
大语言模型(LLM)的成功促进了多模态大语言模型(MLLM)的新研究趋势,改变了计算机视觉各个领域的范式。尽管 MLLM 在许多 high-level vision 和 vision-language 任务(例如 VQA 和 text-to-image)中显示出很好的结果,但没有研究表明 low-level vision 任务如何从 MLLM 中受益。我们发现,当前大多数 MLLM 由于其视觉模块的设计而对低级特征视而不见,因此本质上无法解决低级视觉任务。在这项工作中,我们的目标是 LM4LV,这是一个框架,使 FROZEN LLM 能够在没有任何多模态数据或先验的情况下解决一系列低级视觉任务。这展示了 LLM 在低级视觉方面的强大潜力,并弥补了 MLLM 和 low-level vision 任务之间的差距。我们希望这项工作能够激发人们对 LLM 的新视角以及对其机制的更深入理解。
题目: LM4LV: A Frozen Large Language Model for Low-level Vision Tasks
作者: Boyang Zheng, Jinjin Gu, Shijun Li, Chao Dong
论文地址: https://arxiv.org/abs/2405.15734
内容整理:杜君豪
引言
大语言模型(LLM)的巨大成功和推广性带来了多模态大型语言模型(MLLM)的新研究趋势。我们想知道 LLM 可以给计算机视觉带来多大的好处,以实现更好的性能并实现真正的智能。最近对 MLLM 的尝试在图像字幕和视觉问答 (VQA) 等高级视觉任务上展示了很好的结果。然后我们对它在低级视觉任务上的能力感到好奇,比如图像去噪和去雨。另一方面,由于现有的工作已经证明LLM已经可以理解语义图像特征,那么它们距离直接生成图像作为生成模型还有多远?所有这些都集中到同一个问题:是否可以利用 MLLM 来接受、处理和输出低级特征?这对于进一步突破 MLLM 和低级视觉的极限非常重要。我们将在这项工作中进行初步的探索。
现有文献表明 MLLM 和低级视觉任务之间存在显着差距。当前许多 MLLM 相关工作的主要方向是文本和图像模态更好的语义融合。遵循这一趋势,一些工作旨在使用 LLM 来评估低级属性,例如亮度和清晰度。然而,大多数低级视觉任务处理和生成像素级信息,这些信息与有意义的单词不对应。此外,输出图像必须与原始图像具有高保真度和一致性,这是当前 MLLM 的常见缺陷。尽管许多工作都致力于赋予 MLLM 图像生成功能,但大多数 MLLM 缺乏对图像的详细控制。我们表明大多数具有图像生成功能的 MLLM 无法执行简单的图像重建。这表明这些 MLLM 本质上无法处理低级视觉任务,因为它们缺乏处理低级细节的能力。
弥补 MLLM 和低级视觉任务之间的差距对于这两个领域都很重要。MLLM 通过将视觉任务统一为通用对话方式,改变了计算机视觉许多领域的范式。然而,低级视觉任务尚未从 MLLM 带来的变化中显着受益。目前,大多数低级视觉模块只是提供图像到图像的映射,而无需文本干预。弥补这一差距可以让我们利用 MLLM 强大的推理和文本生成能力来完成低级视觉任务,在解决低级视觉任务时提供更好的用户交互和更大的可解释性。另一方面,低级特征是图像的重要组成部分,但在当前的 MLLM 中经常被忽视和丢弃。使 MLLM 能够处理低级特征可以带来对图像更细粒度的理解并更好地控制图像生成过程。
此外,大多数 MLLM 都是在大量多模态数据的语料库上进行训练的,并以现有的 LLM 作为初始化。然而,LLM 初始化给 MLLM 带来的影响还没有得到充分研究。LLM 是否只是提供强大的文本功能,还是也为其他模式提供潜在的能力?因此,我们强调研究 LLM 在没有多模态数据或先验的情况下处理视觉特征的能力的重要性,这可以使人们更深入地了解 LLM 的内部机制。尽管一系列工作努力研究 frozen LLM 的视觉特征处理能力,但没有一个成功地使 LLM 能够在没有多模态监督的情况下产生视觉特征。LQAE 通过将图像量化为文本标记,设法以 in-context learning(ICL)方式执行图像到文本的任务,而无需任何多模态数据。然而,即使对于非常基本的低级视觉任务(例如去模糊),它也会失败,这表明它无法生成条件图像。
方法
当前的 MLLM 对低级特征视而不见
我们的灵感源于一个观察:当前具有图像生成能力的 MLLM 对低级视觉特征视而不见。因此,它们本质上无法处理低级视觉任务。我们将 MLLM 的盲目性归因于它们的视觉模块。我们观察到大多数 MLLM 的视觉模块无法执行图像重建,这表明视觉模块中的视觉编码器正在执行有损编码过程。如图 1 所示,MLLM 中的视觉模块通常倾向于捕获高级语义,但无法维护低级细节,从而对图像进行有损压缩。
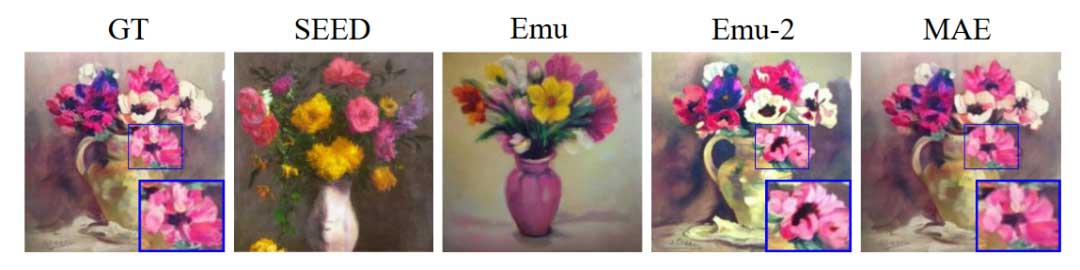
目前,大多数 MLLM 都遵循这种有损压缩方法,通常依靠大规模多模态训练来训练其视觉模块。例如,Emu-2 使用 162M 图像文本对与 LLM 主干网络一起训练视觉编码器,并利用预先训练的文本到图像扩散模型作为解码器。这种方法的优点是显而易见的:广泛的多模态训练可以更好地协调视觉和文本。更好的协调通常会带来改进的交互和模式融合,这对于 MLLM 非常重要。这也允许这些 MLLM 使用预先训练的 LLM 作为进一步训练的骨干初始化。例如,SEED 通过使用 LoRA 对 LLM 进行微调,赋予 LLM 图像生成能力。然而,这种对齐的缺点是视觉特征通常会丢失大量原始图像信息,无法保持低级细节。因此,我们认为这些 MLLM 本质上缺乏处理低级任务的能力。
使 LLM 能够了解底层特征
选择视觉模块的原则。 MLLM 中当前选择的视觉模块无法维护低级细节。因此,选择合适的包含图像完整信息的视觉模块至关重要。这使得LLM主干能够访问低级特征,这是进一步探索LLM处理低级特征能力的基础。我们认为,选择视觉模块有两个基本原则。首先,视觉模块的训练目标应该是重构。这鼓励视觉编码器维护低级细节,以便可以将编码的特征解码回像素空间。其次,视觉模块必须以无监督的方式进行训练,以避免任何多模态训练。这一点很重要,因为LLM已经具备强大的文本处理能力。如果编码器已经将图像转换为类似文本的特征,那么就不清楚LLM是否正在利用其强大的文本处理能力来处理文本特征,或者它本身就有处理其他模式的能力。在这些限制下,只剩下几个视觉编码器系列。其中,我们最终的选择是掩模自动编码器(MAE),它是掩模图像建模(MIM)家族的代表,它将图像编码为一系列视觉特征,旨在使用掩模图像标记重建原始图像。
微调 MAE 以进行图像重建。 尽管 MAE 经过训练可以从屏蔽标记序列重建图像,但直接使用 MAE 进行图像重建会导致性能不佳。我们发现这个问题的出现主要是因为 MAE 的发布版本仅根据屏蔽token计算重建损失。这导致训练和推理行为之间的不一致,因为在图像重建过程中没有屏蔽token。我们使用 L1 重建损失在 ImageNet 训练集上微调 MAE 的解码器,同时保持编码器冻结。
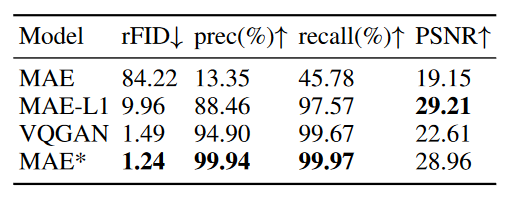
这种微调显着提高了 MAE 在图像重建方面的性能。继 VQGAN 之后,我们进一步将 LPIPS 损失纳入训练中,从而获得更好的重建 FID,但 PSNR 得分略低。尽管每个补丁的对抗性损失可能会进一步提高性能,但我们没有合并对抗性损失,因为这可能会给图像带来伪影。由于我们的目标是研究 LLM 处理视觉特征的能力,因此我们期望解码器忠实于这些特征,而不是在解码过程中引入伪影。
我们将 MAE 与常用的图像重建模块 VQGAN2 进行比较。从表1和图4可以看出,微调后的 MAE 具有最佳的重建能力,引入的伪影更少,表现出更好的人脸重建效果。从现在开始,除非另有说明,术语 MAE 指的是微调版本 MAE*。
低级视觉任务的下一个元素预测
与 Emu 和 Emu2 类似,我们应用下一个元素预测策略,使 LLM 能够接受视觉特征并以自回归方式输出视觉特征。我们的主要网络结构如图2所示。
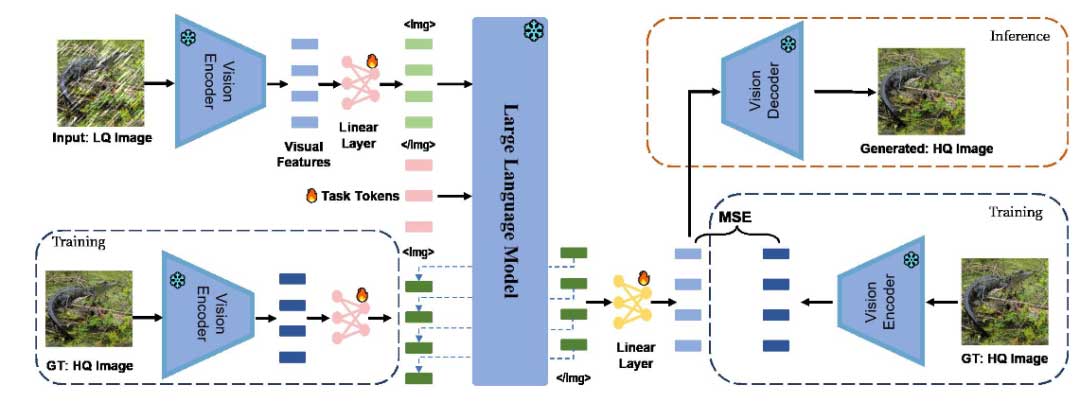
适配器模块。 当我们想要研究 LLM 处理低级视觉特征的能力时,我们需要限制适配器的复杂性。因此,我们使用两个简单的线性层作为LLM和视觉编码器/解码器之间的适配器模块来对齐特征维度。如果视觉特征与LLM的维度一致,我们将其称为“视觉token”。
训练和生成策略。 在训练中,我们对文本token应用标准的交叉熵损失。对于连续视觉token,我们应用 L2 回归损失。这将文本和视觉的训练过程统一为下一个元素预测任务。对于生成,我们使用自回归生成方案,一次生成一个文本或视觉token。为了在生成视觉token和文本token之间切换,我们设置默认生成文本token,并且视觉特征分别由之前和之后的token <Img> 和 </Img> 描绘。仅在 LLM 生成 <Img> 后才会生成视觉特征。生成一系列视觉token后,LLM将返回生成文本token。然后,视觉token序列通过线性适配器转换为视觉特征,并由视觉解码器解码为图像。
在这种范式下,我们将低级视觉任务定义为在视觉指令下执行的条件图像生成任务。对于由低质量图像和高质量图像组成的对,我们将其转换为对话格式:
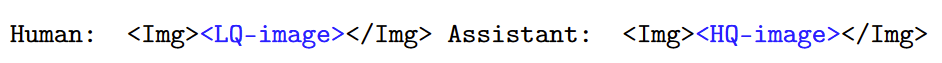
这里<LQ-image>和<HQ-image>分别表示低质量和高质量图像的视觉特征序列(线性投影后)。我们应用指令微调策略,仅计算所需输出<Img><HQ-image></Img>的损失。
然而,当前的设计缺乏对目标低级视觉任务的描述。这可能会导致在经过训练的适配器投影中包含与任务相关的软提示,这是不希望的,因为我们期望适配器模块纯粹专注于图像和文本空间之间的转换。由于低级视觉任务很难使用语言精确描述,因此我们在指令中加入了可训练的任务token序列<task>。这是一个软提示,指导LLM执行特定的低级视觉任务。最终数据格式如下:
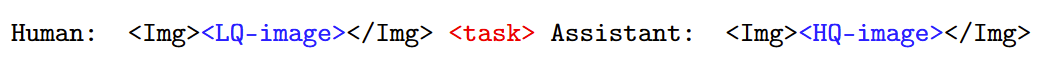
在这种格式中,普通文本token(以黑色token)通常被tokenize。视觉token(以蓝色token)由视觉编码器和线性层进行编码。任务token(以红色token)是直接插入到输入序列中的可训练嵌入序列。在整个pipeline中,唯一可训练的参数是两个线性适应模块和任务token序列,它们在训练期间联合优化。
LLM 处理低级任务的能力
实验设置
基本模型和超参数。 我们使用 LLaMA2-7B instruct3 作为我们所有实验的基础 LLM。对于视觉模块,我们使用 MAE-Large 并对解码器进行微调。对于适配器模块,我们仅使用线性层作为仿射变换。默认情况下,我们使用长度为 10 的可训练任务token序列。
训练细节。 我们使用 LLAVA595k 数据集作为基础数据集,在没有数据增强的情况下进行降级生成。所有图像的大小都调整为 224 × 224 以适合 MAE 的输入大小。我们使用的实际批量大小为 256。默认情况下,我们训练模型 2 个epoch,因为我们观察到 2 个epoch后收敛。我们使用 AdamW 作为优化器,β = (0.9, 0.95),lr = 0.0003 并且没有权重衰减。我们使用具有 200 个warm-up steps 的warm-up decay 策略。所有实验均在最多 4 个 NVIDIA A100 GPU 上完成。单次训练时间约为8小时。
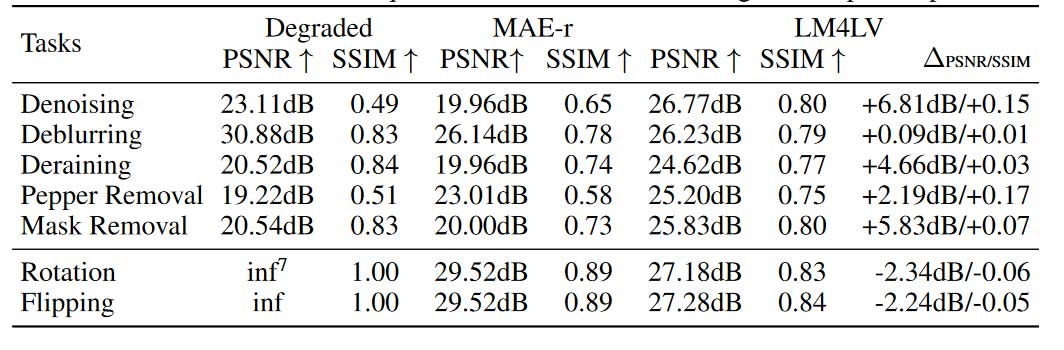
评估任务。 我们在几个代表性的低级视觉任务上评估我们的方法:去噪,去模糊,胡椒噪声去除,去雨和掩模去除。我们使用 NoCaps 数据集作为测试集,并添加与训练相同的退化。我们使用 PSNR 和 SSIM 作为默认指标。此外,SPAE 表明,在类似的设置下,简单的旋转可能具有挑战性。因此我们设置了两个需要大量空间操作的简单任务:图像旋转和图像翻转。我们将这些任务分别命名为恢复任务和空间操作任务。
退化细节。 对于去噪,我们添加均值为零的高斯噪声和从 [0, 50/255] 均匀采样的随机标准方差。为了去模糊,我们将高斯模糊添加到具有从 {1,3,5,7} 均匀采样的窗口大小的图像中。为了除雨,我们将随机角度和位置的降雨添加到图像中,降雨量从 [0, 20] 中均匀采样。为了消除胡椒噪声,我们将退化图像中的胡椒部分设置为从 [0, 0.1] 均匀采样。对于掩模去除,我们使用掩模大小 4 和掩模率 0.1。
基线。 由于我们的目标是研究LLM是否具有处理低级特征和处理低级视觉任务的能力,因此我们只需要验证使用LLM比什么都不做要好。因此,我们设置了使用 MAE 重建退化图像而无需进一步修改的基线(表示为 MAE-r)。在恢复任务中,该基线充当基于 MAE 的图像恢复方法的下限。在空间操作任务中,该基线充当上限,因为这种情况下的退化图像就是操作图像。
LLM 在低级视觉任务上表现出非凡的能力
我们的主要结果如表2所示,一些可视化如图 3 所示。从表 2 中可以看出,在所有恢复任务中,LM4LV 稳定地获得了比 MAE-r 基线更高的 PSNR 和 SSIM 分数。在图像去噪任务下,LM4LV获得了更高的PSNR分数,增加了6.81dB(从19.96dB到26.77dB)。在所有恢复任务上,LM4LV 实现了平均 PSNR 分数提升 3.96dB,平均 SSIM 提升 0.09。在空间操作任务上,LM4LV 实现了高 PSNR 和 SSIM,将裕度限制在上限基线范围内。结果表明LLM在处理和输出原始视觉特征方面具有不平凡的能力。

视觉模块的选择很重要
我们方法中的关键组件是视觉模块。虽然我们已经使用微调的 MAE 成功展示了 LLM 的低级视觉特征处理能力,但它促使我们研究不同的视觉模块如何影响结果。
无监督图像重建的视觉模块实际上没有太多选择。常见的选择是 VQ-GAN,它是 VAE 家族最先进的代表。另一个不太常见的选择是 BEiT,它最初用于图像识别。BEiT 的训练目标涉及预测 DALL-E tokenizer 的屏蔽标记,这些标记可以由 DALL-E 的解码器解码为图像。在实践中,我们发现 BEiT 的预测足够准确,即使没有微调也可以粗略地重建图像,这可能是因为与 MAE 相比,训练期间的掩蔽率较低。
我们使用 MAE、VQGAN 和 BEiT 作为我们pipeline中的视觉模块并评估它们的性能。我们从一个简单的任务开始:图像重复。LLM被要求重复输入图像。如图4所示,所有三个模块都成功执行了恒等映射。然而,当要求稍微复杂的任务:图像旋转时,VQGAN 和 BEiT 会产生没有语义意义的杂乱图像,而 MAE 仍然表现良好。这表明视觉模块的选择对于我们方法的成功很重要。

自回归生成很重要
另一个需要考虑的问题是自回归(AR)生成的必要性。事实上,AR 并不是图像生成的主流方法。当前的 AR 方法通常不如基于扩散的方法,并且往往需要更高的计算成本。因此,我们设计了更直接、更具视觉风格的生成方案。我们将退化的图像token提供给 LLM,并期望它在单个前向过程中直接输出精选的图像token。我们将这个生成过程称为“ViT-LLM生成”,因为它将LLM视为正常的ViT。我们仍然使用视觉特征的 l2 回归作为训练目标。
在训练过程中,这个过程中可训练的参数是两个线性适应层。此外,我们在前向过程中取消了因果注意掩模和 ROPE 位置嵌入,因为它们不是视觉模块的常见做法。我们在图像去噪方面测试了这种生成方案。如图 5 所示,即使噪声水平较低,ViT-LLM 生成也会产生低质量且模糊的图像。这表明自回归生成对于我们的成功至关重要。此外,使用自回归特征生成自然地与LLM的行为保持一致,并且可以作为额外的编码和解码模块无缝插入到LLM的生成中。

消融研究
为了确保LLM而不是其他模块在处理低级特征中发挥关键作用,我们有意简化了其他组件的设计。然而,我们仍然需要广泛的消融研究来进一步验证LLM的重要性。
线性层正在执行任务吗?
尽管我们的适应模块有意简化为简单的线性层,但我们仍然需要验证是否是适应模块完成了低级视觉任务。为此,我们从模型中删除了LLM组件和自回归生成过程,只留下线性适应模块。在此阶段,训练目标是使用线性层将低质量视觉特征映射到 MAE 生成的高质量视觉特征。
我们使用 L2 回归来训练线性层以进行图像去噪。一些可视化如图 6 所示。很明显,单个线性层不足以有效处理低级视觉任务。虽然图像的主要结构仍然存在,但图像颜色怪异,并且被分割成碎片。

此外,我们观察到,通过训练,两个线性层倾向于执行缩放的恒等映射,即使它们不是被迫这样做的。这进一步证明了LLM在处理视觉特征方面的重要性。
文本预训练发挥重要作用吗?
一些研究发现随机初始化的 CNN 模块已经可以作为有效的表示提取器,这表明模型本身的架构具有解决各种任务的能力。因此,一个自然的问题出现了:文本预训练是否赋予了LLM解决低级视觉任务的能力,或者这种能力是LLM架构本身固有的?需要大量随机初始化来定义用于分类目的的内核,但尚未讨论 LLM 上的多个随机初始化与自回归生成的集成。因此,我们只随机初始化一次LLM并保持架构不变,测试其去噪性能。图 7 的可视化表明,随机初始化的 LLM 无法生成有意义的图像,这表明文本预训练对于 LLM 解决低级视觉任务至关重要。

LLM vs 专家模型
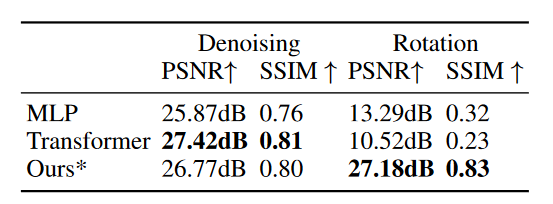
尽管我们已经验证了LLM处理视觉特征的能力,但问题仍然存在,幅度是多少?为了定量评估 LLM 的能力,我们用 2 层 MLP 或一层 Transformer 代替 LLM,作为解决视觉任务的专家模型。为了确保公平比较,MLP 和 Transformer 具有与我们的方法几乎相同数量的可训练参数。用专家模型替换线性层。
我们测试了专家模型在图像去噪和图像旋转方面的性能。从表 3 可以看出,我们的方法在图像去噪任务中超越了 MLP 基线,但落后于 Transformer 基线。但是MLP和Transformer都无法进行图像旋转,而LLM可以很好地处理它。这证明了LLM不平凡的低级特征处理能力。
讨论和限制
讨论。 除了让LLM能够完成低级视觉任务之外,我们的工作可能会带来一些有趣的话题。如前所述,这项工作的目标不是在图像恢复方面实现最佳性能,而是展示 LLM 在处理低级特征方面的潜力,并展示一种利用 LLM 强大的推理和交互能力来处理低级特征的可能方法。此外,由于 LM4LV 不涉及任何多模态数据,因此通过用自监督的特定领域模块替换 MAE,该框架可以扩展到跨模态数据稀缺的领域。
局限性。 如图 3 所示,LM4LV 无法恢复退化图像中的高频细节。这是很自然的,因为 LLM 没有图像先验,可以通过添加跳跃连接或多模态数据来改进。但这不是这项工作的重点。此外,我们的方法和单层 Transformer 之间观察到的性能差距也表明我们的方法还有改进的空间。
总结
在这项工作中,我们的目标是回答这个问题:冻结的LLM是否有能力接受、处理和输出低级特征?通过自下而上设计一个框架,我们给出了肯定的答案,展示了LLM在各种低级任务上的不平凡表现。我们希望这项工作能够激发人们对LLM能力的新视角以及对其机制的更深入理解。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
