上提供高编码效率,同时确保实时音频通信的低延迟。Opus [17]、EVS [18] 和 USAC [19] 是 SOTA 传统音频编解码器。
端到端神经音频编解码器依赖于数据驱动的方法来学习有效的音频表示,而不是依赖于手工制作的信号处理组件。Lyra [20] 是一种生成模型,它对语音的量化的 mel-spectrogram 特征进行编码,这些特征通过自回归 WaveGRU 模型进行解码,以 3kbps 的码率获得了令人印象深刻的结果。SoundStream [21] 是一种新颖的神经音频编解码器,它依赖于由全卷积编码器/解码器网络和残差矢量量化器组成的模型架构,它们被联合端到端训练,它在所有比特率下都实现了 SOTA 结果。
系统架构
概述
提出的系统提供了三种访问模式,分别是人脸编码、虚拟化身和逼真化身。这三个工作流共享一个相似的系统架构,但是每个模块的处理方式和数据流不同
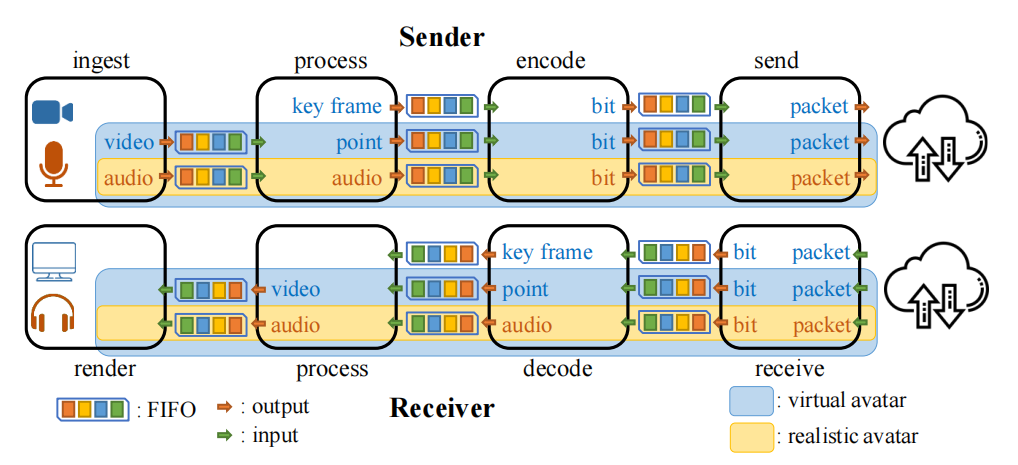
系统架构如图 1 所示,这实际上是人脸编码工作流的系统架构。系统中有三个数据流,关键帧、点和音频。这三个数据流都用在人脸编码工作流中。后两者用于虚拟化身工作流,而逼真化身工作流可以只需音频流,如图 1 中蓝色和黄色框所示。
模块之间通过一些 FIFO 相互连接,数据在 FIFO 中流动。为了清晰的表示,不同的数据流在图中使用不同的 FIFO,这在实际系统中并不是必要的情况。
人脸编码工作流程
人脸编码工作流提供了与传统视频会议类似的体验,但由于基于生成的人脸编码方案,在相同质量的情况下,大大节省了比特率。
摄取和呈现
发送端中的摄取模块负责与摄像头和麦克风交互,获取视频和音频数据。然后将数据以帧的形式放入 FIFO 并传递给后续模块。
接收器中的渲染模块负责在播放所获取音频的同时显示所获取的视频。
处理
为了使用基于生成的方案对人脸视频进行编码,我们的系统中使用了 [7] 中的方法。该过程如图 2 所示。
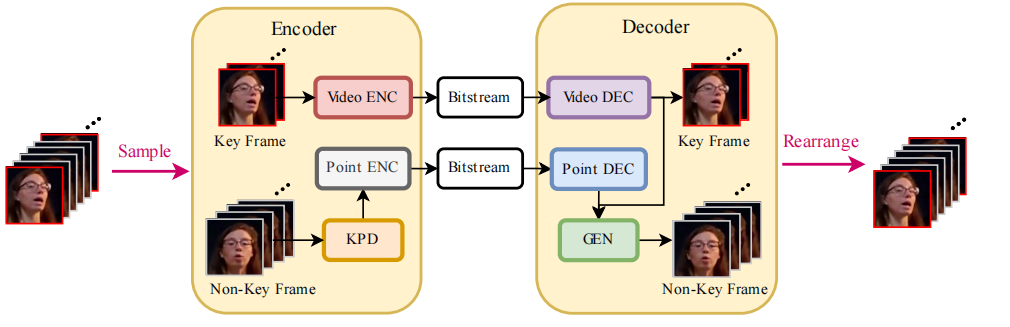
在编码器中,根据关键帧频率 f,将视频帧分为关键帧和非关键帧。具体来说,第 , 帧是关键帧,而其他帧是非关键帧。对于关键帧,数据被传递到视频编码模块,而非关键帧被传递到关键点检测器(KPD)以提取关键点。提取的点被送到点编码模块编码成比特流。
在解码器中,将视频位流和关键点比特流解码为关键帧和非关键帧的关键点。当非关键帧的关键点和在它们之前和之后最近的关键帧都可用时,它们被发送到生成器(GEN)来生成非关键帧。
KPD 被用来检测每帧的十个关键点。每个关键点是一个二维归一化坐标,包含两个浮点数,代表说话人脸的稀疏运动。
GEN 首先结合关键帧和非关键帧的关键点来创建稀疏运动,然后用于扭曲关键帧。扭曲的关键帧和稀疏运动用于预测密集运动和遮挡图。然后,原始关键帧被密集运动扭曲并被遮挡图掩盖。最后,扭曲的特征由解码器网络解码以生成重建的非关键帧。
在我们的系统中,编码器和解码器分别位于发送端和接收端。在发送端,关键帧直接发送到下一个编码模块。非关键帧被发送到 KPD,先提取关键点。然后将提取出来的关键点喂给编码模块。在接收端,当有新的关键帧可用时,将之前的关键帧和它们之间的非关键帧的关键点一起馈送给 GEN,生成非关键帧的图像。
音频数据直接发送到下一个模块,不进行任何处理。
编码和解码
在编码模块中,关键帧采用低延迟配置的视频编解码器进行编码,没有双向插值预测帧,目的是不引入额外的编码延迟。关键帧需要相对较高的质量来保证生成的非关键帧的质量。
非关键帧的关键点被量化为 8 位或 12 位的整数,进行帧内和帧间预测,并采用零阶指数哥伦布编码和自适应算术编码进行编码。
对于音频,我们的系统中使用了 Lyra,因为它是开源的,并且专为具有超低比特率和可接受质量的语音编码场景而设计。
在解码模块中,使用对应的关键帧、关键点和音频解码器来得到重构数据。
发送和接收
因为我们的系统需要灵活定制的应用层设计,所以我们直接使用 QUIC 作为底层传输协议。Quiche 是 IETF 指定的 QUIC 传输协议和 HTTP/3 的实现,它在 Rust 中实现 QUIC 内核,并提供 C/C++ API。基于 Quiche 库,我们设计了发送和接收模块。
发送模块获取编码数据并将它们打包成 QUIC 数据包。然后数据包按照 QUIC 的控制模块如流量控制、拥塞控制和优先级调度的顺序被发送到对端。接收模块接收数据包并反馈状态信息以指导进一步的数据包发送。此外,它将数据包解包并发送到后续处理。
虚拟化身工作流程
虚拟化身工作流程中的模块与人脸编码工作流程中的模块类似,只是处理模块不同。此外,由于驱动化身只需要所有帧的关键点而不是关键帧,因此在这个工作流程中没有使用关键帧数据流。音频流与人脸编码完全相同,而关键点流略有不同。
在我们的系统中,我们使用 kalidokit 作为面部标志和虚拟化身驱动参数之间的桥梁。Kalidokit 是用于 Mediapipe 人脸和眼睛跟踪模型的 blendshape 和运动学求解器,兼容许多 SOTA 面部标志检测方法。它采用 3D 地标并计算简单的欧拉旋转和 blendshape 面值。
在处理模块中,首先将一个视频帧输入到面部标志检测子模块中,得到面部标志。然后通过 kalidokit 进一步处理得到头像驱动参数,发送到编码模块。将驱动参数而不是面部标志传递给下一个模块的原因是它们的数据量远小。
驱动参数是一些不同范围的浮点数,根据范围进行量化。量化后的参数进行帧内和帧间预测,并用零阶指数哥伦布编码和自适应算术编码编码成为比特流。
在接收端,将一帧的参数解码和反量化后,用它们驱动化身模型。
逼真化身工作流程
在逼真化身工作流中,模块也与虚拟化身工作流中的类似,除了处理模块,下文将描述。
处理
与以前的工作不同,我们利用基于 3D 的方法来合成逼真的说话人脸视频。我们的系统可以将音频或附加的驱动图像序列作为输入,然后生成与音轨或其他图像序列同步的新颖的说话人脸视频。
为了合成逼真的谈话人脸视频,我们提出了一个可以由音频输入或其他视频人脸驱动的综合框架。简而言之,我们首先通过 [22] 从驱动面部图像中估计面部形状和姿势参数,然后使用 [23] 将形状和姿势参数与从音频输入预测的 3D 面部表情相结合。然后,我们在 GPU 中使用 3D Morphable Model [22] 渲染人脸形状。最后,我们利用神经渲染从输入的面部形状合成逼真的图像。图 3 显示了虚拟化身和现实化身的框架。图3 我们提出的虚拟化身和现实化身的框架
为了利用驱动面部图像的输入,我们首先估计面部标志或 3D 面部表情。面部标志用于分析驱动面部的运动并使用 kalidokit 生成虚拟头像的视频。包括形状、姿势和表情在内的 3D 面部参数用于生成逼真的头像,我们首先采用 GPU 渲染来合成面部形状,然后使用神经渲染器生成逼真的头像。为了仅使用音轨作为输入来生成说话的化身,我们将音频特征提取到 Mel-spectrum 并预测相应的 3D 面部表情。然后将估计的表情与形状和姿势参数(如果我们只使用音频,则预定义)组合来渲染面部形状。请注意,我们的方法可以使用来自驱动面部或来自音频的表情。这允许用户从相机中隐藏他的脸,并只用他的语音生成谈话人脸。
该框架对于视频会议系统有两个明显的优点。首先,我们可以在一个系统中生成虚拟化身和现实化身的谈话人脸视频。其次,我们的框架可以使用不同的输入方式来生成谈话视频,这可以更好地保护用户隐私。
综合总结
在逼真化身工作流程中,发送方的处理模块负责提取 3D 面部参数,或者如果我们只使用音频进行渲染,则只需传递音频数据。接收端的处理模块使用获取的参数(如果有)和音频数据执行整个框架,以合成逼真的图像。
除了音频编码之外,如果我们将 3D 面部参数传输并用于逼真的头像生成,则编码和解码模块使用与虚拟头像工作流程中相同的方式对 3D 面部参数进行编码和解码。
实验
环境
在本节中,我们介绍了所提出系统的实验结果。系统用 python 编写,操作系统 ubuntu 20.04 64bit。整个系统在具有 i9-10900CPU、32-GB RAM 和支持 CUDA 的 NVIDIA GTX 1080Ti GPU 的单台计算机上运行。

图 4 显示了系统运行的屏幕截图,子图 (a) 中的灰色方框代表人脸编码,(b) 中的蓝色方框代表虚拟化身,(c) 中的绿色方框代表真实化身。在每个子图中,本地和远程用户分别位于左侧和右侧。在子图(a)中,远程用户的大部分帧都是在本地生成的。在(b)中,网络网格和黄点表示提取的关键点。这些点被传输到另一侧并驱动虚拟化身。在(c)中,现实化身由音频驱动。
为了测试所提出的系统,我们使用两台计算机,一台是带有上述设备的 PC,另一台是普通笔记本电脑。实验过程中,整个系统在 PC 上运行,而笔记本电脑上只运行一个接收和发送模块,这意味着笔记本电脑从 PC 接收数据并将其发回。使用这种方法,实验只需要一个高性能设备。
比特率
对于视频会议系统,最基本和最关键的指标是比特率和延迟。测试视频是从 720p25fps 摄像机捕获的 906 帧。在人脸编码中,帧被裁剪并调整为 256×256,关键帧频率设置为 5。所提出系统的比特率性能如表 1 所示。
表 1 所提出系统的比特率性能。
| Workflow | Face encoding | Virtual avatar | Realistic avatar |
|---|---|---|---|
| Bitrate(kbps) | 7.38(video)+3(audio) | 0.77(video)+3(audio) | 3(audio) |
对于音频编码,lyra 每 40 毫秒从语音中提取特征,然后将其压缩后以 3kbps 的比特率传输。
对于人脸编码,为了对关键帧进行编码,[7] 使用了 VVenC,这是一个开源和优化的 VVC 编解码器实现,可以获得最优的编码性能和相对较高的编码效率。然而,即使是 VVenC 和 VVdeC 也离实际使用还有一定距离,由于VVC极高的编码复杂度及其导致的编码延迟。因此,我们使用 x265 作为视频编码器来编码关键帧,因为它具有稳定性、编码速度快和良好的 RD 性能。作为比较,x265 使用类似的参数直接编码原始视频的比特率为 29.25kbps,同时保持几乎相同的 PSNR。
时延
测试设备之间的 RTT 为 2.48ms,使用 Ping 命令进行测试。所提出系统的延迟性能如表 2 所示。音频流延迟仅在传输(4.17ms)和解码(60ms)中,因此未在表中显示。
表 2 所提出系统的延迟性能。K 代表关键帧,NK 代表非关键帧。— 表示这里除了音频之外没有任何处理。
| Workflow | Face encoding(K) | Face encoding(NK) | Virtual avatar | Realistic avatar |
|---|---|---|---|---|
| Process(sender)(ms) | <0.1 | 10.91 | 14.44 | — |
| Encode(ms) | 1.13 | 0.14 | 0.12 | — |
| Transfer(ms) | 4.31 | 3.69 | <0.1 | — |
| Decode(ms) | 0.14 | <0.1 | <0.1 | — |
| Process(receiver)(ms) | <0.1 | 39.08 | <0.1 | 79.61 |
| End to end(ms) | 205.57 | 205.57 | 60.10 | 139.61 |
人脸编码的端到端延迟比较高,因为非关键帧的生成需要下一个关键帧,这引入了等待其他帧的延迟。当下一个关键帧可用时,可以显示上一个关键帧。而非关键帧是同时生成的,没有额外的延迟。
对于虚拟化身工作流程,主要的延迟瓶颈是音频解码,因为视频相关模块只消耗很少的计算时间。对于逼真的化身工作流程,音频解码和化身驱动各自导致一半的延迟。
总结
在本文中,我们提出并实现了一种具有灵活虚拟访问模式的超低比特率视频会议系统。基于人脸编码、虚拟和逼真化身驱动等方面的发展,通过对语义和控制信息的编码和传输,部分或全部替换视频帧,实现超低码率的目标。通过不传输捕获的视频帧,仅传输一些关键点和音频数据来保护用户隐私。该系统即将开源,提供了良好的体验质量并且易于实际部署。
未来,我们计划研究基于网络条件的不同接入方式的自适应切换策略,这将进一步提高视频会议系统的灵活性和服务质量。
参考文献
[1] B. Marczak and J. Scott-Railton, “Move Fast and Roll Your Own Crypto: A Quick Look at the Confidentiality of Zoom Meetings,” University of Toronto, Citizen Lab Research Report No. 126, Apr. 2020. Accessed: Apr. 25, 2022. [Online]. Available: https://citizenlab.ca/2020/04/move-fast-roll-your-own-crypto-a-quick-look-at-theconfidentiality-of-zoom-meetings/
[2] C. Perkins and J. Ott, “Real-time Audio-Visual Media Transport over QUIC,” in Proceedings of the Workshop on the Evolution, Performance, and Interoperability of QUIC, Heraklion Greece, Dec. 2018, pp. 36–42. doi: 10.1145/3284850.3284856.
[3] M. Palmer, T. Krüger, B. Chandrasekaran, and A. Feldmann, “The QUIC Fix for Optimal Video Streaming,” in Proceedings of the Workshop on the Evolution, Performance, and Interoperability of QUIC, Heraklion Greece, Dec. 2018, pp. 43–49. doi: 10.1145/3284850.3284857.
[4] D. Feng, Y. Huang, Y. Zhang, J. Ling, A. Tang, and L. Song, “A Generative Compression Framework For Low Bandwidth Video Conference,” in 2021 IEEE International Conference on Multimedia Expo Workshops (ICMEW), Jul. 2021, pp. 1–6. doi: 10.1109/ICMEW53276.2021.9455985.
[5] Y. Nirkin, Y. Keller, and T. Hassner, “FSGAN: Subject Agnostic Face Swapping and Reenactment,” 2019, pp. 7184–7193. Accessed: Apr. 24, 2022. [Online]. Available: https://openaccess.thecvf.com/content_ICCV_2019/html/Nirkin_FSGAN_Subject_Agnostic_Face_Swapping_and_Reenactment_ICCV_2019_paper.html
[6] A. Siarohin, S. Lathuilière, S. Tulyakov, E. Ricci, and N. Sebe, “First Order Motion Model for Image Animation,” in Advances in Neural Information Processing Systems, 2019, vol. 32. Accessed: Apr. 24, 2022. [Online]. Available:https://proceedings.neurips.cc/paper/2019/hash/31c0b36aef265d9221af80872ceb62f9-Abstract.html
[7] A. Tang et al., “Generative Compression for Face Video: A Hybrid Scheme,” ArXiv220410055 Eess, Apr. 2022, Accessed: Apr. 22, 2022. [Online]. Available: http://arxiv.org/abs/2204.10055
[8] M. Oquab et al., “Low Bandwidth Video-Chat Compression using Deep Generative Models,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, Jun. 2021, pp. 2388–2397. doi: 10.1109/CVPRW53098.2021.00271.
[9] T.-C. Wang, A. Mallya, and M.-Y. Liu, “One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, Jun. 2021, pp. 10034–10044. doi: 10.1109/CVPR46437.2021.00991.
[10] G. Konuko, G. Valenzise, and S. Lathuilière, “Ultra-low bitrate video conferencing using deep image animation,” ArXiv201200346 Cs, Dec. 2020, Accessed: Apr. 22, 2022.
[11] Y. Guo, K. Chen, S. Liang, Y.-J. Liu, H. Bao, and J. Zhang, “AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis,” 2021, pp. 5784–5794. Accessed: Apr. 30, 2022. [Online]. Available: https://openaccess.thecvf.com/content/ICCV2021/html/Guo_ADNeRF_Audio_Driven_Neural_Radiance_Fields_for_Talking_Head_Synthesis_ICCV_2 021_paper.html
[12] J. Thies, M. Elgharib, A. Tewari, C. Theobalt, and M. Nießner, “Neural Voice Puppetry: Audio-Driven Facial Reenactment,” in Computer Vision – ECCV 2020, Cham, 2020, pp. 716–731. doi: 10.1007/978-3-030-58517-4_42.
[13] K. R. Prajwal, R. Mukhopadhyay, V. P. Namboodiri, and C. V. Jawahar, “A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild,” in Proceedings of the 28th ACM International Conference on Multimedia, New York, NY, USA: Association for Computing Machinery, 2020, pp. 484–492. Accessed: Apr. 29, 2022. [Online]. Available: https://doi.org/10.1145/3394171.3413532
[14] L. Chen, R. K. Maddox, Z. Duan, and C. Xu, “Hierarchical Cross-Modal Talking Face Generation With Dynamic Pixel-Wise Loss,” 2019, pp. 7832–7841. Accessed: Apr. 30, 2022. [Online]. Available: https://openaccess.thecvf.com/content_CVPR_2019/html/Chen_Hierarchical_CrossModal_Talking_Face_Generation_With_Dynamic_PixelWise_Loss_CVPR_2019_paper.html
[15] H. Xue, J. Ling, L. Song, R. Xie, and W. Zhang, “Realistic Talking Face Synthesis With Geometry-Aware Feature Transformation,” in 2020 IEEE International Conference on Image Processing (ICIP), 2020, pp. 1581–1585. doi: 10.1109/ICIP40778.2020.9190699.
[16] O. Fried et al., “Text-based editing of talking-head video,” ACM Trans. Graph., vol. 38, no. 4, p. 68:1-68:14, Jul. 2019, doi: 10.1145/3306346.3323028.
[17] “hjp: doc: RFC 6716: Definition of the Opus Audio Codec.” https://www.hjp.at/doc/rfc/rfc6716.html (accessed Apr. 22, 2022).
[18] M. Dietz et al., “Overview of the EVS codec architecture,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Apr. 2015, pp. 5698–5702. doi: 10.1109/ICASSP.2015.7179063.
[19] M. Neuendorf et al., “The ISO/MPEG Unified Speech and Audio Coding Standard—Consistent High Quality for All Content Types and at All Bit Rates,” J. Audio Eng. Soc., vol. 61, no. 12, pp. 956–977, Dec. 2013.
[20] W. B. Kleijn et al., “Generative Speech Coding with Predictive Variance Regularization,” in ICASSP 2021 – 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Jun. 2021, pp. 6478–6482. doi:10.1109/ICASSP39728.2021.9415120.
[21] N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “SoundStream: An End-to-End Neural Audio Codec,” IEEEACM Trans. Audio Speech Lang. Process., vol. 30, pp. 495–507, 2022, doi: 10.1109/TASLP.2021.3129994.
[22] Y. Feng, H. Feng, M. J. Black, and T. Bolkart, “Learning an animatable detailed 3D face model from in-the-wild images,” ACM Trans. Graph., vol. 40, no. 4, p. 88:1-88:13, Jul. 2021, doi: 10.1145/3450626.3459936.
[23] L. Chen, Z. Wu, J. Ling, R. Li, X. Tan, and S. Zhao, “Transformer-S2A: Robust and Efficient Speech-to-Animation,” ArXiv211109771 Cs Eess, Apr. 2022, Accessed: Apr. 30, 2022. [Online]. Available: http://arxiv.org/abs/2111.09771
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
