
视觉信号压缩旨在最小化图像数据,在网络资源和存储容量有限的情况下,提高图像/视频的服务质量。自1991年以来,视觉信号的压缩率每十年增长一倍。然而,在即将到来的下一个十年,传统编解码器面对1,000倍压缩的超低比特率需求,已经经触及了香农极限。幸运的是,多模态大模型 (Large Multimodal Model, LMM) 的快速发展,为超低比特率的压缩提供了可能。
作者: Chunyi Li, Xiele Wu, Haoning Wu, Donghui Feng, Zicheng Zhang, Guo Lu, Xiongkuo Min, Xiaohong Liu, Guangtao Zhai, Weisi Lin
来源: 上海交通大学 MM-Lab,南洋理工大学 S-Lab
论文题目: CMC-Bench: Towards a New Paradigm of Visual Signal Compression
论文链接: https://arxiv.org/abs/2406.09356
代码链接: https://github.com/Q-Future/CMC-Bench
内容整理: Chunyi Li
为什么要使用LMM进行压缩? LMM支持多种模态之间的转换,其中文本比图像模态占用的空间少得多。通过图生文(Image-to-Text, I2T)和文生图(Text-to-Image, T2I)的级联,模型可以通过文字重建图像。这种跨模态压缩(Cross Modelity Compression, CMC)的范式在语义层面压缩、而非像素层面,因此可以轻松实现1,000倍压缩比,在极端情况下甚至可以达到10,000倍。
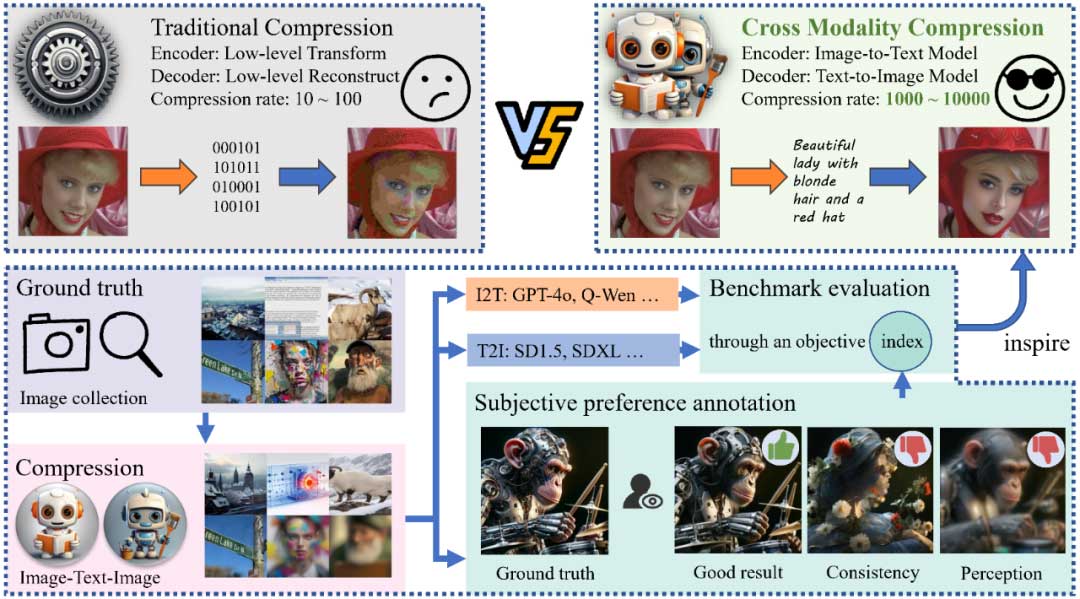
然而,在如此低的比特率下,CMC存在两个不容忽视的重要问题。1)Consistency: T2I解码过程严重依赖文本。I2T编码中文本遗漏的语义信息,或T2I解码中对文本的误解,都可能导致严重的失真。这可能导致整个图像在语义层面与原图大相径庭。2) Perception: 文本提供了原图的粗略信息,需要T2I模型添加细节。细节不足会降低图像本身的感知质量,而过多的细节会损害与原图的一致性。在极低的比特率下,它们的权衡非常难以把控。这两个因素共同制约了CMC的应用。
尽管最近涌现了许多针对LMM的基准测试,但它们主要用于评估单独的I2T或T2I模型。因此,本文推出了第一个名为CMC-Bench的基准测试,旨在评估图像压缩任务上,I2T和T2I模型之间的协作能力。从而指出LMM针对压缩任务进一步优化的方向,促进视觉信号编解码协议的演进。
CMC压缩方法
数据集构建
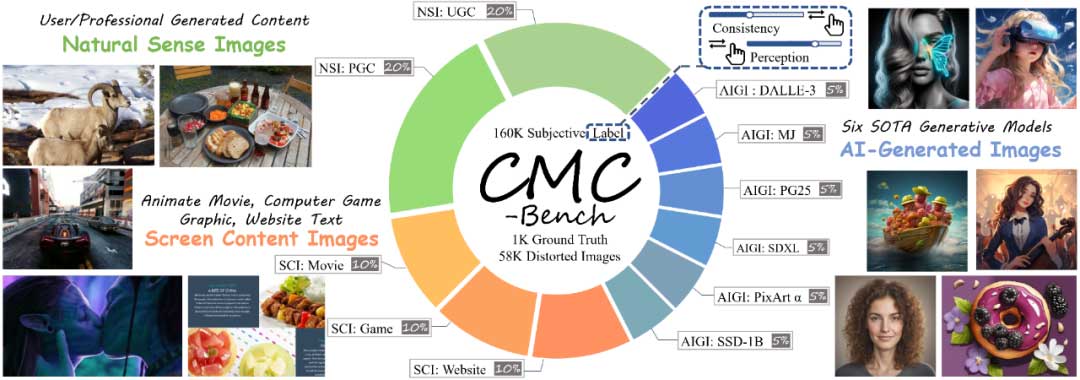
CMC-Bench精心挑选了1000张高质量图像,作为压缩基准。包括最主流的自然图像(Natural Sense Image, NSI),在网络上常见的屏幕图像(Screen Content Image, SCI),和新兴的生成式图像(AI-Generated Image, AIGI),其中:
NSI:来自CLIC数据库的200张高质量图像,由专业电视台/摄影师创作;以及选自MS-COCO的200张UGC图像,由普通用户拍摄。为确保图像质量,Q-Align被用于过滤了模糊、过曝等低质量UGC。
SCI:来自CGIQA-6K的100个CG动画电影截图;来自CCT的100个游戏渲染场景;以及来自SCID的100个网页,这些图像同时包含了图形与文本。
AIGI:每类包含50张图像,由6种最新的T2I模型生成:DALLE3、MidJourney、PG v25、PixArt 𝛼、SDXL和SSD-1B,代表网络上多数的AIGI。
工作模式
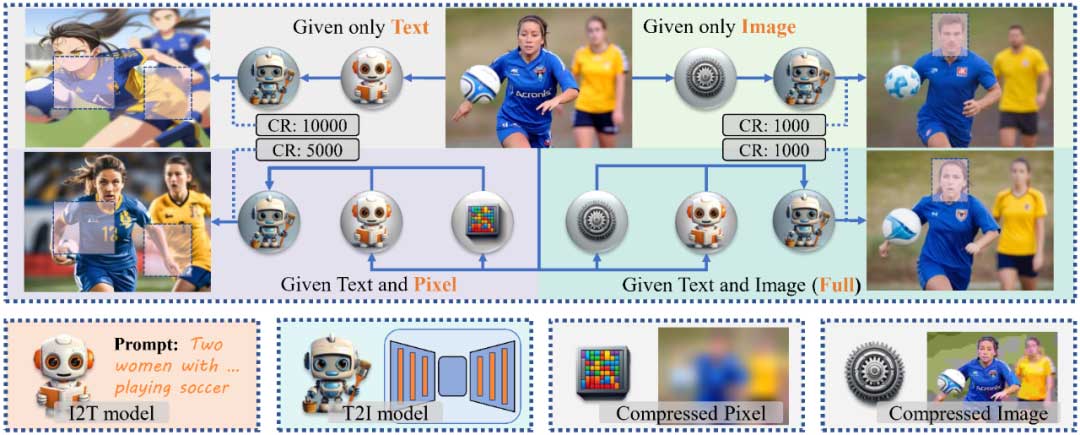
借鉴过往的CMC工作,本文将其分为四种压缩工作模式,每种类型都采用不同的配置,并适用于不同的场景:
Text:I2T模型将图像转换为文本,并由T2I模型直接恢复。由于仅依赖文本,这种方法实现了10,000倍压缩,但与原图一致性低。
Pixel:每个来自原图的64×64像素块被合并为一个。这些像素用于初始化T2I解码进程,可以达成约5,000倍压缩,通过像素的约束,它相比Text模式与原图更加一致。
Image:采用传统编解码器对图像进行极度压缩,类似Pixel模式,以这张压缩过的图像来初始化T2I过程。不同的是,它没有文本输入,即省略了耗时的I2T过程。这种方法可以实现 1,000倍压缩,适用实时性要求较高的场景。
Full:使用所有模块。即在Image的基础上,继续使用I2T模型,用文字指导T2I过程。它同样为1,000倍压缩,拥有的最佳综合性能。
排名对象
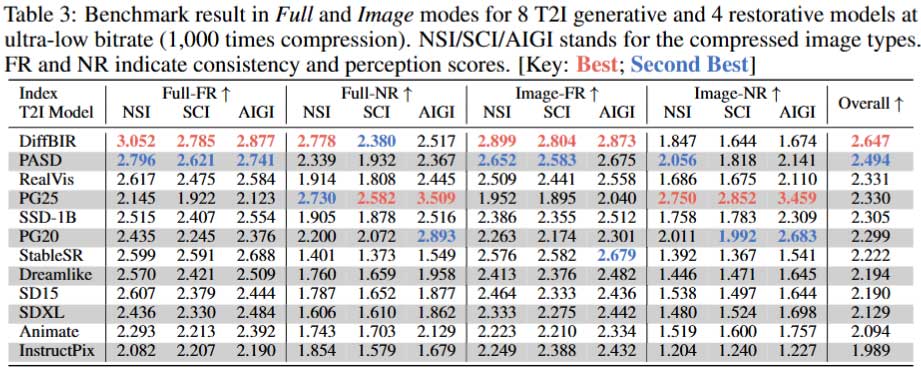
CMC-Bench在四种压缩模式下对比了6个I2T,12个T2I模型。其中,I2T模型在Image模式下不适用,共包含六个排名维度;而对于T2I,4种基于超分的模型不支持没有参考图像的Text和Pixel模式,只考虑四个排名维度,其余8种生成式模型则考虑全部八个排名维度。为了公平比较I2T模型的性能,T2I模型固定使用表现最好的RealVis,以保证失真主要来自I2T过程;同理,在验证T2I模型时,I2T模型将固定为GPT-4o。
I2T模型包括:GPT-4o、LLAVA-1.5、MPlugOwl-2,Qwen-VL、ShareGPT和 InstructBLIP。文本的输出长度设置为10∼20个词,用于在比特率和性能之间取得平衡。
T2I模型包括:Animate、DreamLike、PG20、PG25、RealVis、SD15、SDXL和 SSD-1B作为生成式模型;DiffBIR、InstructPix、PASD和StableSR作为文本指导的超分模型。
对于所有模型,CMC-Bench都在不同参数、不同模式下进行了验证,并将最佳性能作为结果汇报。
评估指标
CMC-Bench使用最先进的质量评价指标TOPIQ,包含了全参考(Full Reference, FR)和无参考(No Reference, NR)评价方法,分别用于表征Consistency和Perception维度。1,000张图像的平均分数报告为该维度的性能。由于TOPIQ-FR的浮动范围比TOPIQ-NR小,最终的性能排名来自2×FR+1×NR的加权平均。
为了保证评估的准确性。本文将100张原图用CMC范式压缩为4,000张失真图像。并向20名经验丰富的受试者展示以上图像对,在Consistency和Perception维度进行主观评分。实验显示,TOPIQ的客观评估与人类的主观偏好高度一致。相对于其它质量评价方法,它在以上两个维度与人类的相关性均超越了0.9。因此,它可以反映人类对压缩图像真实偏好,确保了CMC-Bench的可靠性。
实验
图生文模型排名
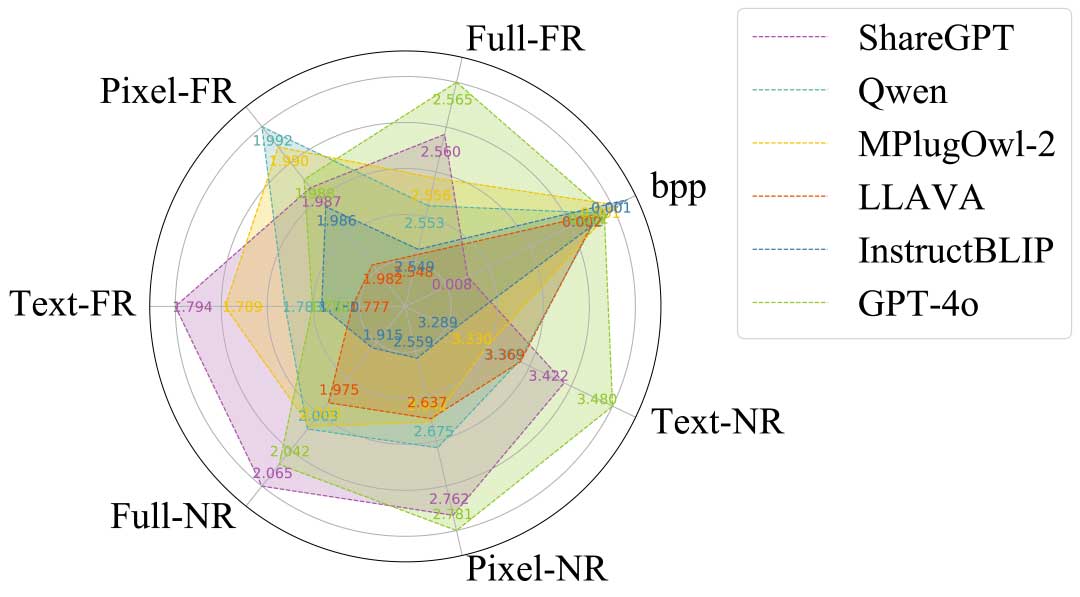
GPT-4o拥有最为杰出的图生文能力。虽然在Text-FR上表现不佳,但在Full-FR上表现最为亮眼。这表明,尽管其文本的信息量有限,但它与图像的低级细节高度正交,有效地补偿了图像压缩后的信息损失。此外,它在各种 NR 指标上的表现也令人满意。相比之下MPlugOwl-2和InstructBLIP表现较好,但综合结果仍然不如GPT-4o。唯一潜在的竞争者是ShareGPT,但它的比特率约为0.008,明显大于其他模型,较大的数据规模使其不适用于超低比特率压缩。考虑到多种因素,GPT-4o仍然是最适合用于编码器端的I2T模型。
文生图模型排名
两个超分模型DiffBIR和PASD在Full和Image模式下表现出压倒性的优势,能够有效重建与原图一致的结果。然而,它对其他两种模式的适用性有限。其余生成式的性能分为两个极端,其中RealVis在Consistency上最为亮眼,而PG20和PG25在Perception上遥遥领先。鉴于增强低质量图像是可行的,而校正与原图不同的高质量图像仍然具有挑战性,Consistency指标将被优先考虑。因此,考虑到优秀的表现和泛用性,推荐使用RealVis作为解码器端的T2I模型。
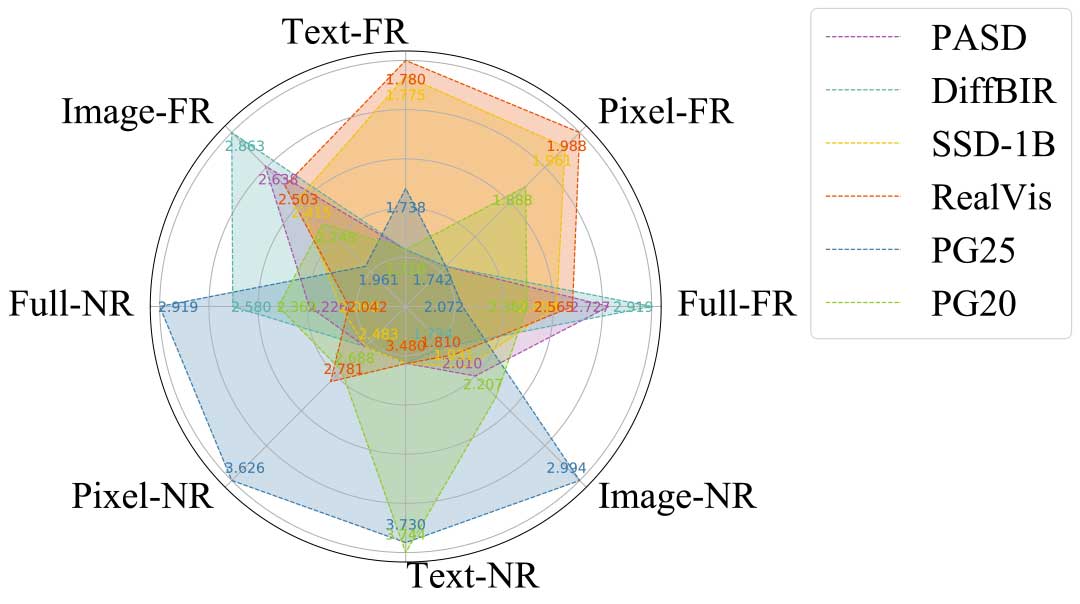
对于不同类别的原始图像,CMC-Bench也进行了进一步的对比。结果显示不同的LMM在NSI、SCI和AIGI上表现有一定差异,例如PG25在互联网数据上训练,在AIGI上表现更好;相反,RealVis的目标是图像自然度,在NSI中表现出其卓越的重建能力。无论采用何种模型,NSI通常产生更高的Consistency分数,而AIGI具有更高的Perception分数。然而,SCI性能明显不佳,在所有指标上都落后于另外两类图像。这种缺陷与SCI网页上的字符有关,I2T模型很难将它们重新识别为文本,同时T2I模型生成这些字符的能力也较为有限。
压缩结果示例
部分CMC的压缩编解码结果包含在了以下六张图中,所有管线都使用GPT-4o作为编码器,从左至右为Animate/Dreamlike/PG20/PG25/RealVis作为解码器,从上至下为Full/Image/Pixel/Text模式。对于不同模式,随着比特率的降低,结果与原图差异逐渐增大。Full模式保真度最高,Image模式会丢失人物性别等语义信息,Pixel模式丢失的信息更多但保留了类似原图的轮廓,Text模式则与原图差异最大。
对于不同内容,前两张图显示,CMC在AIGI上的表现最令人满意;中间两张图表明,CMC也可以获得与原始NSI较高的保真度,但容易丢失人脸和车牌等细节;后两张图则说明,它在SCI上表现最不理想,由于它误解了电影中角色的空间关系,并且无法在网页上绘制成型字母。总之,CMC是一种很有前途的视觉信号压缩方法,但要成为未来的通用编解码器标准,需要提高对所有内容类型的鲁棒性。

与传统编解码的对比
为了验证CMC范式的实用性,本文从CMC-Bench中挑选了两个个优秀的I2T+T2I组合,即GPT-4o+DiffBIR和GPT-4o+RealVis,并与三个主流编解码器,和一个先进的神经编解码器进行了比较。为了在不同维度上全面比较CMC与传统范式,该部分在TOPIQ之外,还考量了三个Consistency指标:CLIPSIM、LPIPS和SSIM;和三个Perception指标:CLIPIQA,LIQE和FID。靠前的指标优先考虑语义信息,而靠后的模型则侧重于底层视觉。
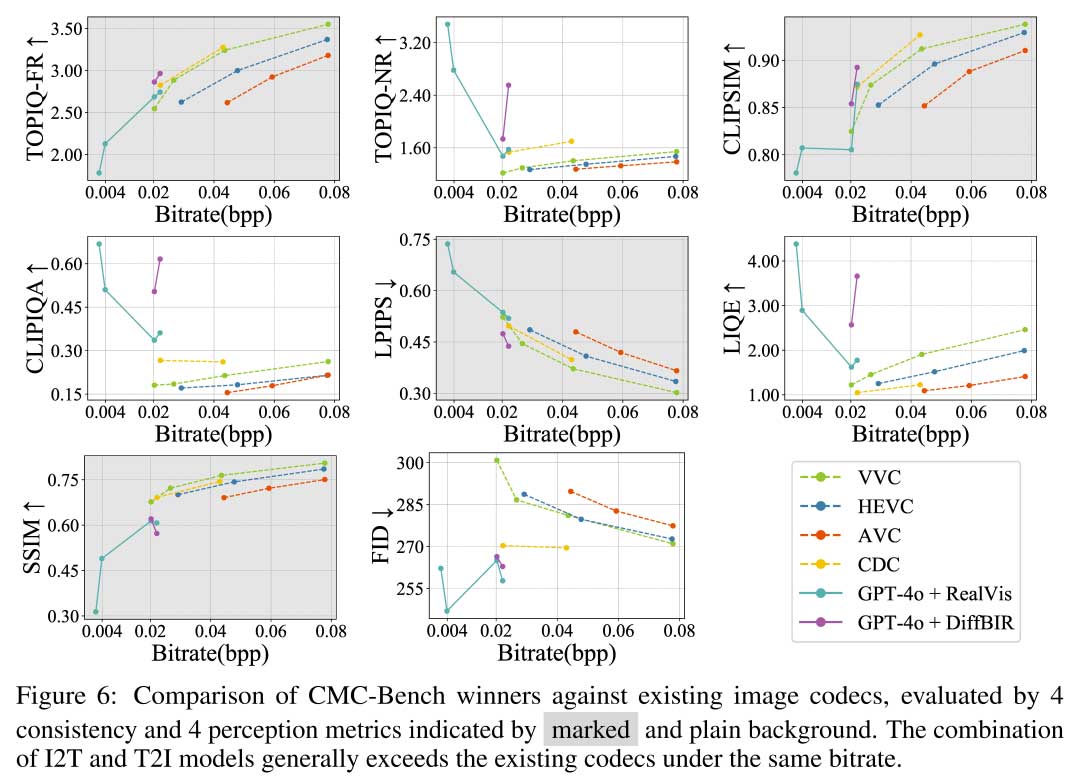
两种CMC范式都在大部分指标上实现了领先。Perception的优势最为显著,在极低比特率下大幅超越传统编解码器。然而Consistency的优势相对较小,与传统方法相比,比特率只节省了约30%。其中DiffBIR解码器表现出更好的性能,而RealVis的比特率范围更广泛。综上所述,本文认为CMC相对于传统编解码具有一定优势。但若想成为未来的通用标准,仍需要在以下几个方面进一步优化:
更先进的T2I模型: 编码器和解码器在CMC中都至关重要,但解码器更具决定性。未来的T2I模型应该拥有更复杂的控制机制,确保高质量的生成,同时保持与参考图像的一致性。
更好的SCI适配性: SCI内容的压缩效果远不如NSI和AIGI,LMM需要对图像中的字母、文本、甚至段落设计专门理解和生成机制。
更宽的比特率范围: 虽然在超低比特率上处于领先地位,但Consistency的领先幅度不如Perception指标。未来的工作应该集中在更高比特率的CMC上,结合更多的控制信息来重建原始图像,最终实现相对传统编码器在全部码率、全部维度上的优势。
总结
CMC-Bench是一个评估I2T和T2I模型在图像压缩中的协同工作的性能基准。面对下一个十年的编解码发展趋势,CMC-Bench提出了LMM之间的四种协作模式,以及两个评估指标,共八个维度。通过6个I2T和12个T2I模型的组合,CMC-Bench收集了58,000张压缩失真图像和160,000条主观标注,以训练客观的质量评估指标。结果表明,即使没有针对压缩任务的专门培训,部分先进的I2T和T2I模型组合,已经在多个方面超越了传统编解码器。然而,利用LMM作为编解码的新范式,还有很长的路要走。我们衷心希望I2T和T2I方向的LMM开发者共同参与此测试,以促进视觉信号编解码协议的演进。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
