
这篇文章提出了一种名为AVID(Any-Length Video Inpainting with Diffusion Model)的视频修复方法。AVID能够处理不同长度的视频,并在各种视频编辑任务中表现出色。视频修复,或称为视频填充(inpainting),是指在视频的给定遮罩区域内,根据文本提示或编辑指令,生成新的视频内容,同时保持未遮罩区域的原始视频内容不变。作者通过广泛的实验验证了AVID模型的有效性,并与现有的一些方法进行了比较,展示了其在不同视频修复任务中的优越性能。此外,文章还提供了一些定性的结果展示,以及对模型的效率、应用范围、比较分析、消融研究、局限性和潜在的改进方向的讨论。
文章链接:https://arxiv.org/abs/2312.03816
作者:Zhixing Zhang, Bichen Wu 等
项目地址:https://github.com/zhang-zx/AVID
内容整理:王寒
简介
本文介绍了一种在视频时长和任务范围内通用的视频修复方法。本文认为对用户而言最直接的视频编辑方法是在首帧给定mask并进行文字编辑。给定一个视频,一个初始帧的mask区域和一个编辑提示,该任务需要一个模型在每一帧按照编辑指导进行填充,同时保持mask外区域的完整性。难点有三:1)时域一致性 2)在不同的结构保真度水平下支持不同的修复类型 3)处理任意长度的视频
本文针对固定长度的视频编辑,本文的模型装备了高效的运动模块和可调节的结构指导。基于此,本文提出了具有中间帧注意力引导机制的Temporal MultiDiffusion采样流水线,以生成具有任意期望时长的视频。
模型细节
AVID在文字指导的图片inpainting框架基础上开发。结合了运动模块来保证编辑区域的时序一致性。结构指导模块使模型适应不同的结构保真度。以及一个zero-shot生成流水线,利用中间帧注意力指导机制来加强对任意长度视频的操控。
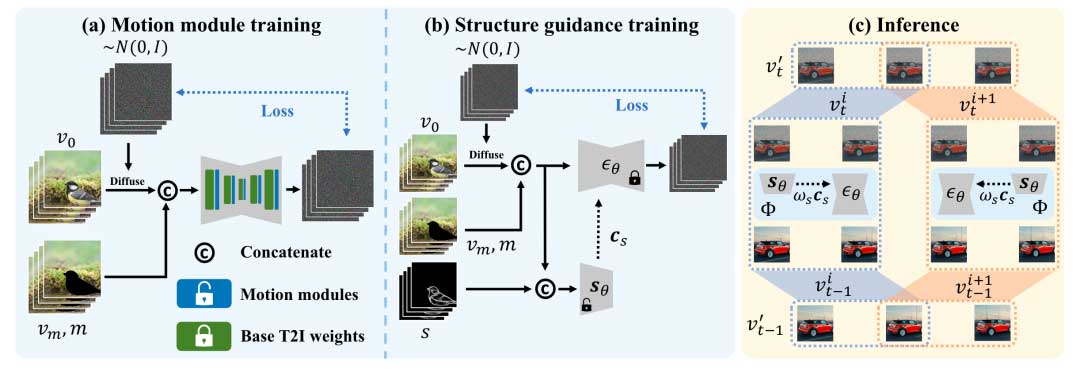

文字指导的视频补全
针对精确编辑任务,给定第一帧的mask,本文首先将这个mask扩展到视频的每一帧得到一个mask序列。对uncropping任务则为所有frame提供相同的mask。针对时域连续性问题,参考了AnimateDiff将2D卷积层扩展到pseudo-3D,并添加运动模块来学习帧间的关系:
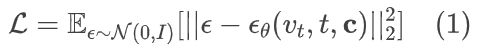
其中条件c包括未被mask遮掉的区域vm,mask和文本嵌入。训练过程中只优化运动模块从而保留原文生图模型的生成能力。
视频修复中的结构引导
考虑到inpainting任务包括各种类型的子任务,对结构保持的精确程度要求不一。一种常见的修复类型是对象互换,例如, “用MINI Cooper替换汽车” ;另一种类型是纹理映射(例如, “将叶子颜色从红色变为黄色” );还有uncropping的类型(例如”填充在上面和下面的区域”)也很受欢迎。不同的修复类型意味着不同的结构保真度。例如,如果是物体变换,比如编辑操作是将人变成雕像,mask区域中原来人物的动作和结构都应该被保持。与之相对的是视频uncropping需要填充空白区域以增加视野,而没有来自mask区域的引导信号。

纹理映射要求保存源视频的结构,例如,将人的外套的材料转换为皮革(如图所示)而uncropping任务不需要这么精确。作者因此设计了一个结构引导模块,参考ControlNet的设计,固定去噪网络参数来训练结构模块(图中的sθ)。使用一个结构提取器S为每一帧提取结构特征,提取到的结构特征Cs包含4种分辨率下的13个特征图,它们集成到去噪网络的skip connection和中间层的输入中。推理过程中提取器的中间层特征会有一个系数控制结构特征的强度。
针对长视频的Zero-shot推理
Temporal MultiDiffusion
理论上motion module能生成任意长度的视频,但是当生成长于训练视频的视频时会有严重退化现象。受MultiDiffusion的启发设计了Temporal MultiDiffusion。首先将长视频拆分成有混叠的切片,每一帧最后的结果是每个包含该帧切片得到的去噪结果的平均值。
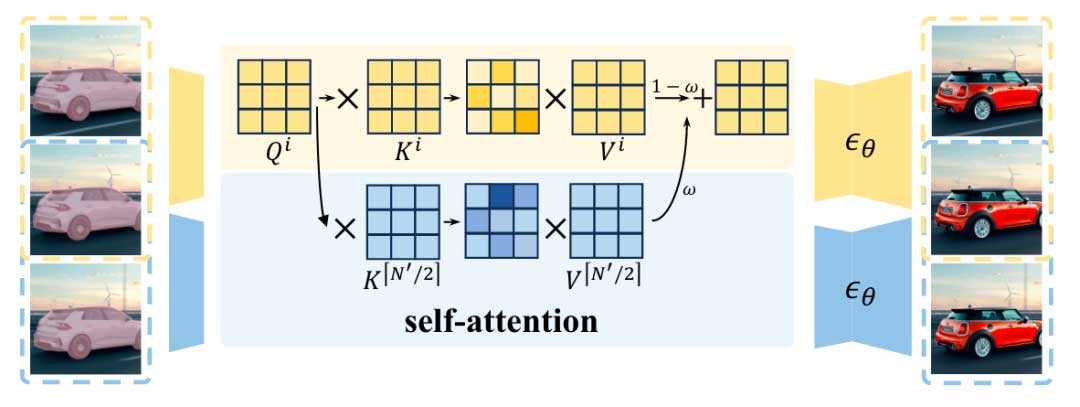
Middle-frame attention guidance
虽然Multi Diffusion能平滑长视频的输出,但是作者发现视频的主题会发生渐变,如下图ω = 0时所示。

为了解决这一问题,本文引入了中间帧注意力指导来确保每个切片中生成的主体连续。首先将2D的自注意力扩展到pseudo-3D自注意力,在每个自注意力层使用一个切片里的中间帧作为指导,如下图所示,控制强度由参数ω控制。
实验
细节
在预训练的LDM模型基础上进行。使用的数据集是去水印后的Shutterstock video dataset。Motion Module训练设置为16帧512×512分辨率随机mask。此外Unet的编码器被用作控制模块,使用相同数据集训练。使用HED在合成区域作为控制模块的指导信息,控制模块的所有参数都参与优化。
定性结果
AVID模型在不同时长的视频上进行了多种编辑类型的测试,包括物体替换、更新纹理和uncropping。实验结果表明,AVID能够在不改变周围内容的情况下,准确地修改指定区域,并保持生成内容在视频帧中的身份(如颜色、结构等)一致性。

AVID与其他几种基于扩散模型的视频修复技术进行了比较,包括逐帧修复技术(Per-frame inpainting)和VideoComposer。实验结果显示,AVID在保留细节、背景保持和时间一致性方面表现优于其他方法。
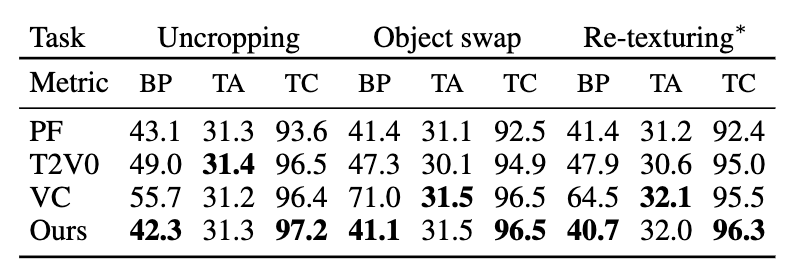
定量结果
使用三种自动评估指标对模型性能进行了量化:背景保持(Background Preservation)、文本-视频对齐(Text-Video Alignment)和时间一致性(Temporal Consistency)。AVID在这些指标上都展现出了优异的性能。
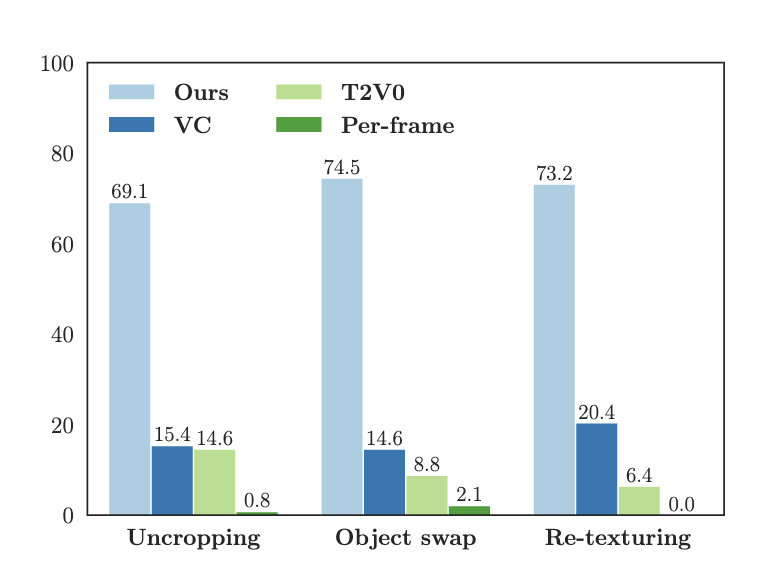
用户实验
消融实验
结构引导
展示了结构引导比例对视频编辑结果的影响,指出不同的编辑子任务需要不同的结构引导比例。

Temporal MultiDiffusion
探讨了时间多扩散采样管道在处理不同视频长度时的有效性。

中间帧注意力引导机制
研究了注意力引导机制在保持视频帧中身份一致性方面的作用。

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。